Clear Sky Science · pt
Uma avaliação da incerteza estimativa em grandes modelos de linguagem
Por que palavras imprecisas sobre risco realmente importam
Quando um médico diz que um tratamento é “provável” de funcionar, ou um meteorologista alerta que há “pouca chance” de um furacão, confiamos nessas palavras vagas para tomar decisões concretas. Hoje, grandes modelos de linguagem (LLMs), como chatbots online, começam a usar o mesmo vocabulário. Este estudo faz uma pergunta simples, mas crucial: quando uma IA diz “provavelmente”, ela quer dizer a mesma coisa que nós — e ela consegue transformar números brutos em termos cotidianos de incerteza de forma confiável?
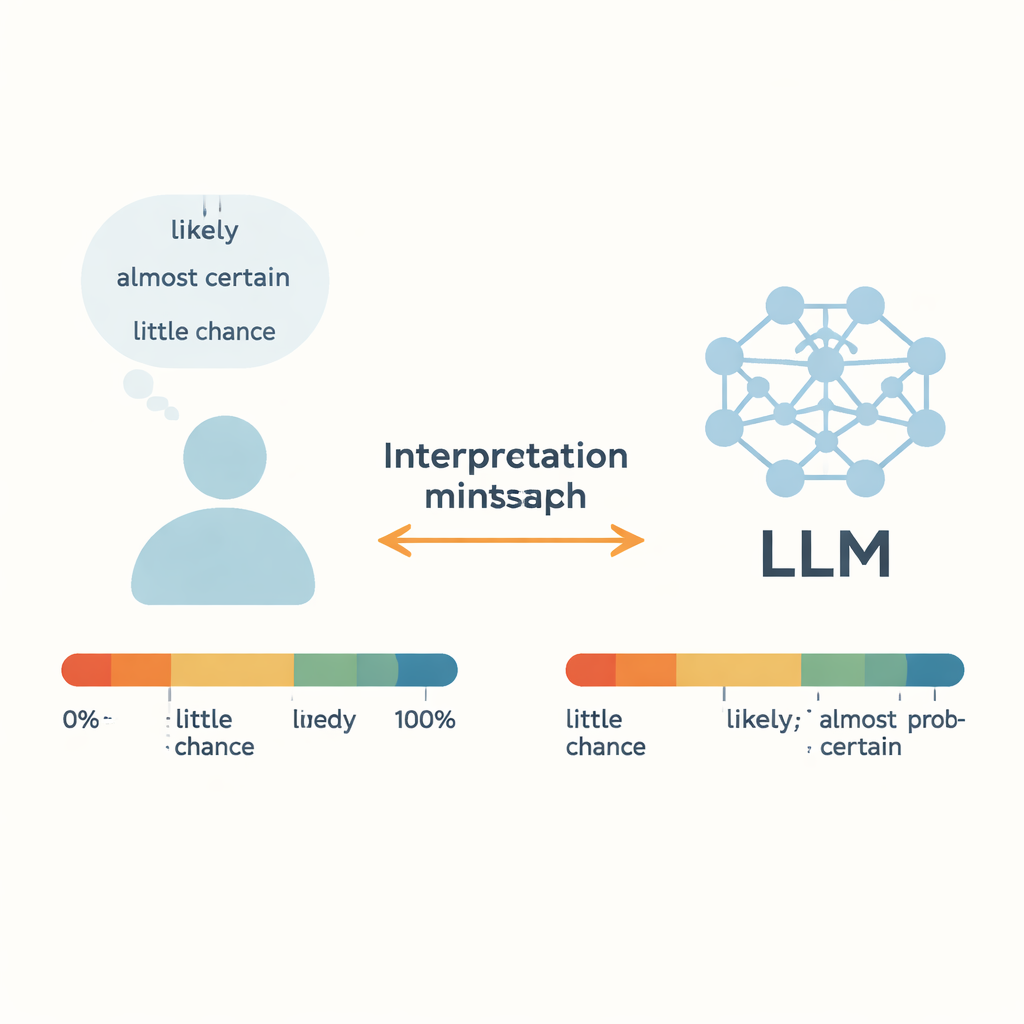
Examinando a incerteza do dia a dia
Os autores se concentram em “Palavras de Probabilidade Estimativa” (WEPs) — termos como “quase certo”, “provável” e “pouca chance” que as pessoas usam em vez de percentuais exatos. Trabalhos anteriores, remontando aos analistas de inteligência dos anos 1960, tentaram vincular essas palavras a probabilidades numéricas por meio de pesquisas com pessoas. Este estudo compara esses julgamentos humanos com a saída de cinco LLMs modernos, incluindo GPT-3.5, GPT-4, os modelos Llama da Meta e um sistema chinês chamado ERNIE-4.0. Para 17 palavras de incerteza comuns, cada modelo recebeu prompts em forma de pequenas histórias em inglês ou chinês e foi solicitado a responder com uma probabilidade numérica entre 0 e 100 por cento. Repetindo isso em muitos contextos, os autores construíram distribuições de probabilidade completas para cada palavra e cada modelo, e então as compararam com dados de pesquisas humanas.
Onde humanos e IAs falam a mesma língua
Para as expressões mais extremas — como “quase certo” no extremo alto e “quase nenhuma chance” no extremo baixo — LLMs e humanos coincidem surpreendentemente bem. Tanto pessoas quanto modelos tendem a agrupar essas frases em faixas de probabilidade estreitas, altas ou baixas, sugerindo que esses termos fortes têm significados relativamente estáveis entre contextos. O mesmo vale para “aproximadamente igual”, que a maioria dos humanos e dos modelos trata como uma chance de cerca de 50–50. Testes estatísticos mostram pouca diferença significativa entre as distribuições humanas e as dos modelos para essas palavras específicas, o que indica que os LLMs conseguem capturar casos claros de quase-certeza ou quase-impossibilidade com precisão semelhante à humana.
Onde os significados se afastam silenciosamente
Palavras ambíguas e de meio-termo contam outra história. Para expressões como “provável”, “provável que sim”, “duvidamos” e “pouca chance”, as interpretações numéricas dos modelos diferem significativamente dos julgamentos humanos. O GPT-4, apesar de ser mais capaz no geral do que o GPT-3.5, frequentemente mostra divergências maiores. Os autores sugerem que isso pode ocorrer porque tais palavras misturam duas coisas: uma noção de probabilidade e a atitude ou postura do falante. Em conversas reais, “provável” pode soar cauteloso ou confiante dependendo do tom e do contexto, e “duvidamos” pode expressar ceticismo em vez de uma probabilidade precisa. Treinados em um grande volume de textos de gêneros mistos da internet, os LLMs podem fazer uma média sobre muitos usos conflitantes, borrando essas sutilezas. O resultado é uma incompatibilidade oculta: humanos e IAs podem ver a mesma frase e atribuir silenciosamente números diferentes à mesma palavra.
Gênero, idioma e ecos culturais
Os pesquisadores também testaram como formulações com gênero e diferentes idiomas moldam essas palavras de probabilidade. Quando os prompts se referiam a “ele” ou “ela” em vez de sujeitos neutros, GPT-3.5 e GPT-4 frequentemente produziram estimativas de probabilidade menos variáveis, mais “fixas”, às vezes colapsando para um único ponto. Isso sugere que os modelos podem ter absorvido padrões rígidos de estereótipos presentes em seus dados de treinamento, embora as médias gerais para prompts masculinos e femininos fossem semelhantes. Ao comparar prompts em inglês e chinês, os modelos GPT mostraram mudanças notáveis em como interpretaram as mesmas palavras de incerteza. O ERNIE-4.0, treinado principalmente em texto chinês, ficou mais próximo dos falantes de chinês em muitos termos, mas ainda superestimou ou subestimou certas expressões. Essas descobertas destacam que a maneira como uma IA fala sobre incerteza depende não apenas da palavra escolhida, mas também do idioma e dos padrões culturais incorporados em seu treinamento.
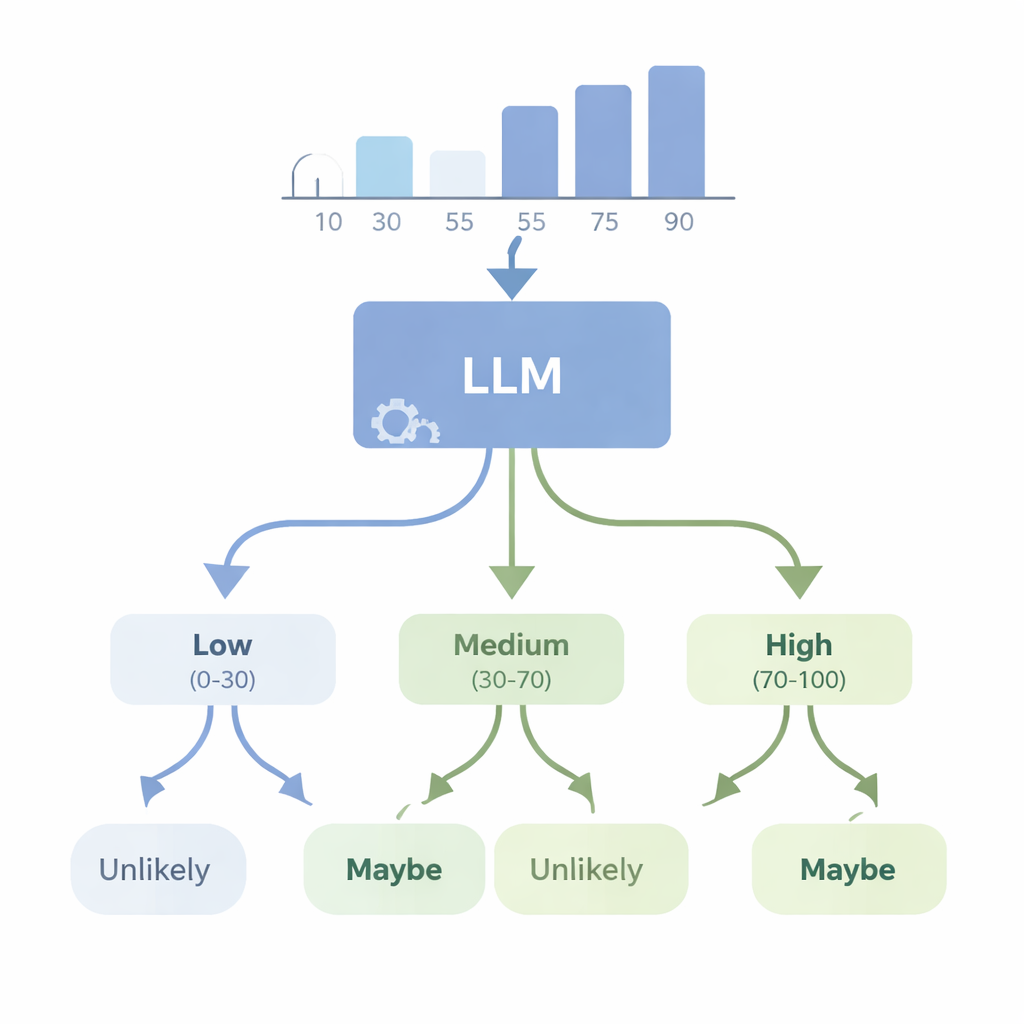
As IAs conseguem transformar números em dúvida em linguagem simples?
Em um segundo conjunto de experimentos, os autores examinaram o problema inverso: um modelo avançado como o GPT-4 pode partir de dados numéricos e escolher uma palavra de incerteza apropriada? Eles forneceram ao modelo conjuntos de dados simples — como listas de alturas ou notas de prova — e pediram que escolhesse a WEP mais adequada (por exemplo, “quase certamente”, “provável”, “talvez”, “improvável” ou “quase certamente não”) para afirmações sobre resultados futuros. Em seguida, avaliaram o GPT-4 com quatro novas pontuações de “consistência” que verificam se suas escolhas de palavras fazem sentido lógico quando as probabilidades sobem ou descem, quando eventos complementares são descritos e quando os números subjacentes mudam de maneiras controladas. O GPT-4 obteve desempenho muito melhor do que o palpite aleatório e muitas vezes conseguiu acompanhar mudanças grosseiras na probabilidade, mas ficou longe da consistência perfeita. Em alguns testes, ele respondeu praticamente da mesma forma em diferentes níveis de confiança, sugerindo que às vezes trata essas palavras como rótulos amplos em vez de uma escala finamente ajustada ligada aos dados reais.
O que isso significa para decisões no mundo real
Para os leitores, a mensagem é de cautela, mas não de alarme. LLMs já conseguem imitar nossas expressões mais fortes de certeza e impossibilidade, e frequentemente podem resumir dados em afirmações razoáveis do tipo “provável” ou “improvável”. Mas este estudo mostra que, para muitas palavras cotidianas de incerteza, a calibração interna dos modelos não corresponde completamente à intuição humana, e sua tradução de números para linguagem pode ser inconsistente. Em áreas como medicina, políticas públicas ou comunicação científica — onde pequenas variações na forma como expressamos risco ou confiança podem importar — o “provavelmente” de um modelo pode não ser o mesmo que o seu. Os autores argumentam que, para usar esses sistemas com segurança, devemos tratar palavras de incerteza como um código compartilhado que ainda precisa de alinhamento cuidadoso, testes e talvez apoio numérico explícito, em vez de presumir que humano e máquina significam a mesma coisa por padrão.
Citação: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Palavras-chave: incerteza linguagem, grandes modelos de linguagem, palavras de probabilidade, comunicação humano-IA, interpretação de risco