Clear Sky Science · pt
Grandes modelos de linguagem melhoram a transferibilidade de predições baseadas em prontuários eletrônicos entre países e sistemas de codificação
Por que compartilhar dados médicos de forma mais inteligente importa
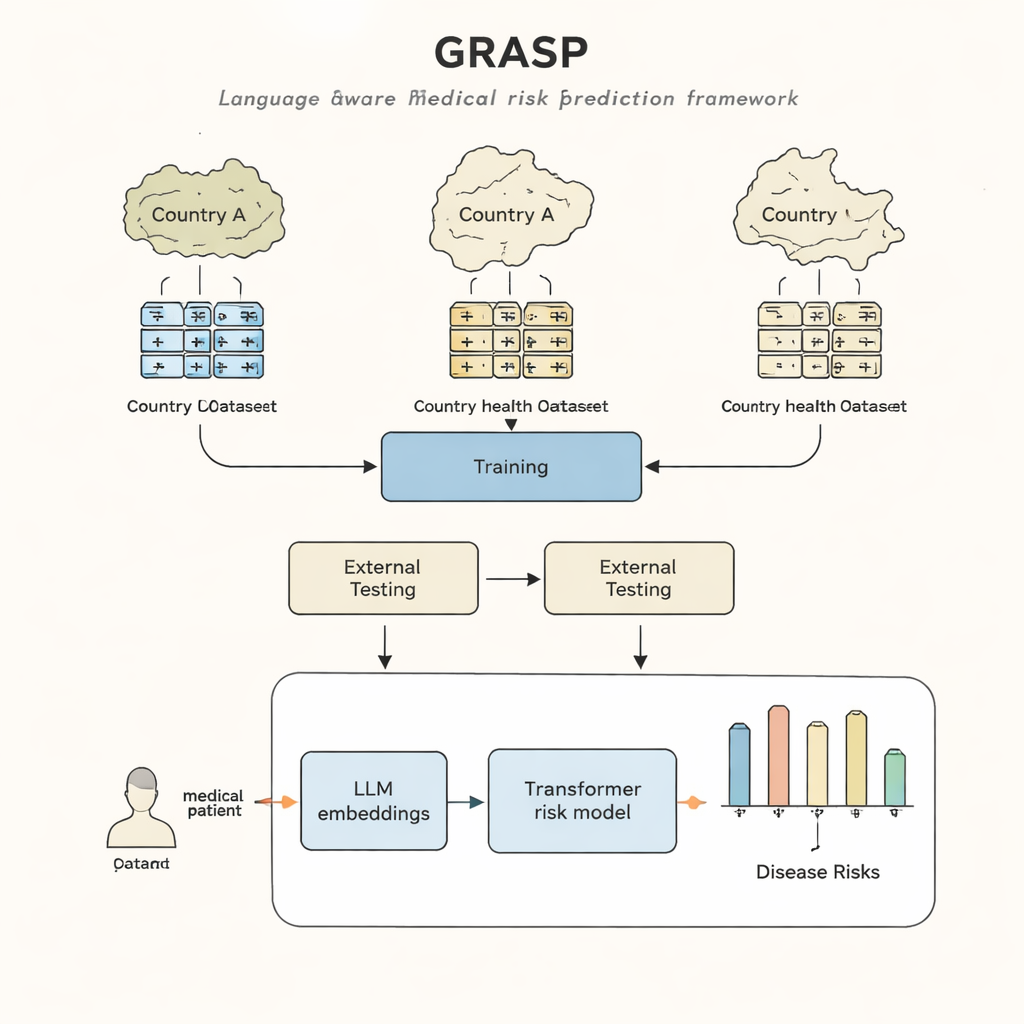
Hospitais e clínicas ao redor do mundo detêm uma mina de ouro de informação: prontuários eletrônicos que registram diagnósticos, tratamentos e desfechos das pessoas ao longo de muitos anos. Em teoria, essas informações poderiam ajudar médicos a identificar precocemente quem está em alto risco de doenças graves, muito antes de os sintomas se tornarem óbvios. Na prática, porém, os modelos computacionais atuais têm dificuldade em “viajar” de um país ou sistema hospitalar para outro porque cada lugar registra os dados de saúde de maneira diferente. Este estudo introduz uma nova abordagem, chamada GRASP, que usa avanços em inteligência artificial para reduzir essas lacunas de modo que um modelo treinado em um sistema de saúde funcione de forma confiável em outros.
Hospitais diferentes, linguagens diferentes
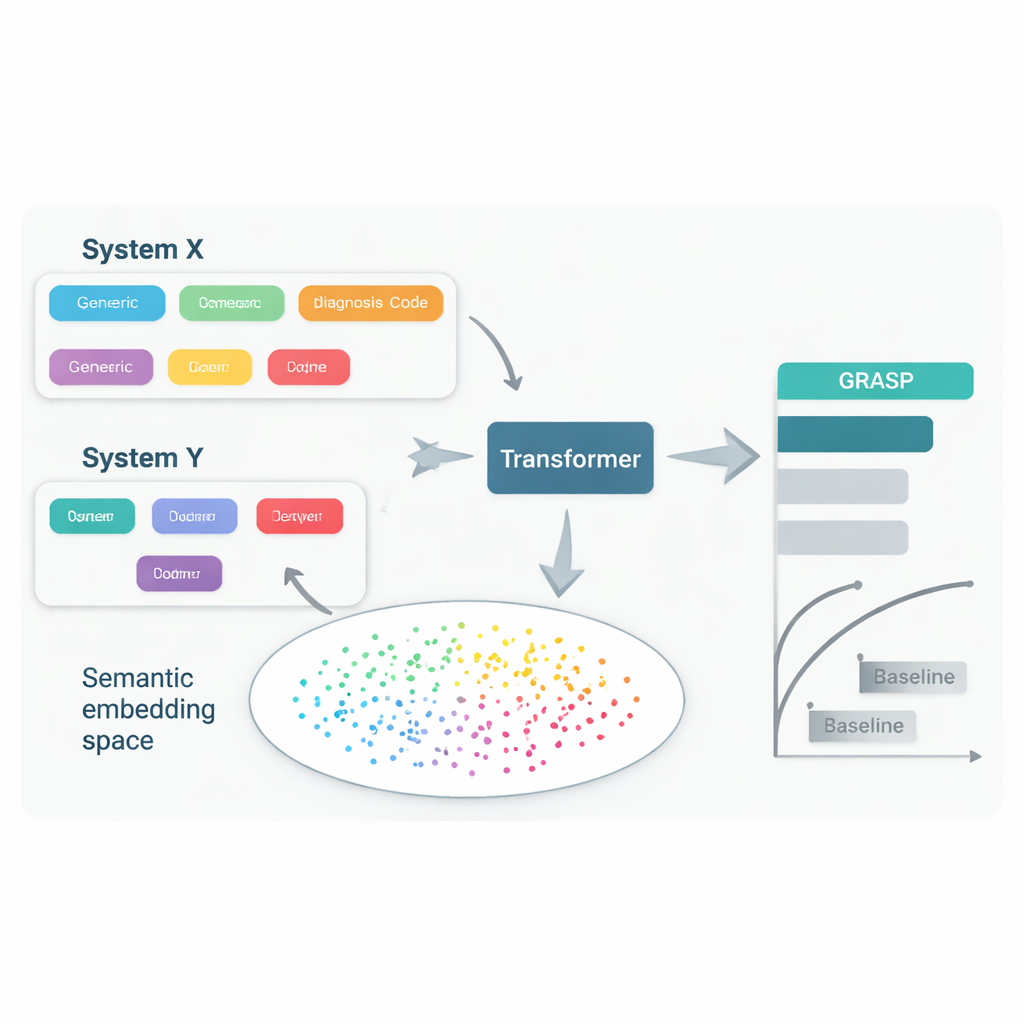
Mesmo quando médicos tratam da mesma doença, frequentemente usam sistemas de códigos e convenções locais distintos para registrá‑la no prontuário. Um hospital pode armazenar “alto nível de açúcar no sangue” sob um código, enquanto outro usa um código diferente para “hiperglicemia”, e um terceiro emprega um sistema totalmente distinto. Esforços para forçar todo mundo a aderir a um padrão comum — como grandes esquemas internacionais de codificação — são úteis, mas lentos, caros e ainda deixam diferenças importantes para trás. Como resultado, um modelo computacional que prevê doenças a partir de registros em um país pode perder precisão quando aplicado em outro, limitando quem pode se beneficiar dessas ferramentas.
Deixar a IA ler o significado, não apenas o código
A abordagem GRASP parte de uma ideia simples: em vez de tratar cada código médico como um número de identificação sem significado, deixar um grande modelo de linguagem ler a descrição humana por trás dele, como “infecção aguda do trato respiratório superior”, e transformar esse significado em um “embedding” numérico. Esses embeddings colocam conceitos relacionados próximos entre si em um espaço compartilhado, mesmo que venham de diferentes sistemas de codificação ou países. O GRASP pré‑calcula esses embeddings para milhões de termos médicos padronizados e os armazena em uma tabela de consulta. O histórico médico de um paciente é então representado como uma sequência desses vetores ricos, que são enviados a uma rede transformer — um tipo de rede neural bem adequada para lidar com coleções de entradas diversas — para estimar o risco dessa pessoa para 21 doenças principais, além do risco geral de morte.
Testes entre países e sistemas de registro
Os pesquisadores treinaram o GRASP usando dados de quase 400.000 participantes do UK Biobank e depois o testaram sem re‑treinamento em dois cenários bem diferentes: o projeto FinnGen na Finlândia e uma grande rede hospitalar na cidade de Nova York. O GRASP igualou ou superou alternativas robustas, incluindo um método popular chamado XGBoost e um transformer similar que não usava embeddings baseados em linguagem. Na Finlândia, o GRASP se saiu especialmente bem, mostrando ganhos claros para condições como asma, doença renal crônica e insuficiência cardíaca. De forma notável, mesmo quando os dados hospitalares americanos permaneceram em um esquema de codificação diferente em vez de serem convertidos para um padrão compartilhado, o GRASP ainda forneceu melhores previsões do que apenas dados demográficos, porque conseguiu alinhar códigos puramente entendendo a redação de suas descrições.
Obter mais com menos dados
Outra vantagem do GRASP é a eficiência. Como o modelo de linguagem já aprendeu que muitos conceitos médicos são relacionados, a rede de predição não precisa redescobrir essas conexões do zero. Quando os autores treinaram o GRASP em subconjuntos muito menores dos dados do Reino Unido — chegando a apenas 10.000 pessoas — ele ainda superou modelos concorrentes treinados nas mesmas amostras limitadas, tanto no Reino Unido quanto quando transferido para outros lugares. As pontuações de risco do GRASP também se alinharam mais estreitamente com o risco genético herdado das pessoas para várias doenças, sugerindo que ele captura aspectos mais profundos da suscetibilidade às doenças em vez de apenas memorizar padrões em um único conjunto de dados.
O que isso significa para o cuidado futuro
Para não especialistas, a mensagem principal é que o GRASP mostra como a IA moderna baseada em linguagem pode ajudar diferentes sistemas de saúde a “falar a mesma língua” sem forçá‑los a adotar um único esquema rígido de codificação. Ao ler o significado dos termos médicos, o GRASP pode produzir predições de risco de doença que generalizam melhor entre países e formatos de prontuário, e pode fazê‑lo com menos exemplos de pacientes. Embora o método ainda precise de testes cuidadosos, recalibração e verificações de equidade antes do uso na prática clínica cotidiana, ele aponta para um futuro em que ferramentas poderosas de risco desenvolvidas em um lugar possam ser compartilhadas de forma segura e eficiente com hospitais e clínicas ao redor do mundo.
Citação: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Palavras-chave: prontuários eletrônicos, predição de risco de doenças, grandes modelos de linguagem, compartilhamento de dados médicos, IA na saúde