Clear Sky Science · pt
ADMM estocástico inexato pré-condicionado para modelos profundos
Treinamento mais inteligente para IA mais inteligente
Sistemas modernos de inteligência artificial, de chatbots a geradores de imagem, são movidos por redes neurais massivas que são notoriamente difíceis e caras de treinar. À medida que empresas e pesquisadores distribuem dados por muitos dispositivos e servidores, os métodos de treinamento padrão de hoje frequentemente desaceleram, tornam-se instáveis ou simplesmente não conseguem lidar com a desordem dos dados do mundo real. Este artigo apresenta uma nova família de algoritmos de treinamento, centrada em um método chamado PISA, que promete aprendizado mais rápido e mais confiável para uma ampla gama de modelos profundos, ao mesmo tempo em que faz menos suposições matemáticas sobre os dados.
Por que os métodos atuais de treinamento têm dificuldades
A maioria dos modelos de deep learning é treinada com variantes do gradiente descendente estocástico, uma abordagem que ajusta repetidamente os parâmetros do modelo na direção que reduz o erro. Ao longo dos anos, muitos refinamentos — como Adam, RMSProp e outros — tentaram tornar esses ajustes mais inteligentes, adaptando tamanhos de passo ou adicionando momento. No entanto, esses métodos geralmente supõem que os dados de treinamento estão bem embaralhados e estatisticamente semelhantes entre máquinas, e que certas quantidades matemáticas permanecem limitadas. Na prática, especialmente em cenários como o aprendizado federado, onde celulares ou dispositivos de borda possuem dados muito diferentes, essas suposições frequentemente são violadas, levando a convergência lenta ou desempenho ruim.
Uma nova forma de coordenar muitos aprendizes
Os autores constroem sobre um framework de otimização diferente conhecido como método de direção alternada dos multiplicadores (ADMM), que é eficaz em dividir um grande problema em muitos menores que podem ser resolvidos em paralelo. A principal contribuição deles, PISA (ADMM estocástico inexato pré-condicionado), preserva as forças do ADMM ao mesmo tempo em que evita suas desvantagens usuais — como a necessidade de computar gradientes completos sobre todos os dados ou realizar inversões de matrizes custosas. Em vez disso, PISA permite que cada cliente ou nó trabalhador atualize sua própria cópia do modelo usando apenas um mini-lote de dados e então coordena essas atualizações por meio de uma variável central. Matrizes de “pré-condicionamento” cuidadosamente projetadas reconfiguram as direções de atualização para que o aprendizado progrida de maneira mais suave e eficiente. 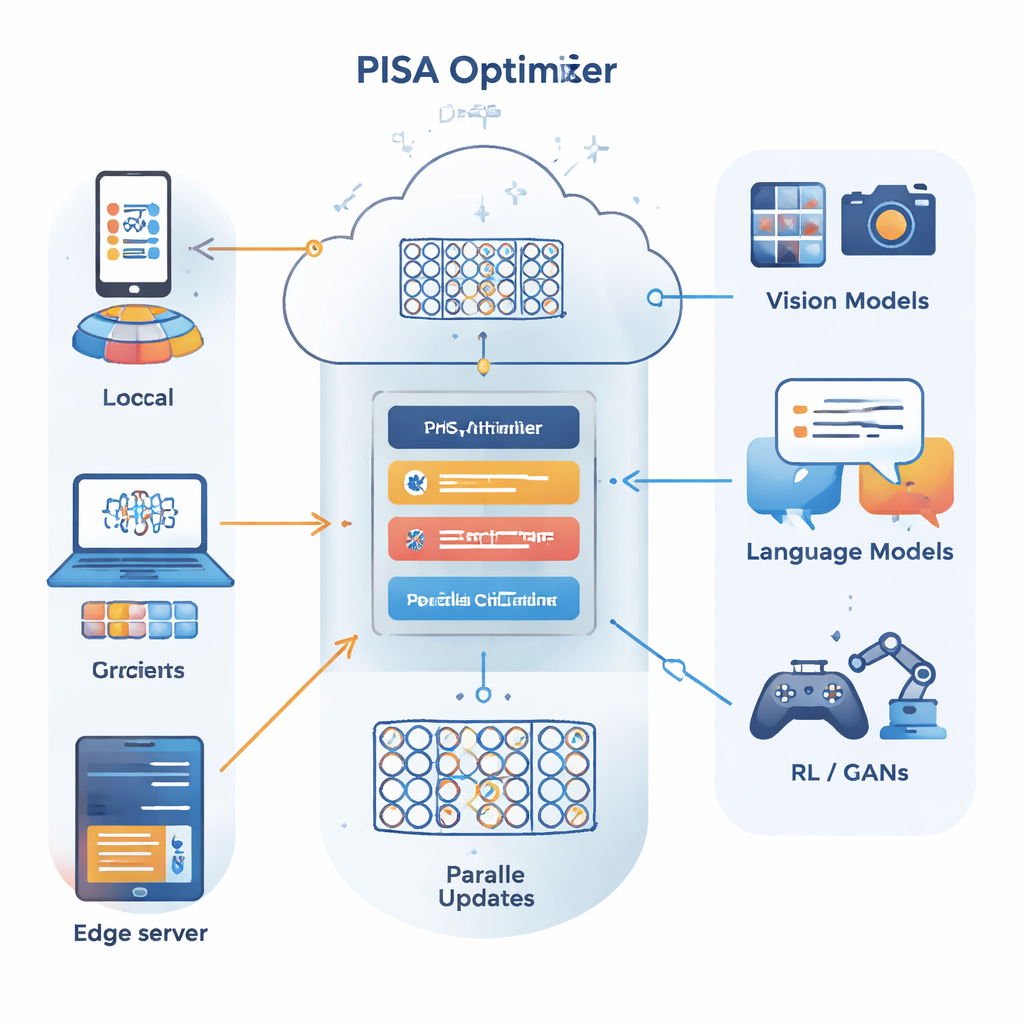
Garantias mais fortes com suposições mais brandas
Uma característica distintiva do PISA é sua base teórica. Os autores demonstram que seu algoritmo converge sob uma única suposição relativamente branda: que o gradiente da função de perda é Lipschitz contínuo dentro de uma região limitada, condição satisfeita por muitas perdas padrão de redes neurais. Ao contrário da maioria dos métodos estocásticos, o PISA não exige que os gradientes sejam não viesados, que tenham variância limitada ou que sejam extraídos de dados perfeitamente misturados. Apesar desse quadro relaxado, o método alcança uma taxa de convergência linear em termos de quão rápido os valores da função e as atualizações de parâmetros se estabilizam, colocando-o entre os algoritmos de melhor desempenho na tabela de comparação fornecida. Isso torna o PISA especialmente atraente para distribuições de dados heterogêneas e não uniformes que são comuns em implantações do mundo real.
Variantes práticas para redes profundas reais
Para tornar o framework prático para grandes redes neurais, os autores introduzem duas variantes eficientes, SISA e NSISA. SISA usa informação do segundo momento — essencialmente rastreando o quão grandes foram atualizações passadas em cada direção de parâmetro — para formar pré-condicionadores diagonais simples, análogos às ideias por trás do Adam e RMSProp, mas incorporados dentro da estrutura ADMM. NSISA vai um passo adiante incorporando uma técnica conhecida como ortogonalização de Newton–Schulz, inspirada no otimizador Muon, para alinhar melhor o momento com direções úteis no espaço de parâmetros. Ambas as variantes mantêm as garantias de convergência do PISA enquanto mantêm o custo computacional leve o suficiente para GPUs modernas e modelos grandes.
Desempenho em visão, linguagem e modelos generativos
Os autores testam SISA e NSISA em um amplo conjunto de tarefas de deep learning. Em experimentos de aprendizado federado com distribuições de rótulos deliberadamente enviesadas — um cenário difícil onde cada cliente vê apenas um subconjunto de classes — o SISA supera dramaticamente métodos populares como FedAvg, FedProx, FedNova e Scaffold, alcançando precisão de teste muito maior em benchmarks como MNIST e CIFAR-10. Para classificação de imagens padrão com modelos como ResNet e DenseNet em CIFAR-10 e ImageNet, o SISA iguala ou supera otimizadores fortes, incluindo SGD com momento, AdaBelief e AdamW. Ao ajustar modelos de linguagem GPT2 de tamanhos crescentes, o NSISA entrega menor perda de validação em menos tempo de relógio em comparação com otimizadores especializados como Shampoo, SOAP, Adam-mini e Muon, com a vantagem ficando mais pronunciada para o maior modelo. Também estabiliza o treinamento de redes adversariais geradoras, alcançando pontuações menores na distância de Fréchet inception, que mede a qualidade visual e a diversidade das imagens geradas. 
O que isso significa para a IA do dia a dia
Em termos simples, este trabalho mostra que é possível treinar modelos de IA poderosos mais rapidamente e com maior confiabilidade, mesmo quando os dados são desordenados, desbalanceados ou espalhados por muitos dispositivos. Ao redesenhar o processo de otimização subjacente em vez de apenas ajustar taxas de aprendizado, o PISA e suas variantes fornecem uma ferramenta unificada que funciona bem para visão, linguagem, aprendizado por reforço e tarefas generativas. Para usuários finais, o ganho pode significar personalização mais inteligente em celulares, modelos de linguagem e imagem mais capazes e uso mais eficiente de recursos computacionais em grandes centros de dados — tudo habilitado por um algoritmo de treinamento que combina melhor com as realidades dos sistemas modernos de IA.
Citação: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Palavras-chave: otimização em deep learning, aprendizado federado, ADMM estocástico, modelos de linguagem grandes, dados heterogêneos