Clear Sky Science · pt
Quando modelos de linguagem grandes são confiáveis para avaliar comunicação empática
Por que a empatia das máquinas importa para você
Cada vez mais, as pessoas recorrem a chatbots e assistentes digitais quando estão estressadas, solitárias ou diante de decisões difíceis. Esses sistemas podem soar carinhosos e compreensivos — mas eles também conseguem avaliar se uma mensagem é realmente solidária e gentil? Este artigo explora quando os modelos de linguagem grandes (LLMs), a tecnologia por trás de muitos chatbots, podem avaliar com confiabilidade o grau de empatia percebido em uma resposta escrita e o que isso significa para ferramentas do dia a dia, como aplicativos de bem‑estar, terapeutas virtuais e bots de atendimento ao cliente. 
Estudando conversas de apoio
Os pesquisadores analisaram 200 conversas reais por texto nas quais uma pessoa descrevia um problema pessoal — como estresse no trabalho, conflito familiar, preocupações financeiras ou dificuldades de saúde mental — e outra pessoa tentava responder de forma solidária. Essas conversas vieram de quatro conjuntos de dados existentes, cada um associado a um conjunto diferente de questões para julgar a empatia. Alguns se concentravam em saber se o respondente demonstrou compreensão ou ofereceu conforto emocional; outros perguntavam se deram conselhos práticos, encorajaram a pessoa a falar mais ou, em vez disso, centraram a conversa em si mesmos. Juntos, esses critérios decompõem o “ser empático” em 21 comportamentos específicos que podem ser avaliados em escalas, de modo similar a uma pesquisa de satisfação do cliente.
Especialistas, multidões e máquinas
Para verificar quão bem os LLMs podem avaliar a empatia, a equipe comparou três tipos de avaliadores: especialistas em comunicação, trabalhadores online da multidão e modelos de linguagem modernos. Três estudiosos experientes em comunicação empática avaliaram independentemente cada conversa nos 21 comportamentos. Trabalhadores de crowdsourcing — usuários comuns da internet — já haviam fornecido avaliações para as mesmas mensagens em estudos anteriores. Por fim, três modelos de linguagem líderes foram cuidadosamente instruídos com orientações em linguagem simples e exemplos de avaliações feitas pelos especialistas, e então solicitados a pontuar cada conversa nas mesmas escalas. Esse arranjo permitiu aos autores medir o quanto cada grupo concordava, não apenas com uma “resposta correta”, mas entre si. 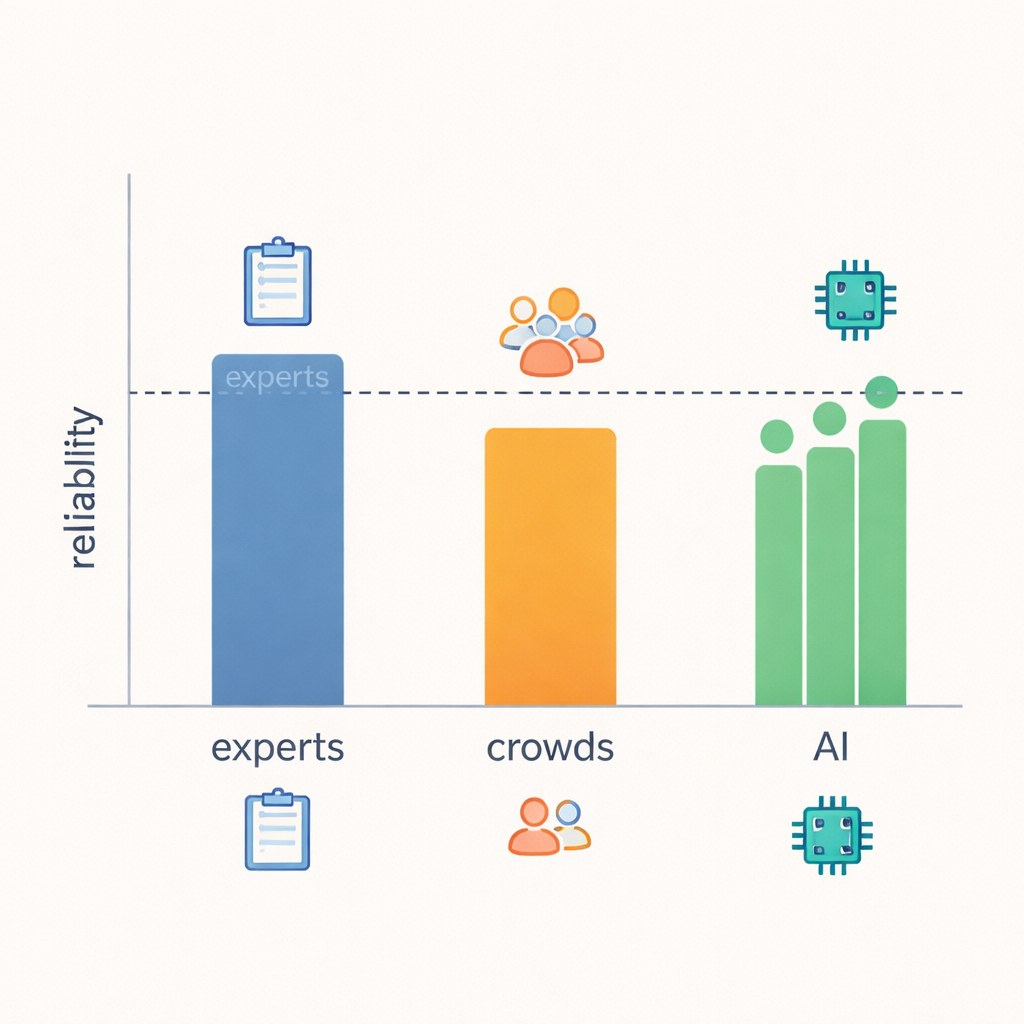
Quão próximas foram as concordâncias?
A descoberta central é que os LLMs chegaram surpreendentemente perto da confiabilidade em nível de especialistas. Quando os pesquisadores mediram com que frequência as avaliações coincidiam e a magnitude dos desacordos, os modelos igualaram ou quase igualaram os especialistas em grande parte dos 21 comportamentos, e claramente superaram os avaliadores da multidão. Em áreas com sinais claros e observáveis — como se uma resposta deu conselhos práticos, fez perguntas de acompanhamento ou voltou a atenção ao interlocutor — especialistas, LLMs e até a multidão tendiam a concordar mais. Mas ao julgar ideias mais difusas, como se uma resposta realmente “demonstrou compreensão” ou quais eram as intenções do respondente, até os especialistas discordaram com mais frequência, e a confiabilidade dos LLMs caiu junto com a deles. Isso sugere que alguns aspectos da empatia são simplesmente mais difíceis de determinar apenas pelo texto, independente de quem esteja avaliando.
Por que pontuações simples podem enganar
Muitos estudos de IA relatam sucesso usando pontuações de classificação familiares — tratando cada avaliação de especialista como verdade incontestável e medindo com que frequência um modelo a corresponde. Os autores mostram que essa abordagem pode pintar um quadro distorcido quando se trata de julgamentos humanos sutis. Por exemplo, um sistema pode obter boa pontuação ao simplesmente chutar a avaliação majoritária em uma escala desequilibrada, mesmo que tenha dificuldades em casos raros, mas importantes. Da mesma forma, um método que em grande parte acerte por pouco — errando por apenas um ponto — pode parecer ruim em uma métrica de correspondência estrita, embora se comporte de modo muito semelhante a um especialista humano. Ao focar na confiabilidade entre avaliadores — quão consistentemente avaliadores diferentes pontuam a mesma coisa — o estudo oferece uma visão mais honesta do que tanto humanos quanto máquinas podem avaliar com segurança.
O que isso significa para a IA do dia a dia
Para o público em geral, a conclusão é ao mesmo tempo promissora e cautelosa. LLMs bem configurados podem agora ajudar a verificar se respostas escritas — de ajudantes humanos ou de outros bots — atendem aos padrões especialistas de comunicação empática, e muitas vezes fazem isso com mais consistência do que avaliadores humanos não treinados. Isso pode facilitar o monitoramento e a melhoria de chatbots usados em saúde, educação e atendimento ao cliente. Ao mesmo tempo, o estudo alerta que nem todos os “testes de empatia” são equivalentes: perguntas vagas ou sobrepostas levam a uma concordância humana frágil e, por consequência, a julgamentos automáticos instáveis. Antes de confiar à IA a avaliação de algo tão delicado quanto apoio emocional, devemos primeiro garantir que os próprios especialistas concordem sobre o que é “bom” — e usar esse parâmetro para decidir onde as máquinas podem auxiliar com segurança e onde o julgamento humano continua essencial.
Citação: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
Palavras-chave: comunicação empática, modelos de linguagem grandes, companheiros de IA, apoio à saúde mental, interação humano–IA