Clear Sky Science · pt
O papel dos grandes modelos de linguagem no atendimento de emergência: um estudo abrangente de benchmarking
Por que isso importa para quem pode precisar ir ao pronto-socorro
As salas de emergência estão mais movimentadas do que nunca, com tempos de espera maiores e menos profissionais para cuidar de um número crescente de pacientes criticamente doentes. Este estudo investiga uma questão que afeta quase todo mundo: sistemas modernos de IA, conhecidos como grandes modelos de linguagem, podem ajudar médicos e enfermeiros a trabalhar de forma mais rápida e inteligente no departamento de emergência com segurança? Ao submeter várias IAs de ponta a uma série de testes médicos e casos simulados de pronto-socorro, os pesquisadores exploram quão próximos esses recursos estão de se tornarem “co-pilotos” confiáveis no atendimento urgente.
Prontos-socorros sob forte pressão
O artigo começa descrevendo uma crise crescente no atendimento de emergência, especialmente nos Estados Unidos. O envelhecimento da população e o aumento das doenças crônicas estão levando a números recordes de visitas ao pronto-socorro, chegando a aproximadamente 155 milhões em 2022. Ao mesmo tempo, os hospitais enfrentam escassez severa de enfermeiros e médicos, e o número de leitos por pessoa diminuiu nas últimas décadas. Um sistema de saúde fragmentado torna mais difícil coordenar o cuidado, aumentando o risco de atrasos e erros. Nesse contexto, os autores argumentam que novas ferramentas são urgentemente necessárias para ajudar os clínicos a triagem de pacientes, tomar decisões rápidas e documentar o atendimento sem aumentar sua carga de trabalho.
Como os pesquisadores testaram a IA médica
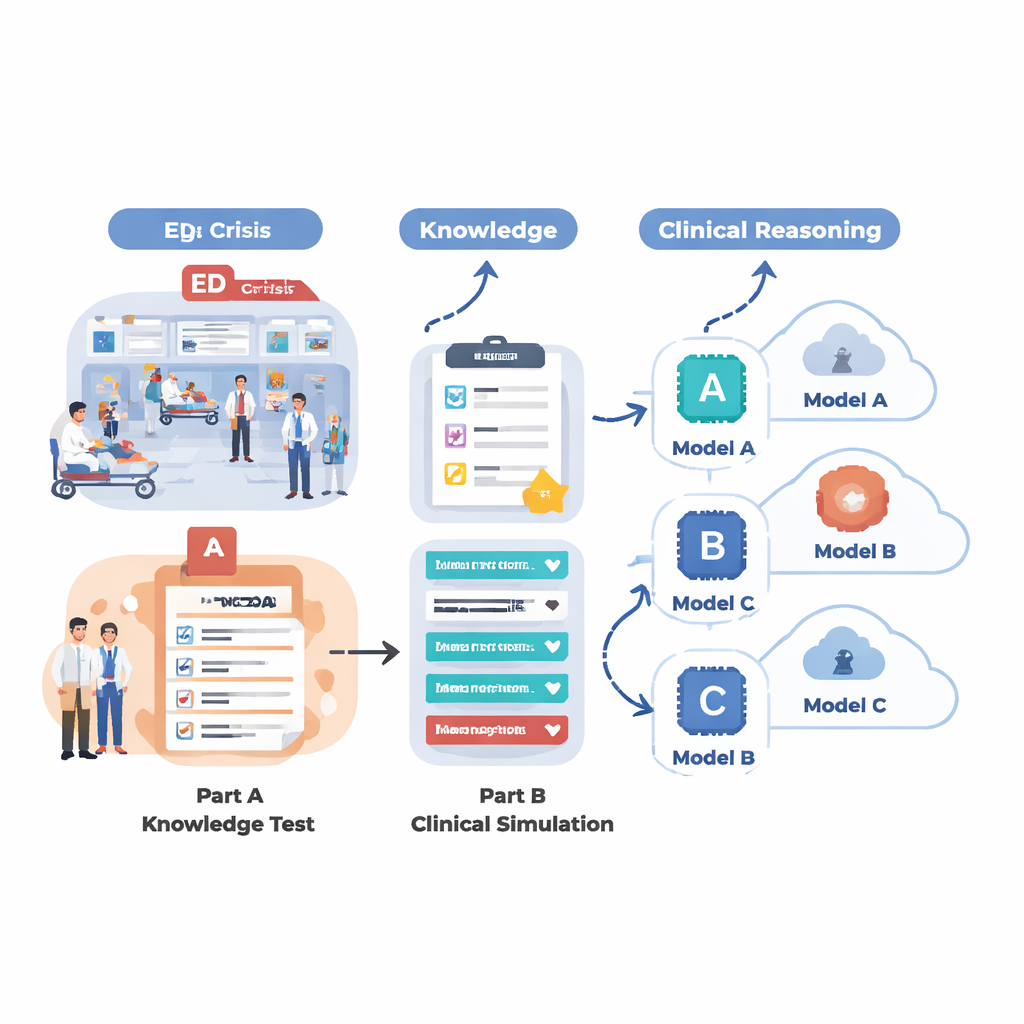
Para avaliar o que os sistemas de IA atuais realmente conseguem em um ambiente parecido com o do pronto-socorro, a equipe projetou uma avaliação em duas partes. Primeiro, testaram 18 modelos de linguagem diferentes em um grande conjunto de questões de múltipla escolha extraídas do MedMCQA, um conjunto de dados em estilo de exame médico cobrindo 12 queixas comuns no pronto-socorro, como dor torácica, falta de ar, cefaleia e dor abdominal. Essa fase mediu conhecimento médico básico: a IA conseguia escolher a resposta certa entre quatro opções em milhares de perguntas? Em seguida, os cinco modelos mais fortes dessa rodada foram solicitados a resolver 12 casos realistas de emergência, passo a passo, exatamente como um médico faria. Para cada caso, a IA teve que resumir o paciente, atribuir um escore de urgência de triagem, sugerir perguntas de seguimento essenciais, propor passos de manejo e listar diagnósticos prováveis à medida que novas informações (sinais vitais, história, achados do exame, resultados laboratoriais e de imagem) eram gradualmente reveladas.
Quais modelos de IA sabiam os fatos — e quais sabiam raciocinar
No quesito recordação factual pura, vários modelos apresentaram desempenho impressionante. Um sistema especializado chamado LLaMA 4 Maverick obteve cerca de 91% de acurácia geral nas questões médicas, seguido de perto pelo LLaMA 3.1, GPT-4.5, GPT-5 e Claude 4. Esses modelos de ponta foram consistentemente fortes entre diferentes queixas principais, sugerindo que as IAs de fronteira podem estar se aproximando de um limite no conhecimento médico de estilo didático. Sistemas de nível médio ficaram bem atrás, com alguns marcando perto de 60% e apresentando dificuldades em áreas-chave, como cuidados de feridas e problemas respiratórios. Entretanto, quando a tarefa deixou de ser responder perguntas isoladas e passou a exigir raciocínio por meio de histórias de pacientes ricas e em evolução, as diferenças ficaram mais nítidas. Nessas simulações clínicas, o GPT-5 destacou-se claramente: produziu os resumos mais precisos e completos, fez as perguntas de seguimento mais úteis, recomendou próximos passos sensatos e seguros e ofereceu as listas mais rigorosas e bem ordenadas de diagnósticos possíveis.
Forças, fraquezas e preocupações de segurança
Clínicos avaliaram cuidadosamente a saída de cada IA quanto à precisão, relevância e segurança. O GPT-5 não só alcançou as pontuações mais altas no geral; foi também o único modelo cujo desempenho se manteve estável ou melhorou à medida que os casos se tornavam mais complexos, mantendo as alucinações e erros graves abaixo de cerca de 2%. Outros modelos mostraram padrões distintos de fragilidade. Alguns tendiam a negligenciar diagnósticos secundários ou a priorizar problemas menores acima de problemas perigosos. Outros tornaram-se excessivamente cautelosos ou vagos, ou fixaram-se rapidamente em um único diagnóstico. De modo geral, a maioria dos sistemas subestimou quão doentes os pacientes estavam ao atribuir níveis de triagem, um viés conservador que poderia atrasar cuidados urgentes se não for corrigido. Os achados destacam um ponto-chave: conhecer fatos médicos não é o mesmo que integrá-los de forma confiável em decisões seguras e passo a passo quando a informação é incompleta, confusa e mutável.

O que isso pode significar para visitas futuras ao pronto-socorro
Os autores concluem que, embora várias IAs modernas agora rivalizem entre si em conhecimento médico, o GPT-5 em particular demonstra um novo nível de habilidade de raciocínio que pode torná-lo útil como ferramenta de suporte à decisão em departamentos de emergência. Eles enfatizam que esses sistemas não estão prontos para substituir clínicos nem para agir por conta própria. Em vez disso, o papel promissor a curto prazo é como assistente supervisionado — ajudando enfermeiros de triagem a estimar a urgência, redigindo resumos de pacientes, sugerindo perguntas ou exames e verificando se diagnósticos graves foram considerados. O estudo também ressalta que são necessárias mais pesquisas em ambientes clínicos reais, com fortes salvaguardas de segurança e regras claras de uso. Para os pacientes, a mensagem é de otimismo cauteloso: a IA está melhorando em analisar problemas médicos, mas seu uso seguro no pronto-socorro dependerá de um desenho cuidadoso, supervisão e um foco contínuo em apoiar — e não substituir — o julgamento humano de médicos e enfermeiros.
Citação: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Palavras-chave: medicina de emergência, grandes modelos de linguagem, suporte à decisão clínica, triagem, benchmarking de IA médica