Clear Sky Science · pt
Espelho Mágico 3D: reconstrução de roupas a partir de uma única imagem via uma perspectiva causal
Provar roupas sem o provador
Imagine tirar uma única foto de corpo inteiro com seu celular e ver instantaneamente a si mesmo em 3D, podendo girar a imagem, mudar pontos de vista ou até trocar roupas com um amigo. Este artigo aborda o problema técnico central por trás desse “Espelho Mágico 3D”: transformar uma foto 2D comum de uma pessoa vestida em um modelo 3D detalhado de suas roupas, sem depender de scans 3D caros ou fotos em estúdio controlado.
Por que transformar fotos 2D em 3D é tão difícil
Transformar uma imagem plana em um objeto 3D é um enigma clássico. Sistemas existentes frequentemente começam a partir de um template corporal digital fixo e o deformam para corresponder à foto. Isso funciona razoavelmente bem para partes do corpo rígidas, como braços e pernas, mas falha para vestidos fluidos, casacos drapeados, cabelo ou bolsas, que não seguem uma forma simples e padrão. Outro obstáculo é os dados: há milhões de fotos de moda na web, mas quase nenhuma coleção grande de roupas 3D precisamente medidas para treino. Finalmente, uma única foto oculta informações importantes. Um casaco pequeno próximo à câmera pode parecer idêntico a um maior mais distante, e iluminação e padrões do tecido também podem confundir um algoritmo de aprendizado. Essas ambiguidades dificultam que uma rede neural “adivinhe” a estrutura 3D correta.
Ensinar a IA a separar causa e efeito
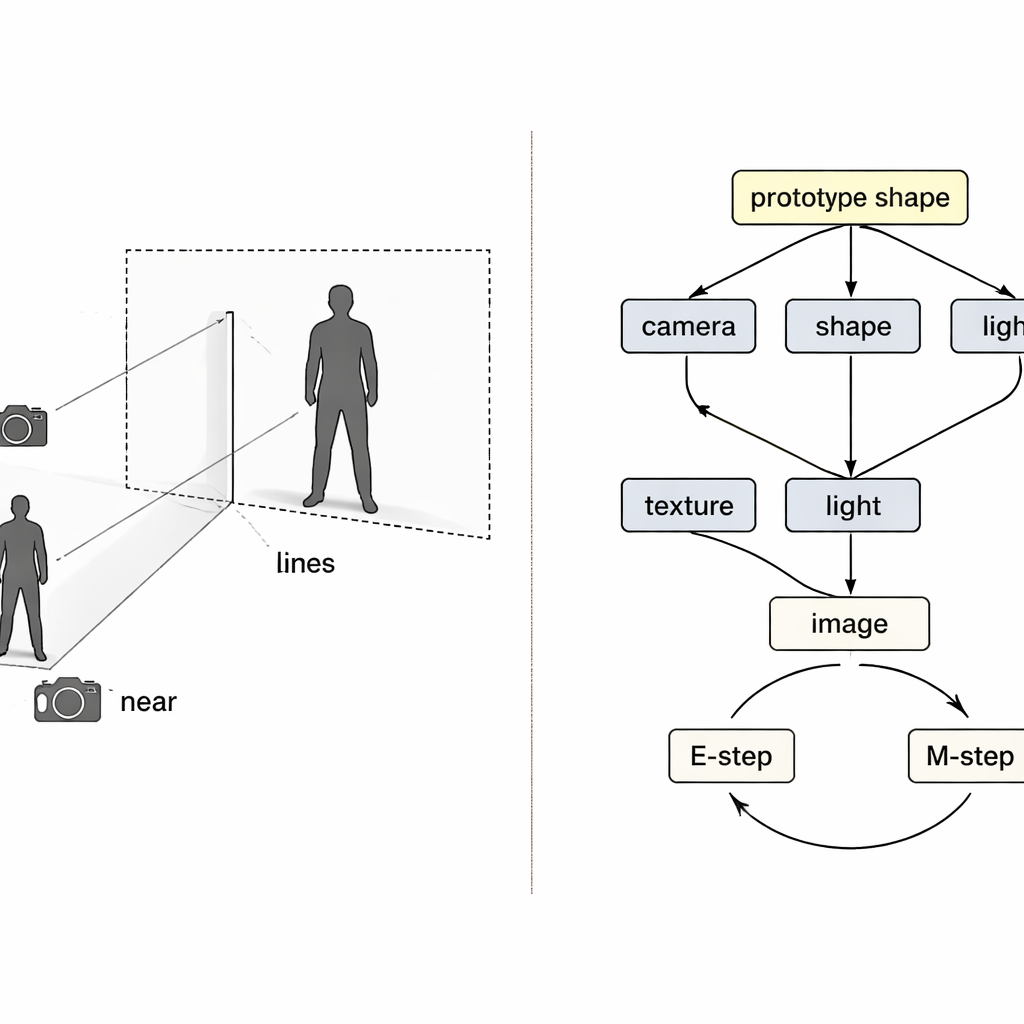
Em vez de tratar o problema como uma caixa-preta que mapeia pixels para 3D, os autores emprestam ideias do raciocínio causal — a matemática de causa e efeito. Eles veem a imagem final como o resultado de quatro causas ocultas: posição da câmera, formato da roupa, sua textura (cores e padrões) e como ela é iluminada. Um “mapa causal estrutural” especial descreve como esses fatores se combinam para produzir a imagem observada. Guiado por esse mapa, o sistema usa quatro codificadores neurais separados, cada um responsável por um fator. Junto com um renderizador 3D inspirado na física, eles formam um ciclo: imagem e máscara de primeiro plano entram, uma malha 3D colorida sai, e então ela é projetada de volta para uma imagem que pode ser comparada com a original.
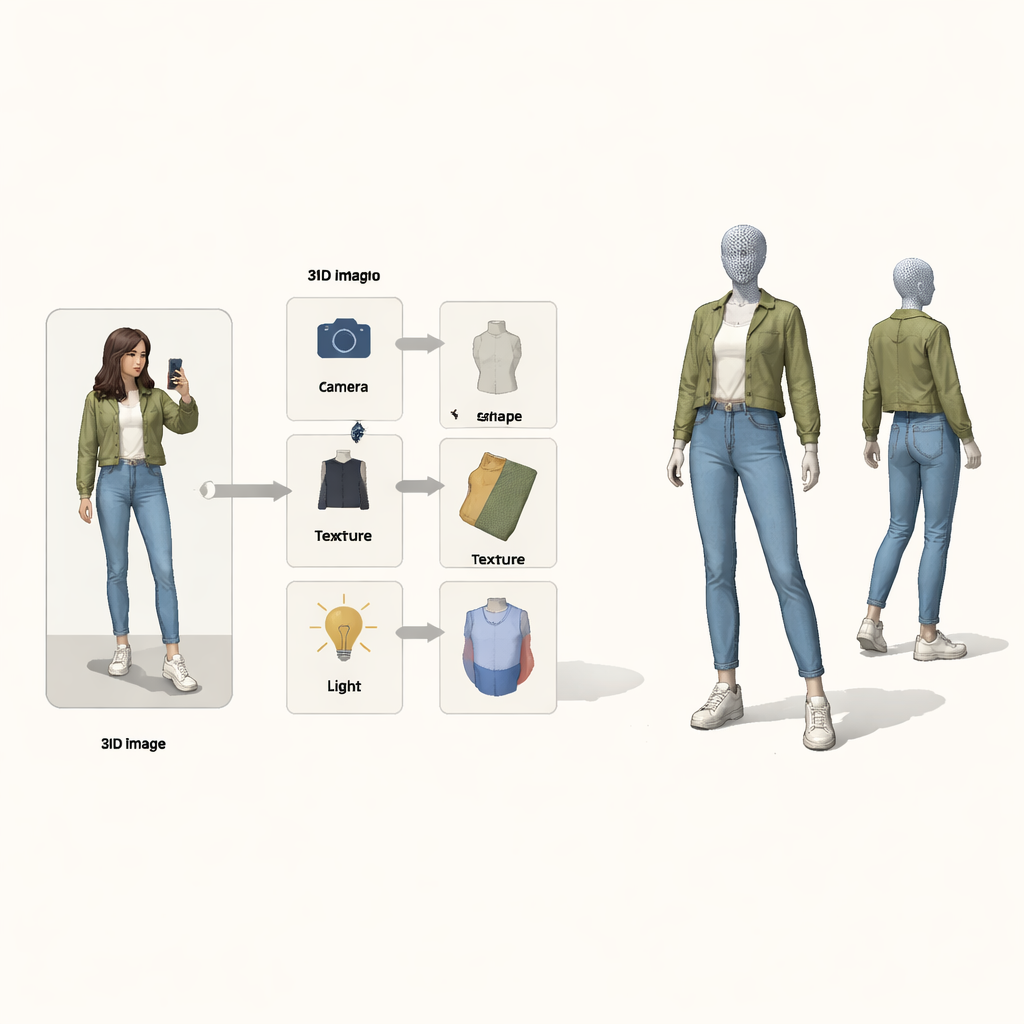
Um ciclo de aprendizado que corrige uma coisa de cada vez
Mesmo com codificadores separados, o treinamento pode dar errado. Se a reconstrução for imperfeita, fica incerto qual codificador é o culpado, e o aprendizado comum tende a ajustar todos ao mesmo tempo. Os autores tratam isso como um problema clássico de “colisor” na causalidade, onde diferentes causas podem compensar-se incorretamente. A solução é entrelaçar dois loops de expectativa–maximização no treinamento. No primeiro loop, três codificadores são temporariamente congelados enquanto apenas o quarto é atualizado, de modo que os erros são claramente atribuídos e esse componente aprende um papel mais limpo. No segundo loop, uma forma 3D “protótipo” compartilhada — começando como uma esfera simples — é lentamente atualizada para se tornar a forma média humana ou de pássaro nos dados. Exemplos individuais aprendem apenas pequenas diferenças em relação a esse protótipo, enquanto o módulo de câmera assume total responsabilidade por quão grande ou próximo o objeto parece, atacando diretamente a confusão entre tamanho e distância.
De fotos de moda a pássaros, e além
Para testar sua abordagem, os pesquisadores treinam em dois grandes conjuntos de dados de moda contendo fotos de rua ordinárias e em uma coleção padrão de imagens de pássaros. Importante: eles usam apenas máscaras 2D de primeiro plano, não malhas 3D de referência. Em roupas humanas, seu sistema supera métodos populares baseados em templates corporais ao corresponder o contorno real das peças e lida com elementos não rígidos como cabelo e bolsas de forma mais fiel. Em pássaros, alcança ou excede a qualidade dos principais métodos de reconstrução 3D a partir de imagem única enquanto produz pontos de vista novos mais realistas. Os modelos 3D são flexíveis o suficiente para suportar aplicações lúdicas, como trocar texturas de roupas entre pessoas ou gerar dados sintéticos de treinamento para impulsionar sistemas de reidentificação de pessoas usados em pesquisas de vigilância.
O que isso significa para os mundos digitais do dia a dia
Para não especialistas, a mensagem principal é que avatares 3D convincentes e ferramentas de provador virtual não exigem mais scanners 3D caros ou templates rígidos. Ao modelar explicitamente causa e efeito — separando câmera, forma, textura e luz, e vinculando-os a um protótipo compartilhado — os autores mostram como um sistema pode “explicar” uma única foto como uma cena 3D. Embora o método ainda tenha dificuldades com vistas que nunca viu, como as costas de uma pessoa fotografada apenas de frente, ele representa um passo significativo em direção a Espelhos Mágicos 3D práticos que funcionem nas imagens desordenadas e em contexto real que realmente tiramos.
Citação: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Palavras-chave: experimentação virtual de roupas, reconstrução 3D, aprendizado causal, visão computacional, IA para moda