Clear Sky Science · pt
Avaliação de grandes modelos de linguagem para geração de impressões diagnósticas a partir de achados de ressonância magnética cerebral: um referencial multicêntrico e estudo com leitores
Por que relatórios de RMI mais inteligentes importam para os pacientes
Quando você realiza uma tomografia por ressonância magnética do cérebro, um radiologista precisa transformar milhares de tons de cinza em uma declaração clara sobre o que está errado — ou de que tudo parece normal. Essa “impressão” final orienta decisões cruciais sobre atendimento de AVC, tumores cerebrais, infecções e mais. Mas ler exames de RMI cerebral é complexo e consome tempo, e médicos sobrecarregados podem cometer erros, especialmente em hospitais movimentados. Este estudo investiga se modelos avançados de linguagem por inteligência artificial podem ajudar radiologistas de forma confiável a transformar achados escritos de RMI em impressões diagnósticas precisas, rápidas e consistentes.
Transformando descrições brutas dos exames em respostas claras
As RMIs cerebrais produzem uma série de imagens que os radiologistas descrevem em uma seção de “achados”, observando, por exemplo, onde uma lesão está localizada, quão brilhante ela aparece e se há edema. O desafio real é então combinar todos esses detalhes em uma impressão diagnóstica, como “infarto agudo” ou “abscesso cerebral”. Os pesquisadores coletaram 4.293 laudos de RMI cerebral de três hospitais na China, abrangendo 16 categorias diagnósticas que cobrem mais de 95% das condições cerebrais comuns do dia a dia. Em seguida, testaram 10 modelos diferentes de grandes modelos de linguagem — sistemas avançados de IA baseados em texto — para avaliar o quão bem cada um conseguia transformar os achados escritos nos diagnósticos corretos.
Modelos grandes e bem treinados se destacaram
A equipe comparou modelos que variavam de cerca de 8 bilhões a 671 bilhões de parâmetros internos, aproximadamente análogo a passar do conhecimento de um estudante de medicina ao de uma equipe de especialistas. O maior modelo, chamado DeepSeek‑R1, apresentou consistentemente o melhor desempenho quando recebeu tanto versões estruturadas dos achados quanto informações clínicas chave, como idade do paciente, sintomas ou histórico de trauma. Nestas condições, o DeepSeek‑R1 identificou corretamente a presença ou ausência de condições cerebrais específicas com alta sensibilidade e especificidade, alcançando precisão em nível de paciente acima de 87%. Modelos menores, especialmente aqueles com menos de 10 bilhões de parâmetros, tiveram desempenho ruim, frequentemente acertando apenas cerca de 30% dos casos — bem abaixo do aceitável na prática clínica real.
Por que estrutura e contexto tornam a IA mais eficaz
Os pesquisadores não alimentaram os modelos apenas com texto livre. Eles também utilizaram outro sistema de IA para reestruturar os laudos em elementos claros e padronizados: onde cada lesão estava localizada, quantas havia e como se apresentavam em diferentes sequências de RMI. Adicionar essa estrutura e combiná‑la com breves notas clínicas fez uma diferença marcante. Para o DeepSeek‑R1, a mudança de achados em texto corrido para achados estruturados mais contexto clínico aumentou sensibilidade, precisão geral e medidas resumidas de desempenho. Em termos simples, a IA se saiu muito melhor quando recebeu informação mais limpa e organizada e um pouco de histórico do paciente — espelhando como radiologistas humanos trabalham melhor quando os laudos são claros e a questão clínica está definida.
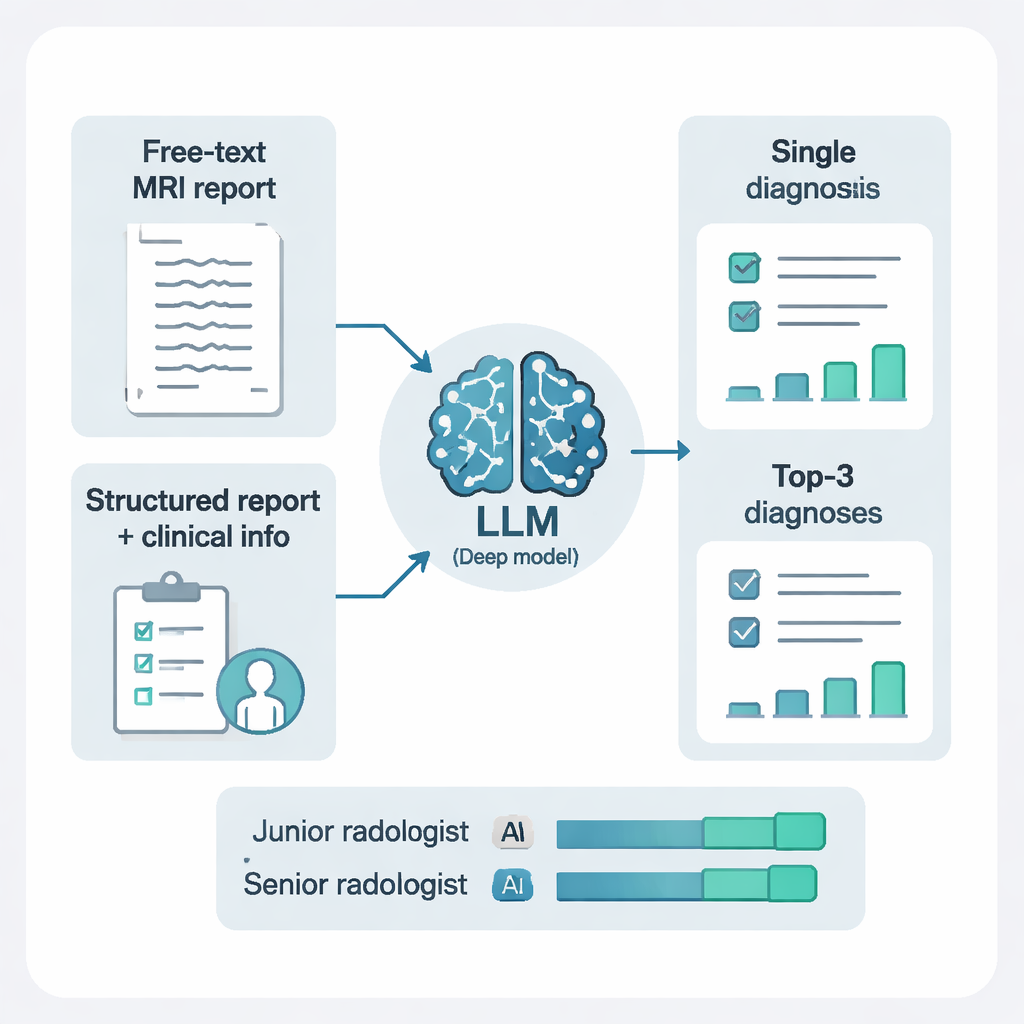
De um palpite único para uma lista curta ranqueada
Na prática, radiologistas frequentemente oferecem mais de um diagnóstico possível para casos complexos. O estudo testou dois estilos de instrução: pedir à IA apenas um diagnóstico, ou pedir suas três principais possibilidades, cada uma com uma breve justificativa. Permitir três diagnósticos ranqueados melhorou o desempenho de forma dramática. Com essa abordagem de “diagnóstico diferencial”, a resposta correta apareceu em algum lugar entre as três primeiras sugestões em mais de 97% dos pacientes. Isso foi especialmente útil em casos complexos como tumores, hemorragias ou doenças inflamatórias, em que um palpite único pode ser enganoso, mas uma lista curta e fundamentada pode orientar efetivamente exames e tratamentos adicionais.
Impacto no mundo real para radiologistas sobrecarregados
Para avaliar se esses ganhos importam na prática, os autores conduziram um estudo com leitores envolvendo seis radiologistas — três juniores e três seniores — que interpretaram 500 laudos de RMI cerebral com e sem a ajuda do DeepSeek‑R1. Com a assistência da IA, a precisão diagnóstica geral subiu de cerca de três quartos dos casos para mais de 90%, e uma medida-chave de qualidade que combina precisão e sensibilidade também melhorou substancialmente. O tempo de leitura diminuiu também, de aproximadamente um minuto por caso para menos de um minuto, o que pode se traduzir em dezenas de horas poupadas por radiologista a cada ano. Os maiores benefícios foram observados entre os radiologistas juniores, cujo desempenho se aproximou mais do dos especialistas experientes, embora o estudo também ressalte que os médicos devem permanecer cautelosos e não confiar cegamente na IA, particularmente para condições muito sutis, como certos tipos de hemorragia cerebral.
O que isso significa para futuros laudos de exames cerebrais
Para os pacientes, a principal conclusão é que sistemas de IA poderosos baseados em linguagem já podem ajudar radiologistas a transformar descrições complexas de RMI em impressões diagnósticas mais claras e precisas, especialmente quando recebem informações bem estruturadas e detalhes clínicos essenciais. Essas ferramentas não substituem a expertise humana, mas podem atuar como um segundo par de olhos criteriosos, oferecendo sugestões fundamentadas e economizando tempo. Se validadas mais amplamente e integradas com segurança aos sistemas hospitalares, esse suporte de IA poderia tornar os laudos de exames cerebrais mais rápidos, confiáveis e consistentes — melhorando, em última instância, o cuidado de pessoas com AVC, tumores, infecções e muitas outras condições cerebrais.
Citação: Wang, ML., Zhang, RP., Wu, WJ. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. npj Digit. Med. 9, 187 (2026). https://doi.org/10.1038/s41746-026-02380-4
Palavras-chave: diagnóstico por ressonância magnética cerebral, inteligência artificial em radiologia, grandes modelos de linguagem, suporte à decisão clínica, DeepSeek-R1