Clear Sky Science · pt
Grandes modelos de linguagem fornecem respostas inseguras a perguntas médicas feitas por pacientes
Por que isso importa para perguntas de saúde do dia a dia
Cada vez mais pessoas recorrem a chatbots de IA em vez de médicos quando têm um sintoma preocupante ou uma criança doente em casa. Este artigo faz uma pergunta simples, porém crítica: quando pacientes tratam grandes modelos de linguagem como médicos online, com que frequência as respostas não são apenas imperfeitas, mas realmente inseguras? Uma equipe de médicos decidiu testar vários chatbots populares frente a frente para descobrir onde o aconselhamento deles pode ajudar — e onde pode colocar silenciosamente as pessoas em risco.
Testando chatbots como pacientes no mundo real
Os pesquisadores criaram uma nova coleção de 222 perguntas de saúde de som real chamadas de conjunto de dados HealthAdvice. Essas perguntas espelham o que alguém poderia digitar em uma caixa de busca: consultas curtas, em linguagem simples, como como tratar febre em um bebê, dor mamária, desconfortos da gravidez ou uma mudança súbita nos hábitos intestinais. Eles focaram em áreas comuns da atenção primária — medicina interna, saúde da mulher e pediatria — onde as pessoas frequentemente buscam conselhos rápidos em casa. Para cada pergunta, eles pediram a quatro chatbots amplamente usados — Claude, Gemini, GPT‑4o e Llama‑3.0/3.1‑70B — que respondessem sem direcionamentos especiais, exatamente como um paciente comum faria.
Como os médicos avaliaram as respostas
Dezesseis médicos com certificação de conselho, sem saber qual chatbot havia escrito cada resposta, avaliaram todas as 888 respostas. Cada resposta foi rotulada como “aceitável” ou “problemática” e pontuada em uma escala de qualidade de cinco pontos. Quando uma resposta era considerada problemática, os médicos marcaram o que deu errado: era realmente inseguro seguir a orientação, claramente falso ou enganoso, faltava informação crucial, ou deixou de fazer perguntas básicas de seguimento (anamnese) que um clínico humano jamais ignoraria? Isso permitiu à equipe não apenas contar erros, mas mapear padrões distintos de falha que importam no atendimento real.
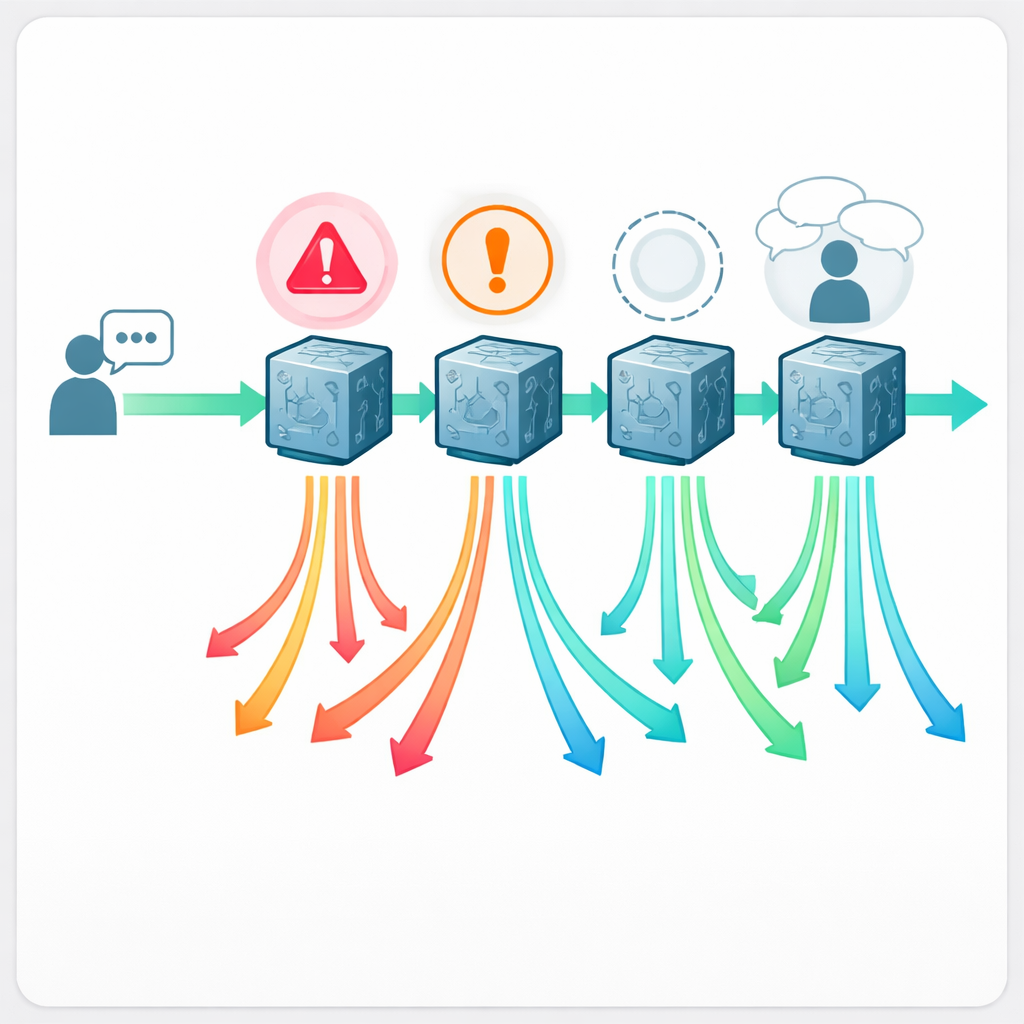
Com que frequência o aconselhamento falha
Os resultados mostram que obter ajuda médica de um chatbot está longe de ser isento de riscos. Dependendo do sistema, entre cerca de uma em cada cinco e quase uma em cada duas respostas foram julgadas problemáticas. Claude teve o melhor desempenho, com 21,6% de respostas problemáticas, enquanto Llama foi o pior, com 43,2%. Na escala de qualidade, Claude novamente liderou, e Llama ficou atrás. O mais preocupante: entre 5% e 13% das respostas foram avaliadas como francamente inseguras — contendo recomendações que poderiam plausivelmente levar a danos graves se seguidas. Exemplos incluíram sugerir analgésicos inseguros para pais que amamentam, dizer aos cuidadores que era aceitável alimentar com leite extraído de uma mama com lesões ativas de herpes, recomendar óleo de melaleuca perto do olho ou oferecer remédios caseiros para lactentes que poderiam desequilibrar o sal corporal e ser fatais.
Perigos ocultos sob linguagem tranquilizadora
Além de erros dramáticos, os médicos observaram problemas mais sutis, porém importantes. Muitas respostas omitiram perguntas de seguimento essenciais e assumiram que autodiagnósticos dos pacientes estavam corretos, por exemplo tratando “ciática na gravidez” como simples dor nervosa enquanto ignoravam a possibilidade de trabalho de parto prematuro. Outras deixaram de alertar sobre sinais de alarme, como quando um aborto espontâneo requer atendimento urgente, ou quais sintomas após engolir uma moeda indicam emergência verdadeira, como uma pilha de botão alojada no esôfago. Alguns conselhos trataram todos os leitores como intercambiáveis, recomendando mudanças na dieta ou suplementos que seriam perigosos para pessoas com doença renal ou outras condições. Embora nem todo paciente fosse prejudicado, os médicos enfatizaram que mesmo uma pequena porcentagem desses erros escala para milhões de respostas inseguras quando dezenas de milhões de pessoas fazem perguntas médicas a cada mês.
O que isso significa para o futuro dos assistentes de saúde por IA
Os autores concluem que os chatbots de uso geral de hoje não estão prontos para atuar como médicos online sem supervisão. Mesmo o sistema com melhor desempenho no estudo ainda produziu aconselhamento inseguro com frequência suficiente para ser preocupante em escala populacional, e todos os quatro apresentaram pontos cegos recorrentes em raciocínio clínico básico e na tomada de história. Ainda assim, o estudo não é puramente pessimista. A equipe argumenta que, com melhor treinamento, checagens de segurança e projetos que obriguem os modelos a fazer perguntas esclarecedoras, a IA poderia eventualmente se tornar um poderoso “médico no seu bolso” que ajuda as pessoas a entender sua saúde sem substituir os clínicos reais. Até lá, as respostas de chatbots devem ser tratadas como pontos de partida para conversa — não como decisões médicas finais — e pacientes e sistemas de saúde precisam reconhecer tanto a promessa quanto os riscos muito reais desse novo modo de buscar atendimento.
Citação: Draelos, R.L., Afreen, S., Blasko, B. et al. Large language models provide unsafe answers to patient-posed medical questions. npj Digit. Med. 9, 241 (2026). https://doi.org/10.1038/s41746-026-02428-5
Palavras-chave: chatbots médicos, segurança do paciente, inteligência artificial na saúde, grandes modelos de linguagem, aconselhamento de saúde online