Clear Sky Science · pt
Comparando aprendizado de máquina descentralizado e modelos clínicos de IA com alternativas locais e centralizadas: uma revisão sistemática
Por que compartilhar insights médicos sem compartilhar dados é importante
A medicina moderna depende cada vez mais da inteligência artificial para detectar doenças mais cedo, escolher o tratamento adequado e prever quem está em maior risco. Ainda assim, as melhores ferramentas de IA exigem grandes quantidades de dados de pacientes, e hospitais não podem simplesmente consolidar seus registos por causa de leis rígidas de privacidade e preocupações éticas. Este artigo revisa mais de uma década de pesquisas sobre o aprendizado “descentralizado” — formas de hospitais treinarem IA em conjunto sem nunca compartilhar os dados brutos dos pacientes — e faz uma pergunta prática: quão bem essas metodologias que preservam a privacidade realmente se saem em comparação com abordagens tradicionais?
Novas maneiras de aprender com pacientes protegendo a privacidade
No aprendizado centralizado tradicional, os hospitais copiam todos os seus dados para um grande banco de dados e treinam um único modelo ali. No aprendizado local, cada instituição constrói seu próprio modelo com seus próprios dados, sem colaboração. O aprendizado descentralizado oferece um caminho intermediário. No aprendizado federado, por exemplo, cada hospital treina um modelo localmente e então apenas os parâmetros do modelo (como os “botões” em uma rede neural) são enviados para serem combinados em um modelo compartilhado; os registros dos pacientes nunca deixam o local. O swarm learning elimina o coordenador central e permite que as instituições troquem atualizações de modelo diretamente. Outras abordagens descentralizadas combinam previsões de múltiplos modelos locais ou dividem o modelo entre sites. Esses métodos foram testados em problemas que vão da detecção de câncer e diagnóstico de COVID‑19 a doenças cardíacas, diabetes, distúrbios cerebrais e condições psiquiátricas.
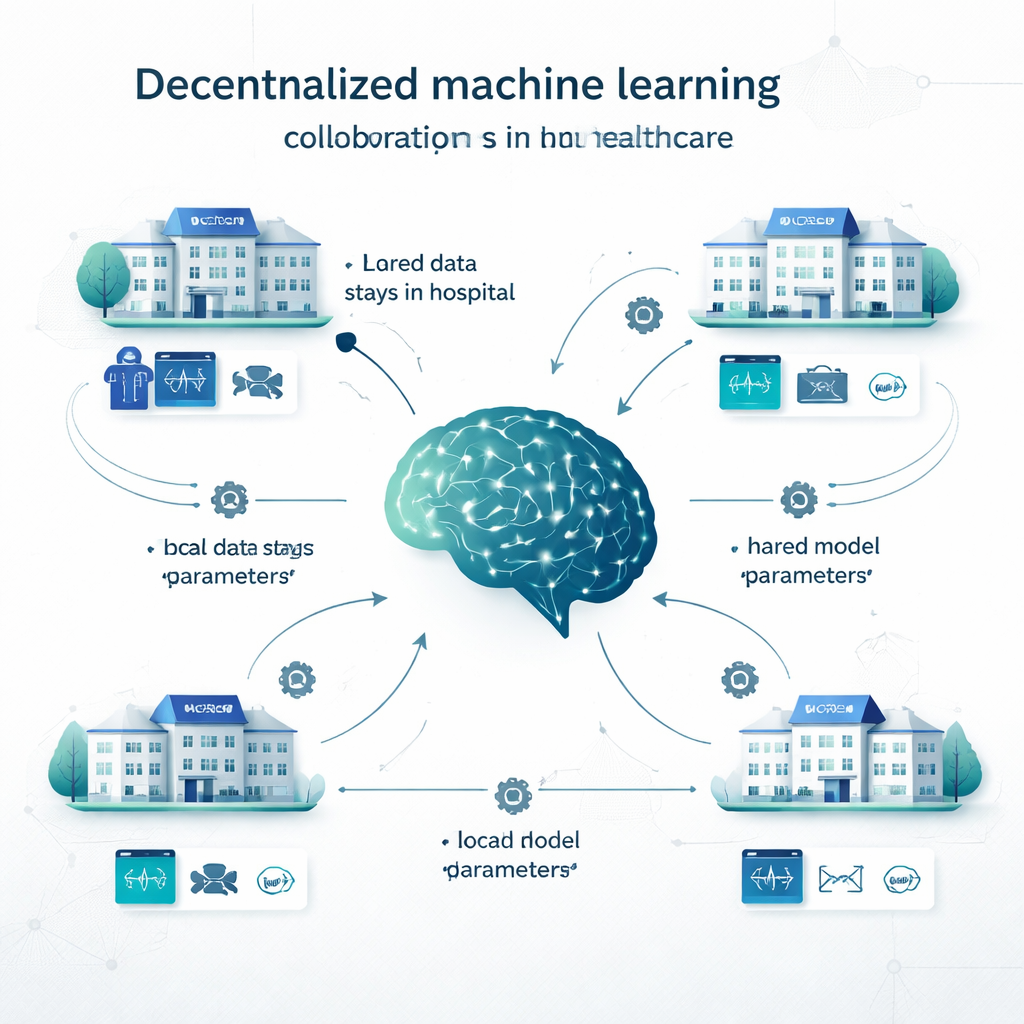
O que os pesquisadores examinaram
Os autores buscaram sistematicamente em 11 grandes bases de dados e triaram 165.010 estudos publicados entre 2012 e março de 2024. Após remover duplicatas e estudos que não envolviam decisões clínicas reais, 160 artigos permaneceram. Juntos, esses trabalhos relataram 710 modelos descentralizados e 8.149 comparações diretas de desempenho contra modelos centralizados ou locais. A maioria dos estudos focou em diagnóstico, mas houve também muitos sobre segmentação de imagens (por exemplo, contorno de tumores), predição de desfechos futuros como sobrevida ou complicações, e tarefas combinadas. Os tipos de dados cobriram quase todas as fontes principais usadas na medicina: prontuários eletrônicos, tomografias e ressonâncias (CT e MRI), raios-X, lâminas de patologia digital, sinais cardíacos e cerebrais e até dados genéticos.
Como modelos que preservam a privacidade se comparam à IA centralizada
Quando modelos descentralizados foram comparados com modelos centralizados treinados em dados agregados, o aprendizado centralizado geralmente teve desempenho ligeiramente superior. Ele se saiu especialmente bem em medidas “baseadas em limiar”, como acurácia e uma métrica comum em imagem chamada coeficiente de Dice, vencendo em cerca de três quartos dos casos e por uma margem suficiente para ser considerada uma vantagem moderada a grande. No entanto, para medidas de ordenação — como a área sob a curva ROC (AUROC), que captura quão bem um modelo ordena pacientes do menor ao maior risco — modelos descentralizados e centralizados ficaram muito mais próximos, com apenas uma pequena vantagem para o treinamento centralizado. Importante notar que, quando ambos os modelos atingiam o que os autores chamam de desempenho “clinicamente viável” (uma pontuação de pelo menos 0,80), o ganho típico do modelo centralizado foi modesto: muitas vezes inferior a 1–1,5 pontos percentuais. Em muitas situações isso se traduzia em “excelente versus aceitável”, não em “utilizável versus inútil”.
Por que o aprendizado descentralizado supera ir sozinho
O sinal mais forte na revisão emergiu ao comparar modelos descentralizados com puramente locais. Em todas as métricas principais — acurácia, AUROC, F1, sensibilidade, especificidade e, especialmente, precisão — métodos descentralizados quase sempre se saíram melhor, frequentemente por ampla margem. Em testes diretos, o aprendizado descentralizado superou os modelos locais em mais de 80% das comparações para medidas-chave como acurácia, precisão e AUROC. Em muitos casos, modelos locais não alcançaram o limiar de 0,80 para utilidade clínica, enquanto o modelo descentralizado correspondente o ultrapassou confortavelmente, melhorando a sensibilidade em até 27 pontos percentuais. Os autores atribuem isso à experiência ampliada que modelos multi-site ganham: ao “ver” padrões de muitos hospitais, tornam‑se menos enganados por peculiaridades específicas de scanners ou de registros e mais sintonizados com características da doença que realmente generalizam.
Equilibrando desempenho, privacidade e uso prático
A revisão conclui que o aprendizado centralizado permanece o padrão-ouro quando regras de privacidade e logística permitem combinar dados e quando cada fração de ponto percentual em desempenho importa, como em doenças muito raras. No entanto, o aprendizado descentralizado oferece uma alternativa poderosa e clinicamente aceitável para situações em que o compartilhamento de dados é restringido por leis como o GDPR e a AI Act da UE, ou por políticas institucionais. Comparado a manter modelos inteiramente locais, abordagens descentralizadas fornecem grandes ganhos em acurácia e confiabilidade ao mesmo tempo em que mantêm os dados dentro das paredes do hospital. Os autores defendem que trabalhos futuros relatem mais claramente as técnicas de privacidade e os custos computacionais, para que sistemas de saúde possam fazer escolhas informadas sobre quando pequenos trade‑offs de desempenho valem os benefícios substanciais em privacidade e colaboração.
Citação: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Palavras-chave: aprendizado federado, IA em saúde, privacidade de dados médicos, aprendizado de máquina descentralizado, modelos de predição clínica