Clear Sky Science · pt
Avaliação sistemática e diretrizes para o modelo Segment Anything na análise de vídeos cirúrgicos
Por que ferramentas inteligentes de vídeo importam na sala de cirurgia
A cirurgia moderna é cada vez mais orientada por vídeo: pequenas câmeras observam o interior do corpo enquanto os cirurgiões manipulam instrumentos delicados na tela. Converter esses vídeos ricos, porém bagunçados, em mapas claros e rotulados de instrumentos e tecidos pode tornar as operações mais seguras, o treinamento mais eficaz e a futura assistência robótica mais confiável. Este estudo pega um poderoso novo sistema de visão de uso geral, originalmente treinado em vídeos do cotidiano, e faz uma pergunta simples, porém importante: ele consegue “ver” bem o suficiente dentro do corpo humano para ser útil em cirurgias reais — sem ser re-treinado do zero em dados médicos caros? 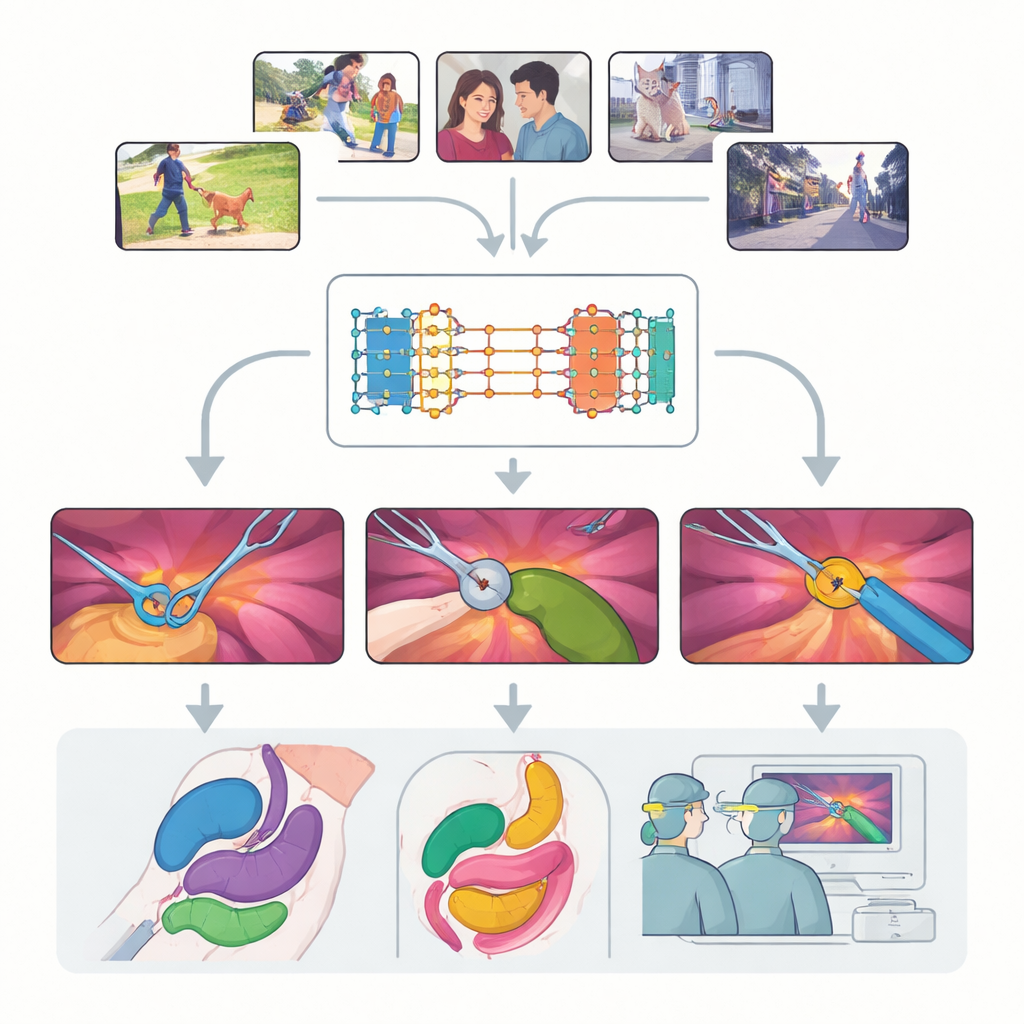
Uma ferramenta de visão flexível construída para qualquer cena
O trabalho centra-se no Segment Anything Model 2 (SAM2), um grande sistema de IA projetado para identificar objetos em vídeos sempre que recebe uma dica, ou “prompt”, sobre o que procurar. Ao contrário de modelos tradicionais que aprendem categorias fixas, o SAM2 é agnóstico a classes: ele não se importa se um objeto é um cachorro, um carro ou um pinça cirúrgica, desde que o usuário aponte para ele com um ponto, uma caixa ou uma máscara de exemplo. Um avanço chave no SAM2 é seu banco de memória, que lembra como um objeto parecia em quadros anteriores e usa essa memória para segui-lo ao longo do tempo. Isso torna o SAM2 particularmente promissor para vídeos cirúrgicos, onde instrumentos entram e saem de vista e os tecidos se deformam constantemente.
Colocando o modelo à prova em muitas cirurgias
Os autores conduzem uma avaliação sistemática em grande escala do SAM2 em nove conjuntos de dados diversos cobrindo dezessete tipos de procedimentos, desde colecistectomia laparoscópica até cirurgia robótica de próstata e endoscopia. Eles examinam três desafios principais: rastreamento de instrumentos, segmentação de múltiplos órgãos e compreensão de cenas que misturam ferramentas e tecidos. Para cada caso, testam diferentes formas de fornecer prompts ao modelo — pontos únicos, múltiplos pontos, caixas delimitadoras e máscaras completas — e exploram com que frequência os prompts precisam ser atualizados à medida que o vídeo avança. Também comparam o modelo pronto para uso com diversas formas de re-treinamento leve em imagens cirúrgicas para ver até que ponto o desempenho pode ser melhorado sem precisar de grandes novos conjuntos de dados.
O que funciona melhor dentro do corpo
No geral, o SAM2 prova ser surpreendentemente robusto nesse ambiente desconhecido. Sem re-treinamento cirúrgico, ele já segmenta instrumentos e muitos órgãos de forma competitiva em comparação com modelos médicos especializados, especialmente quando recebe prompts ricos, como caixas delimitadoras ou máscaras. Re-inicializar periodicamente os prompts a cada 30 quadros — essencialmente lembrando ao sistema o que está onde — melhora muito o rastreamento em clipes longos e complexos. Quando os pesquisadores afinam apenas partes específicas do SAM2, como o módulo que converte prompts em máscaras, a precisão em cenas multi-órgão aumenta significativamente mantendo as exigências de treinamento moderadas. Em contraste, tentar ajustar todo o codificador de imagem com dados cirúrgicos limitados pode, na verdade, prejudicar o desempenho, sugerindo que a maior parte do conhecimento visual geral do SAM2 deve permanecer intacta. 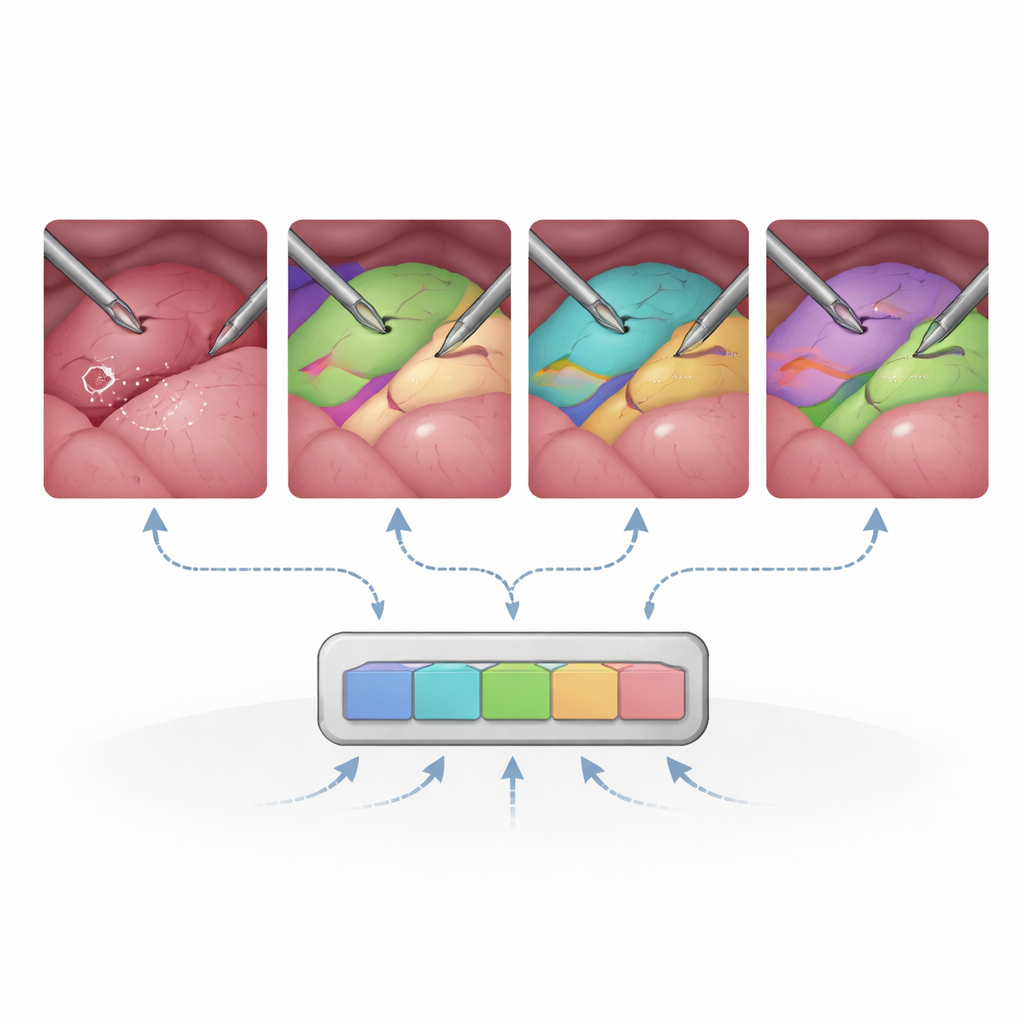
Limites em cenas confusas e de mudanças rápidas
O estudo também revela pontos fracos claros. O SAM2 tem dificuldade quando o campo de visão é estreito, a imagem é ruidosa ou mal iluminada, ou quando os tecidos não apresentam contornos nítidos, como em alguns procedimentos endoscópicos. Estruturas finas e ramificadas, como vasos sanguíneos e ductos, são difíceis de separar quando se sobrepõem ou compartilham contornos semelhantes. Usar a memória de vídeo nem sempre ajuda: em cenas altamente dinâmicas com movimento rápido da câmera, as pistas temporais podem induzir o modelo ao erro em vez de estabilizá-lo. Essas descobertas ressaltam que, embora um modelo de base geral possa ir longe, certas realidades cirúrgicas continuam a exigir ajustes específicos do domínio e melhor tratamento de movimento e mudanças de aparência.
Diretrizes para futuros sistemas cirúrgicos inteligentes
Da extensa testagem, os autores destilam conselhos práticos para pesquisadores e clínicos que queiram usar o SAM2 em projetos cirúrgicos. Eles recomendam começar com prompts do tipo máscara ou caixa e afinar de forma simples, baseada em imagem, focando no decodificador de máscaras, adicionar atualizações periódicas de prompts para vídeos longos e só explorar treinamentos mais complexos baseados em vídeo quando as cenas forem relativamente estáveis. Mostram que clipes com rótulos esparsos — apenas alguns quadros anotados — podem ser suficientes para adaptar o modelo de forma eficaz. Em termos claros, a conclusão é encorajadora: um único modelo de visão amplamente treinado pode lidar com muitas tarefas diferentes de segmentação cirúrgica, reduzindo drasticamente a necessidade de construir uma nova ferramenta para cada procedimento. Com prompting cuidadoso e personalização leve, sistemas como o SAM2 podem se tornar blocos de construção poderosos para a próxima geração de navegação, automação e ferramentas de treinamento cirúrgico.
Citação: Yuan, C., Jiang, J., Yang, K. et al. Systematic evaluation and guidelines for segment anything model in surgical video analysis. npj Digit. Surg. 1, 2 (2026). https://doi.org/10.1038/s44484-025-00002-2
Palavras-chave: análise de vídeo cirúrgico, segmentação de imagem, modelos de base, cirurgia assistida por computador, IA médica