Clear Sky Science · pt
Generalização da segmentação automática de tumor em imagens de lâminas inteiras histopatológicas através de múltiplos tipos de câncer
Por que isso importa para o cuidado do câncer
O diagnóstico do câncer ainda depende de especialistas que examinam cuidadosamente lâminas de vidro com tecido corado ao microscópio — uma tarefa demorada, agravada pelo aumento do número de casos e pela escassez de patologistas. Este estudo faz uma pergunta simples, porém poderosa: será que um único sistema de inteligência artificial pode identificar de forma confiável áreas cancerosas em imagens digitais de microscópio para muitos tipos diferentes de tumor, em vez de construir uma ferramenta separada para cada câncer? Se sim, isso poderia aliviar cargas de trabalho, acelerar o diagnóstico e estender análises avançadas até mesmos para cânceres mais raros, onde os dados são escassos.
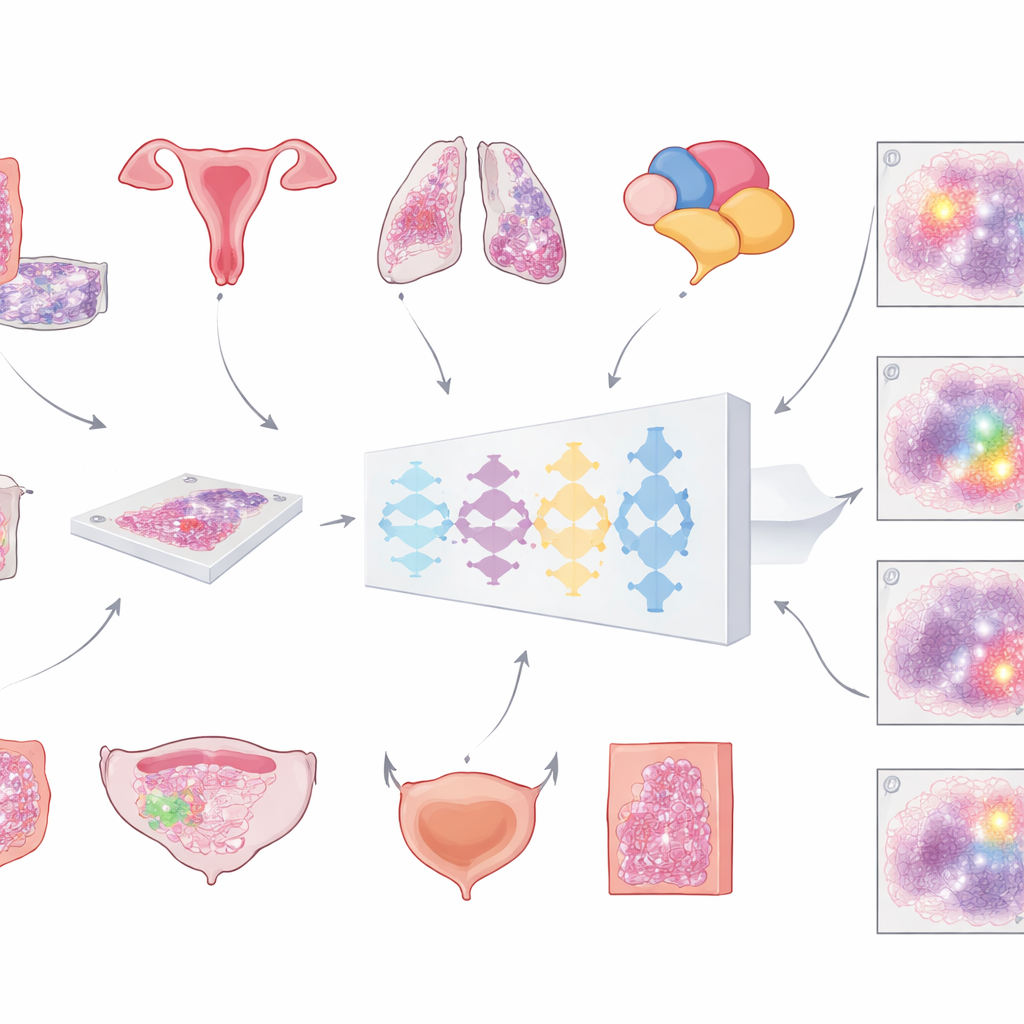
Das lâminas de vidro aos assistentes digitais
Hospitais modernos estão cada vez mais digitalizando lâminas de microscópio para criar enormes e detalhadas “imagens de lâmina inteira” dos tumores. O primeiro passo crucial para qualquer análise computadorizada é separar o tecido canceroso de todo o resto — células normais, gordura, vidro vazio e artefatos. Até agora, a maioria das ferramentas automatizadas foi treinada em um único tipo de câncer, limitando onde podem ser usadas. A equipe por trás deste trabalho propôs construir um único modelo universal capaz de identificar regiões tumorais em múltiplos cânceres comuns em lâminas coradas com os corantes rotina hematoxilina e eosina. A visão era uma ferramenta geral que pudesse ser integrada a muitos fluxos de trabalho diagnósticos sem precisar ser redesenhada a cada vez.
Treinando um modelo para ver muitos cânceres
Para construir esse modelo, os pesquisadores reuniram uma coleção incomumente grande e variada de lâminas digitais: mais de 20.000 imagens de lâmina inteira de mais de 4.000 pacientes com câncer colorretal, endometrial, pulmonar e de próstata. Todas as amostras vieram de tecido fixado em formalina e incluído em parafina, escaneadas em dois scanners de lâminas de alta resolução distintos. Um patologista delineou cuidadosamente as áreas tumorais em cada lâmina, fornecendo a “verdade de referência” a partir da qual o computador aprenderia. O modelo seguiu um pipeline em vários passos: cada imagem enorme foi dividida em grandes blocos sobrepostos, passada por uma rede neural profunda que estimava, para cada pixel, a probabilidade de ser tumor, e então remontada em um mapa suave que por fim era convertido em uma máscara limpa de tumor versus não tumor.
Colocando o sistema à prova
De forma crucial, a equipe não se limitou ao desempenho em treinamento. Eles testaram o mesmo modelo em mais de 3.000 pacientes adicionais em seis tipos de câncer — incluindo cânceres de mama e bexiga que nunca foram usados no treinamento — e em lâminas de múltiplos hospitais e scanners. A acurácia foi medida principalmente com uma pontuação de sobreposição padrão (coeficiente Dice), que atinge 100% quando o contorno do tumor pelo computador corresponde perfeitamente ao do patologista. Para amostras tumorais grandes e preservadas em cânceres colorretal, endometrial, pulmonar, de próstata e de mama, a sobreposição média excedeu 80% e frequentemente 90%. Em grandes coleções externas do The Cancer Genome Atlas, oriundas de muitos laboratórios e scanners no mundo todo, o desempenho também se manteve acima de 80%, sugerindo que o modelo se generaliza bem além de sua instituição de origem.
Onde ele tem dificuldade e como se compara
A principal fraqueza surgiu em cânceres iniciais da bexiga amostrados por um procedimento que produz pequenos fragmentos de tecido. Nesses casos, o modelo frequentemente deixou de marcar qualquer tumor, especialmente quando a área cancerosa era muito pequena. Ainda assim, quando detectou tumor, a sobreposição com os contornos do patologista foi alta, e ajustes simples nos limiares finais melhoraram os resultados — indicando que a rede subjacente reconhecia o padrão, mas o pós‑processamento era demasiado rígido. Os pesquisadores também construíram quatro modelos “especialistas”, cada um treinado em um único tipo de câncer, e constataram que nenhum superou de forma significativa o modelo geral em seu próprio domínio. Em contraste, esses sistemas especialistas falharam amplamente quando aplicados a outros tipos de câncer, enquanto o modelo geral permaneceu robusto. Comparado a uma ferramenta de segmentação médica genérica e popular que requer sugestões do usuário, o novo modelo geralmente teve desempenho igual ou melhor, permanecendo totalmente automático.
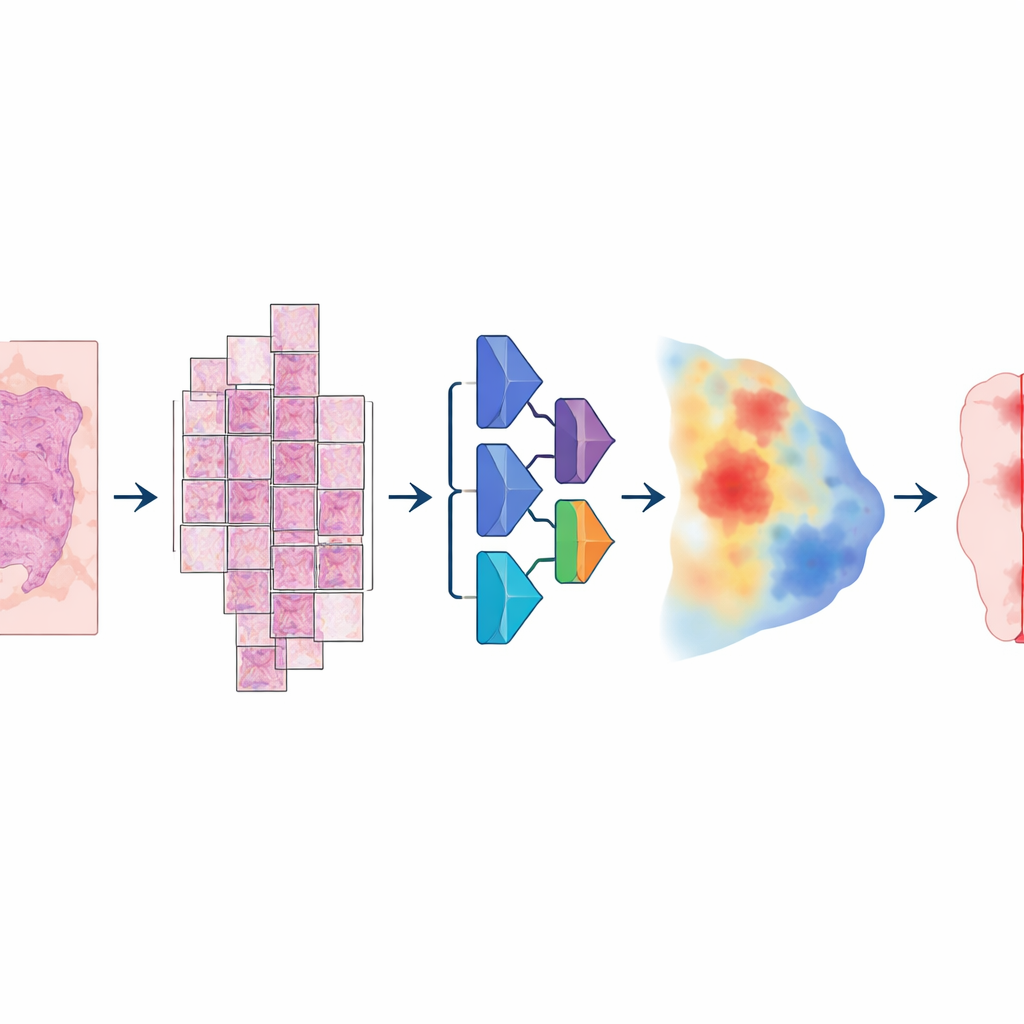
O que isso significa para pacientes e médicos
Para não especialistas, a conclusão principal é que um sistema de IA bem projetado pode destacar de forma confiável tecido canceroso em lâminas digitais através de vários tipos tumorais importantes, sem precisar de versões personalizadas para cada doença ou scanner. Ele não substitui o patologista, mas pode pré‑marcar regiões prováveis de tumor, apoiar medidas consistentes e liberar especialistas para se concentrarem nos casos mais desafiadores. A versão atual ainda perde alguns tumores muito pequenos ou em estágios iniciais — particularmente amostras fragmentadas da bexiga e provavelmente outros tecidos semelhantes a biópsia — portanto ainda não é adequada para detectar os vestígios mais tênues de câncer. Ainda assim, o estudo mostra que a segmentação tumoral ampla, “pancâncer”, é viável em condições do mundo real e pode formar um primeiro passo robusto para futuras ferramentas automatizadas que avaliem grau tumoral, prevejam resposta a tratamentos ou orientem terapias de precisão.
Citação: Skrede, OJ., Pradhan, M., Isaksen, M.X. et al. Generalisation of automatic tumour segmentation in histopathological whole-slide images across multiple cancer types. npj Precis. Onc. 10, 107 (2026). https://doi.org/10.1038/s41698-026-01311-6
Palavras-chave: patologia digital, aprendizado profundo, segmentação de tumor, imagens de lâmina inteira, modelo pancâncer