Clear Sky Science · pt
Melhorando a predição de kcat por meio de um mecanismo de atenção sensível a resíduos e representações pré-treinadas
Por que previsões mais rápidas de enzimas importam
Enzimas são os pequenos operários que mantêm células — e indústrias inteiras — em funcionamento. Elas aceleram reações químicas que movimentam nosso metabolismo, produzem medicamentos e viabilizam processos de manufatura mais sustentáveis. Um número-chave que descreve a velocidade de uma enzima é a constante de turnover, ou kcat. Medir kcat em laboratório é demorado e caro, por isso cientistas recorrem à inteligência artificial para prevê‑lo a partir da sequência e da informação sobre a reação. Este artigo apresenta o PMAK, um novo modelo de IA que não só prevê kcat com mais precisão do que ferramentas anteriores, como também ajuda a identificar quais partes da enzima são mais importantes para sua atividade.
Do trabalho pesado no laboratório a previsões inteligentes
Tradicionalmente, determinar kcat significa medir cuidadosamente a rapidez com que uma enzima converte seu substrato em produto sob condições estritamente controladas, como temperatura e pH fixos. Fazer isso para milhares de enzimas é impraticável, o que limita nossa capacidade de modelar redes metabólicas inteiras ou projetar novos biocatalisadores. Métodos computacionais anteriores tentaram preencher essa lacuna, mas muitos dependiam de características elaboradas manualmente ou de uma visão simplificada da enzima e de um único substrato. Frequentemente funcionavam bem apenas quando as novas enzimas eram muito semelhantes às já vistas nos dados de treinamento, e tinham dificuldade com enzimas verdadeiramente novas, reações inéditas ou mutantes projetados.
Ensinando computadores a “linguagem” das enzimas e das reações
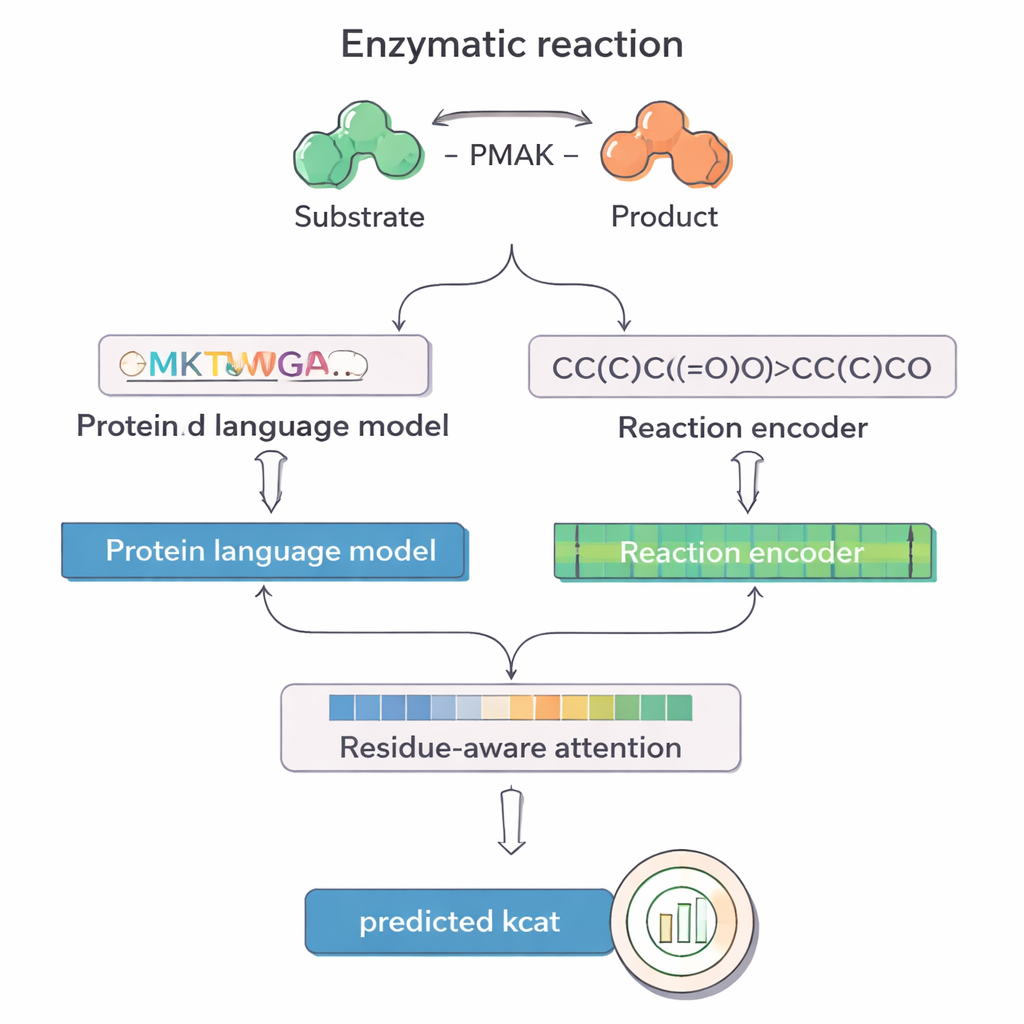
O PMAK aproveita avanços recentes em “modelos de linguagem” originalmente desenvolvidos para texto, mas re-treinados em vastas coleções de sequências proteicas e reações químicas. Um modelo, chamado ProT5, transforma a sequência de aminoácidos de uma enzima em uma representação numérica rica que captura padrões aprendidos a partir de milhões de proteínas. Outro modelo, RXNFP, faz o mesmo para reações inteiras escritas como cadeias SMILES, que codificam todos os reagentes e produtos. O PMAK alimenta essas duas representações aprendidas em uma rede neural que alinha suas dimensões e permite que o modelo considere tanto a enzima quanto o contexto completo da reação em conjunto, em vez de tratá‑los separadamente.
Dando destaque aos blocos de construção mais importantes
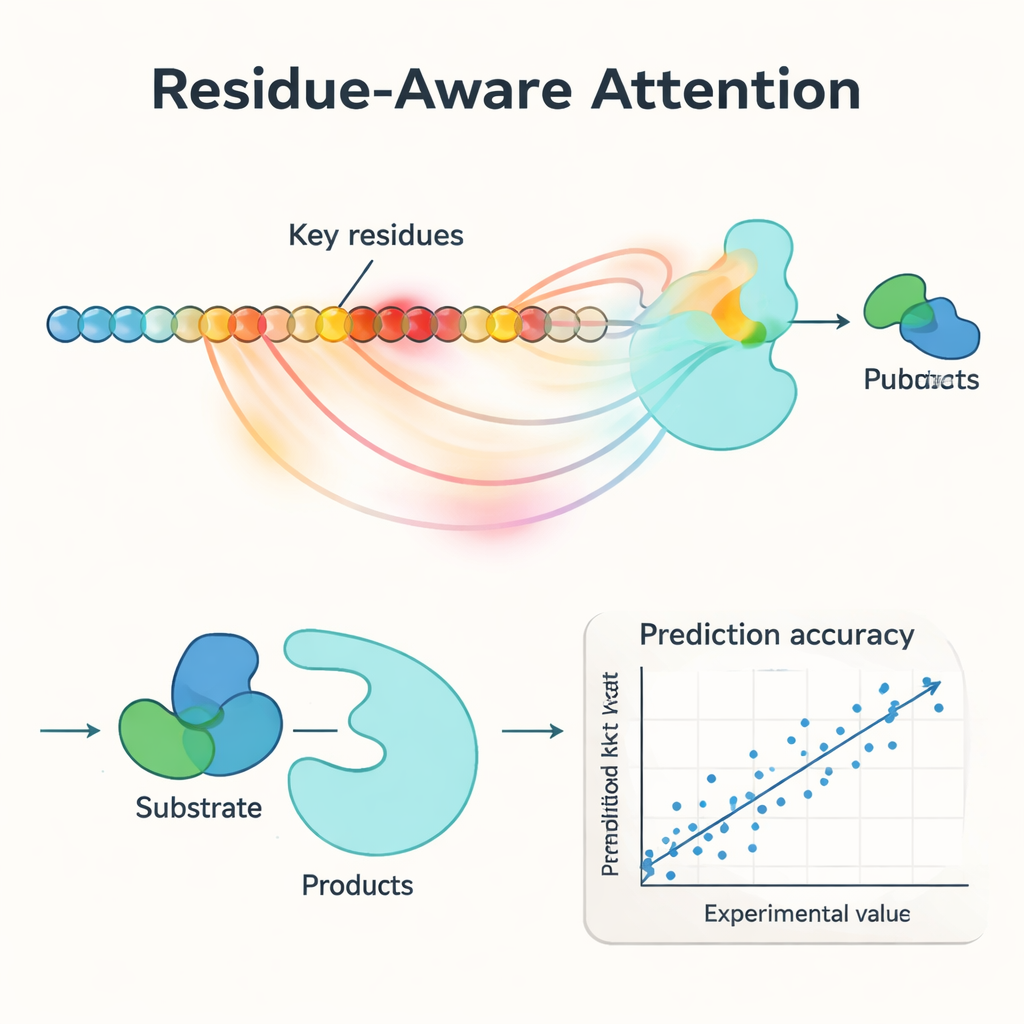
Uma inovação central do PMAK é um mecanismo de “atenção sensível a resíduos”. Em vez de tratar cada aminoácido de uma enzima como igualmente importante, o modelo aprende a atribuir pesos maiores a resíduos específicos que mais influenciam a reação em questão. Essas pontuações de atenção agem como um holofote sobre a sequência: quando os pesquisadores as compararam com sítios ativos e de ligação conhecidos a partir de estruturas proteicas, descobriram que o PMAK consistentemente destacou resíduos funcionais com muito mais frequência do que o acaso. O modelo também teve bom desempenho mesmo quando os sítios ativos foram definidos de forma mais ampla para incluir resíduos vizinhos no espaço 3D, sugerindo que captura pistas estruturais e químicas sutis relevantes para a catálise.
Bom desempenho em enzimas novas, reações inéditas e mutantes
Os autores testaram rigorosamente o PMAK em um conjunto de dados curado com mais de 4.000 valores de kcat cobrindo quase 3.000 enzimas e 2.800 reações. Em condições de “warm-start” — onde enzimas e reações semelhantes aparecem tanto nos conjuntos de treinamento quanto nos de teste — o PMAK igualou ou superou os melhores modelos existentes. Mais impressionante, em testes de “cold-start”, nos quais a enzima ou a reação no conjunto de teste nunca haviam sido vistas antes, o PMAK superou uma gama de métodos de ponta. Ele permaneceu útil mesmo para enzimas com similaridade de sequência muito baixa em relação aos dados de treinamento e para reações que pareciam bastante diferentes daquelas das quais aprendeu. O PMAK também melhorou previsões em aplicações realistas, como estimar como células alocam seus limitados recursos proteicos e prever os efeitos de mutações em conjuntos de dados de engenharia enzimática.
O que isso significa para biologia e biotecnologia
Para não especialistas, o PMAK pode ser visto como um assistente inteligente que aprende com enormes “bibliotecas” de proteínas e reações para estimar quão rápido qualquer enzima atuará em uma reação particular — e para explicar quais aminoácidos impulsionam esse comportamento. Ao combinar maior precisão com insights ao nível dos resíduos, essa abordagem pode ajudar pesquisadores a projetar enzimas melhores, construir modelos metabólicos mais confiáveis e explorar como mutações afetam a função sem realizar cada experimento no laboratório. À medida que modelos semelhantes se expandirem para outros traços cinéticos, eles podem se tornar ferramentas chave para projetar processos industriais mais limpos, otimizar microrganismos para produção sustentável e aprofundar nossa compreensão de como as máquinas moleculares da vida alcançam suas notáveis velocidades.
Citação: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
Palavras-chave: cinética enzimática, aprendizado profundo, predição de kcat, engenharia de proteínas, modelagem metabólica