Clear Sky Science · pt
Detectando linguagem estigmatizante em prontuários clínicos com modelos de linguagem grandes para atendimento de dependência
Por que as palavras no seu prontuário médico importam
À medida que mais pacientes passam a ter acesso online aos seus prontuários, a linguagem usada pelos clínicos deixa de ficar escondida nos computadores do hospital—ela fica visível para as próprias pessoas sobre as quais se escreve. Para pacientes com dependência, uma única expressão como “usuário de drogas” pode reforçar a vergonha, prejudicar a confiança e até influenciar o atendimento que recebem. Este estudo faz uma pergunta atual: a inteligência artificial moderna pode ajudar hospitais a identificar e reduzir linguagem estigmatizante em notas clínicas antes que ela prejudique os pacientes?

Rótulos prejudiciais escondidos em notas do dia a dia
O estigma na saúde não aparece apenas no contato visual ou no tom de voz; ele também está enraizado no registro escrito. Registros eletrônicos de saúde contêm milhões de notas que acompanham pacientes por clínicas e hospitais. Termos como “abuso de álcool” ou “comportamento em busca de drogas” podem moldar a visão de clínicos futuros sobre uma pessoa muito tempo depois de uma visita de emergência ou internação. Os pesquisadores se concentraram em notas de unidades de terapia intensiva sobre pacientes com problemas de uso de substâncias, onde os riscos são altos e a documentação é extensa. Partiram de diretrizes nacionais que incentivam linguagem respeitosa e centrada na pessoa, como “pessoa com transtorno por uso de substâncias” em vez de “viciado”, e usaram essas ideias para criar um grande conjunto de dados de notas rotuladas como estigmatizantes ou não.
Ensinando uma IA a ler nas entrelinhas
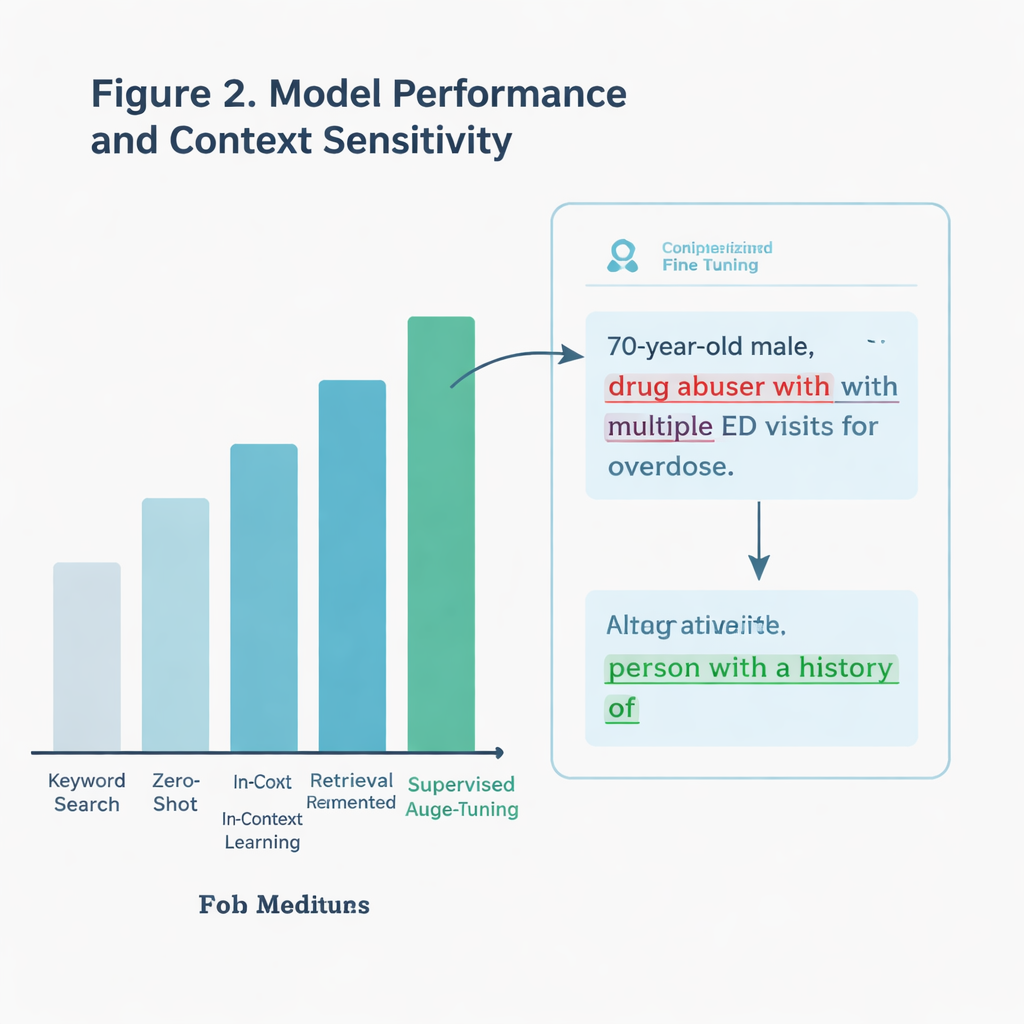
Em vez de simplesmente procurar palavras proibidas, a equipe quis um sistema de IA capaz de entender o contexto. Por exemplo, uma nota pode citar um paciente descrevendo-se como “bêbado”, o que não é o mesmo que um clínico aplicando esse rótulo. Os autores compararam várias abordagens, todas baseadas em um grande modelo de linguagem (um tipo de IA que processa e gera texto). Um método básico procurava apenas palavras-chave específicas extraídas das diretrizes. Métodos mais avançados pediam ao modelo que julgasse cada nota diretamente, seja sem exemplos adicionais, com orientação das diretrizes de comunicação, ou após ser especialmente treinado—ou “ajustado finamente”—em milhares de notas de UTI rotuladas.
O que funcionou melhor na prática
O modelo ajustado finamente foi o vencedor claro. Em um conjunto de teste mantido separado com mais de 11.000 notas, ele identificou corretamente linguagem estigmatizante cerca de 97% das vezes, muito melhor do que uma busca simples por palavras-chave. Também teve desempenho superior em um subconjunto particularmente difícil de notas que continham termos potencialmente carregados, mas nem sempre usados de forma prejudicial. O modelo conseguiu distinguir entre frases genuinamente julgadoras e usos neutros ou citados, onde uma busca tosca falharia. Quando a equipe testou o sistema em notas de outro sistema de saúde—quase 300.000 notas de UTI escritas em outro estado—ele ainda superou a abordagem por palavras-chave, mesmo que a linguagem estigmatizante fosse rara nessa amostra do mundo real.
Encontrando novas frases problemáticas que clínicos não perceberam
Os pesquisadores foram além e pediram à IA que explicasse por que havia sinalizado certas notas. Um especialista em dependência então revisou essas explicações. Em dezenas de casos, os modelos destacaram linguagem genuinamente estigmatizante que os anotadores humanos haviam inicialmente deixado passar, incluindo frases não listadas nas diretrizes existentes. Exemplos incluíam descrições como “comportamento em busca de drogas” ou menções casuais a “cirrose alcoólica” que imputam sutilmente culpa à pessoa em vez da doença. Isso sugere que ferramentas de IA bem projetadas podem não apenas aplicar as melhores práticas atuais, mas também ajudar a ampliar nossa compreensão do que constitui linguagem prejudicial à medida que a escrita clínica evolui.
De ferramenta de pesquisa a auxiliar à beira do leito
O estudo também considerou questões práticas. A busca por palavras-chave é extremamente rápida, mas superficial. O modelo de IA mais preciso exigiu várias horas de treinamento em processadores gráficos poderosos, mas, uma vez treinado, podia analisar notas em poucos segundos cada—lento para um motor de busca, mas aceitável para um assistente em segundo plano num sistema hospitalar. Outra abordagem, menos personalizada e que dependia apenas de prompts cuidadosos, teve desempenho razoável sem treinamento adicional, indicando opções mais leves para clínicas com menos recursos técnicos. Juntas, essas descobertas apontam para sistemas que podem sinalizar termos de risco em tempo real e sugerir alternativas mais respeitosas enquanto os clínicos digitam.
Um passo rumo a um cuidado mais respeitoso
Para o público em geral, a conclusão principal é simples: as palavras no seu prontuário não são apenas jargão técnico; elas ajudam a moldar como você é tratado. Este trabalho mostra que modelos de linguagem grandes podem detectar com confiabilidade muitas formas de linguagem estigmatizante relacionadas à dependência em notas de terapia intensiva, mesmo quando o problema é sutil. Embora nenhum sistema seja perfeito, tais ferramentas podem funcionar como editores sempre ativos, orientando clínicos para uma linguagem que reconheça as pessoas além dos seus diagnósticos. A longo prazo, essa mudança—da culpa ao respeito—pode ser tão importante para a cura quanto qualquer medicamento ou dispositivo.
Citação: Sethi, R., Caskey, J., Gao, Y. et al. Detecting stigmatizing language in clinical notes with large language models for addiction care. npj Health Syst. 3, 15 (2026). https://doi.org/10.1038/s44401-026-00069-0
Palavras-chave: estigma na dependência, prontuários clínicos, modelos de linguagem grandes, registros eletrônicos de saúde, linguagem centrada na pessoa