Clear Sky Science · ru
К более совершенной неконтролируемой кластеризации корейских картин XX века с помощью мультимодальных признаков
Видеть закономерности в корейском современном искусстве
А что если компьютер мог бы помочь нам понять, насколько художники похожи — или совершенно различны — просто глядя на их произведения? В этом исследовании используются методы искусственного интеллекта для анализа корейских картин XX века, выявляя скрытые закономерности в цвете, текстуре и стиле. Для посетителей музеев, любителей искусства и любопытных читателей это предлагает новый способ увидеть, насколько выразительны отдельные художники и как их работы тихо образуют семейства стилей, над которыми порой спорят даже эксперты.
Формирование тщательно подобранной коллекции произведений
Чтобы у компьютера было что-то содержательное для изучения, исследователи сперва собрали сфокусированную цифровую коллекцию: 1100 картин одиннадцати ведущих модерн и современных корейских художников — от мастеров тушевой пейзажной живописи до абстракционистов и реалистов. Каждый художник представил по 100 работ, в основном взятых из Национального музея современного и современного искусства (MMCA) и других проверенных учреждений и фондов. В коллекцию вошли ключевые фигуры — пионеры абстракции, реалисты повседневной жизни, новаторы тушевой техники и художники, объединяющие народные традиции с современной экспрессией. Их присутствие на знаковых национальных выставках, включая знаменитую коллекцию Ли Кун-хи, помогло обеспечить, что набор данных отражает ядро корейского искусства XX века, а не случайный набор изображений.
Перевод картин в числовые данные
Компьютеры не «видят» искусство так, как люди, поэтому команда перевела каждую картину в набор числовых признаков. Они зафиксировали базовую цветовую информацию двумя способами (RGB и HSV), измерили тонкие текстурные паттерны с помощью метода матрицы совместной встречаемости уровней серого (gray-level co-occurrence), и добавили мощный семантический снимок от предварительно обученной модели «зрение—язык» CLIP. CLIP изначально обучался на огромном числе пар изображение–текст из интернета, поэтому он несет широкий, учитывающий язык взгляд на то, как выглядят изображения. Для каждой картины эти четыре потока — цвет, вариация цвета, текстура и семантическое впечатление — были нормализованы и затем объединены в единый, сбалансированный вектор признаков, создавая компактный, но насыщенный отпечаток визуального характера произведения.
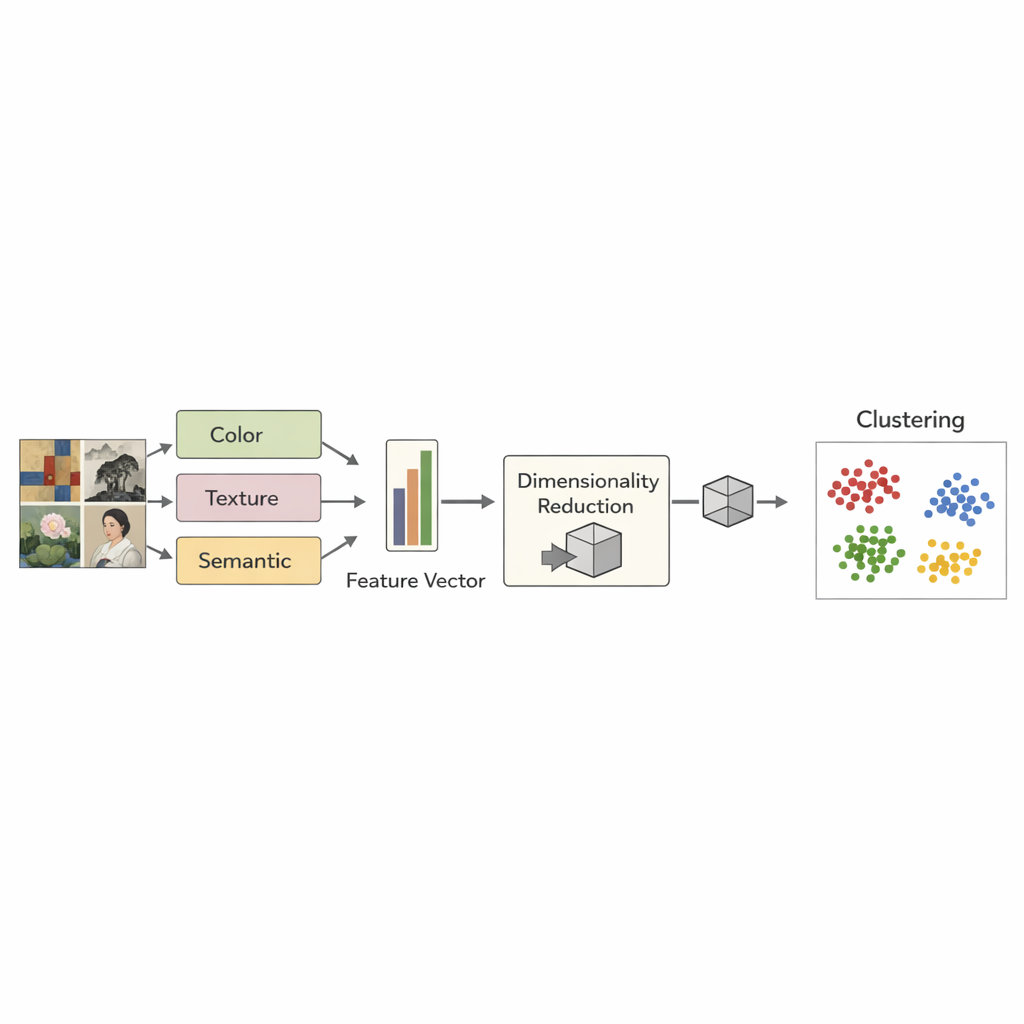
Позволить кластерам проявиться самостоятельно
Вместо того чтобы указывать компьютеру, какая картина принадлежит какому художнику при обучении, исследователи применили неконтролируемый подход: они попросили алгоритм самостоятельно сгруппировать похожие картины. Сначала метод t-SNE «сжал» высокоразмерные отпечатки до двух измерений, чтобы визуализировать общую структуру. Затем кластеризация K-means разделила картины на множество небольших групп, которые затем уточнялись, чтобы выделить наиболее значимые кластеры. Только после этого команда присвоили названия художников, используя простое правило большинства внутри каждой группы, чтобы проверить, насколько кластеры совпадают с реальным авторством. Лучшая версия метода — равномерное сочетание CLIP, цвета и текстуры — корректно сопоставляла картины с их авторами примерно в 82% случаев, превосходя варианты, полагавшиеся на один признак, например только на цвет или только на текстуру.
Что компьютер увидел в цвете и мазках
Результаты кластеризации были не просто числами; они породили узнаваемые визуальные истории. Когда команда нанесла кластеры на диаграмму, большинство художников образовали плотные, хорошо разделенные островки точек, каждый из которых был заполнен представительными работами с общими чертами: монохромные тушевые пейзажи с деликатной манерой мазка, смелые геометрические абстракции в основных цветах или спокойные натюрморты со стабильной композицией и повторяющимися текстурами. У художников, чья работа опирается на фирменную палитру — например яркие поля цвета или определенные тональные гармонии — простые цветовые признаки уже давали хороший результат. Для других, таких как мастера туши или экспрессионисты с драматичной манерой мазка, ключевыми были текстурные и семантические признаки. Ошибки классификации часто возникали там, где и человеческие эксперты затруднялись: абстракционисты с похожими композициями или художники с общими текучими линиями и пересекающимися цветовыми предпочтениями. В таких случаях ошибки становились подсказками о реальных визуальных родствах между разными именами.

От данных к более глубокому пониманию искусства
Для неспециалистов главный вывод заключается в том, что компьютер, анализируя только цифровые изображения, мог восстановить многое из того, что искусствоведы уже знают о том, кто что написал — и даже указать на неожиданные связи. Сочетая цвет, текстуру и извлеченные семантические впечатления, метод предлагает воспроизводимый, объективный способ группировки и сравнения работ современных корейских художников. Он не заменяет человеческое суждение или богатый культурный контекст, который привносят эксперты, но предоставляет количественную карту, которая может направить взгляд к кластерам, пограничным зонам и визуальным «родственникам», заслуживающим более внимательного рассмотрения. Таким образом машинное обучение становится новым спутником кураторов и зрителей, помогая им ориентироваться в больших коллекциях и открывать, как многие голоса корейского модерна переплетаются в сложный, но поддающийся анализу визуальный ландшафт.
Цитирование: Baek, S., Park, SJ., Park, SE. et al. Toward enhanced unsupervised clustering of 20th century Korean paintings via multimodal features. npj Herit. Sci. 14, 76 (2026). https://doi.org/10.1038/s40494-026-02304-1
Ключевые слова: корейское современное искусство, искусственный интеллект, анализ стиля живописи, кластеризация изображений, цифровая история искусства