Clear Sky Science · pt
LIMO: annealer em memória de baixo consumo e primitiva de multiplicação de matrizes para computação de borda
Rotas mais inteligentes e chips mais enxutos
Todo dia, empresas enfrentam quebra-cabeças como encontrar a rota mais curta para um caminhão de entregas que visita milhares de paradas ou escanear imagens rapidamente para detectar rostos com uma câmera alimentada por bateria. Esses problemas sobrecarregam os computadores atuais, que transferem enormes quantidades de dados entre memória e processadores. Este artigo apresenta o LIMO, um novo tipo de bloco computacional de baixo consumo que mantém os dados no lugar enquanto resolve tarefas difíceis de planejamento de rotas e executa modelos de inteligência artificial (IA), tornando dispositivos de borda futuros mais rápidos e energeticamente eficientes.
Por que encontrar boas rotas é tão difícil
No centro deste trabalho está o famoso Problema do Caixeiro Viajante: dado um conjunto de cidades, encontrar o circuito mais curto que visita cada cidade uma vez e retorna ao ponto inicial. Para mapas pequenos, ferramentas matemáticas exatas podem achar a melhor solução. Mas à medida que o número de cidades cresce para dezenas de milhares, o número de circuitos possíveis explode e até computadores poderosos ficam sobrecarregados. Heurísticas como o annealing simulado conseguem explorar esse espaço vasto em busca de rotas boas, embora não perfeitas, aceitando ocasionalmente soluções intermediárias piores para evitar ficarem presas em ótimos locais. Contudo, abordagens padrão ainda exploram o espaço de busca de forma ineficiente para problemas muito grandes e desperdiçam tempo movendo dados entre memória e CPU, batendo na chamada “parede da memória”.
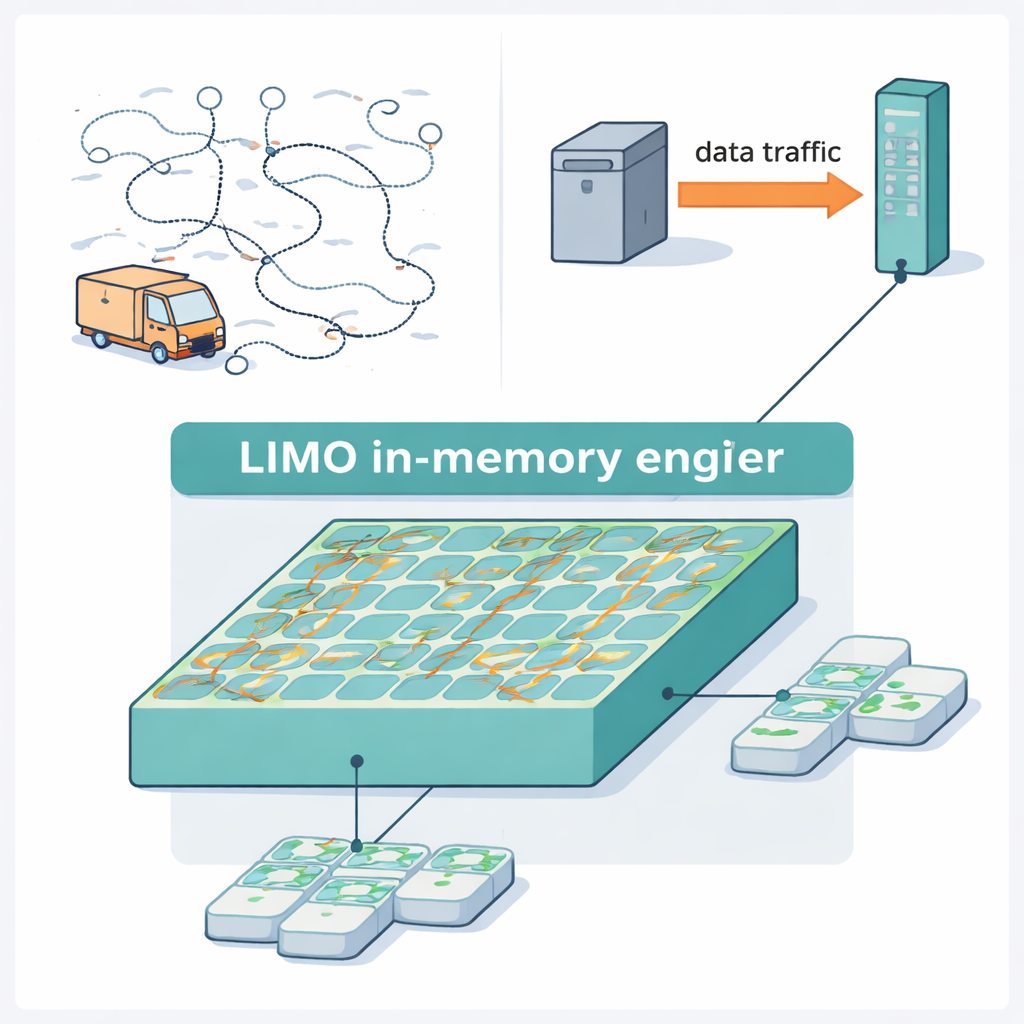
Uma nova forma de explorar as possibilidades
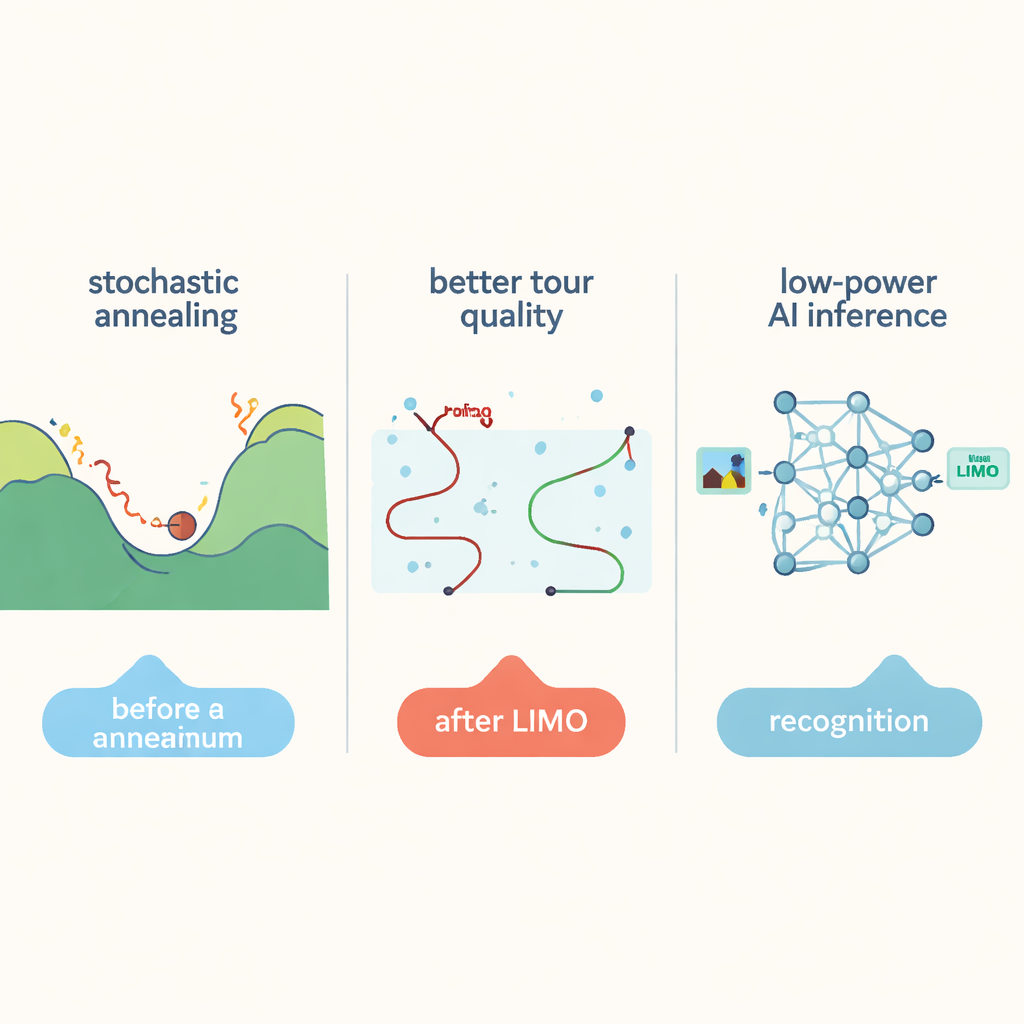
Os autores propõem um novo algoritmo chamado Inserção Anelada Ponderada por Significância (Significance Weighted Annealed Insertion - SWAI) que remodela como candidatos a rota são explorados. Em vez de trocar constantemente pares de cidades, o que escala mal conforme o número de cidades cresce, o SWAI constrói rotas passo a passo, inserindo uma cidade nova por vez. Em cada passo, ele às vezes escolhe a próxima cidade mais próxima (uma escolha gulosa) e às vezes recorre a aleatoriedade controlada que favorece arestas candidatas mais curtas sem excluir completamente as mais longas. Esse viés é ajustado ao longo do tempo, começando mais ousado e tornando-se mais conservador conforme a busca avança. Como cada passo examina opções de uma maneira que cresce apenas linearmente com o número de cidades, o algoritmo explora melhorias de longo alcance mais efetivamente do que o annealing simulado tradicional.
Computação dentro da memória com aleatoriedade incorporada
O LIMO transforma esse algoritmo em hardware ao co-projetar fortemente o circuito e o método de busca. No seu núcleo está uma matriz de memória modificada que armazena tanto a rota atual quanto as distâncias entre cidades, e executa as etapas-chave de atualização sem conversar constantemente com um processador separado. As escolhas aleatórias necessárias ao algoritmo vêm de pequenos dispositivos magnéticos chamados junções magnéticas de túnel por transferência de spin (spin-transfer-torque magnetic tunnel junctions), que naturalmente alternam seu estado de forma imprevisível quando acionadas com a corrente adequada. Os projetistas convertem essa aleatoriedade física em bits digitais e usam comparações simples para implementar as decisões probabilísticas do algoritmo. Como a maioria das operações permanece digital e ocorre diretamente dentro da memória, o sistema evita conversores volumosos e circuitos analógicos frágeis, economizando tanto energia quanto área.
Dividindo problemas grandes em partes
Para enfrentar tarefas de planejamento de rotas verdadeiramente grandes, com até 85.900 cidades, o sistema usa uma estratégia de dividir e conquistar. Um método geométrico leve agrupa cidades próximas em clusters até que cada cluster seja pequeno o suficiente para caber em um único bloco LIMO. O hardware resolve muitas dessas subrotas em paralelo e depois as costura de volta em uma rota completa. Passos adicionais de refinamento polêm a rota global: trechos da rota são re-otimizados pelo hardware e uma clássica limpeza “2-opt” em um processador convencional remove cruzamentos restantes. Em testes com benchmarks padrão, essa abordagem combinada produziu rotas de qualidade superior às de máquinas de annealing especializadas anteriores, alcançando respostas até cerca de cinco vezes mais rápidas nos maiores problemas.
De rotas difíceis a IA eficiente
O LIMO não se limita ao planejamento de rotas. A mesma matriz de memória também pode atuar como bloco de construção para redes neurais ao realizar multiplicações vetor–matriz, a operação central por trás do reconhecimento de imagens e padrões. Em vez de usar conversores precisos e consumidores de energia para ler sinais analógicos, o LIMO conta com circuitos de detecção muito simples que capturam apenas o sinal de sinalização (o sinal da soma) e compensa essa coarseza treinando as redes de forma consciente do hardware. Em tarefas de classificação de imagens e detecção de faces, essas redes alcançaram acurácia próxima à de modelos de software padrão, enquanto reduziram o consumo de energia e o tempo de resposta em comparação com chips convencionais de compute-in-memory. Para usuários do dia a dia, isso significa que câmeras, drones e outros dispositivos de borda poderão um dia resolver tarefas complexas de planejamento e executar modelos de IA por mais tempo com bateria, tudo graças a buscas mais inteligentes e à computação diretamente onde os dados residem.
Citação: Holla, A., Chatterjee, S., Sen, S. et al. LIMO: Low-power in-memory-annealer and matrix-multiplication primitive for edge computing. npj Unconv. Comput. 3, 10 (2026). https://doi.org/10.1038/s44335-026-00054-8
Palavras-chave: computação em memória, problema do caixeiro viajante, anelamento em hardware, IA de baixo consumo, computação de borda