Clear Sky Science · pt
IMFLKD: um mecanismo de incentivos para aprendizado federado descentralizado baseado em destilação de conhecimento
Por que Compartilhar Pode Ser Seguro e Justo
A inteligência artificial moderna se alimenta de dados, no entanto a maior parte dos nossos dados permanece em celulares pessoais, servidores hospitalares ou nuvens empresariais que não podem ser simplesmente copiadas e compartilhadas. O aprendizado federado oferece uma maneira para muitos dispositivos treinarem um modelo compartilhado sem expor seus dados brutos, mas os sistemas atuais ainda enfrentam vazamentos de privacidade, pontos centrais de falha e recompensas injustas para quem mais contribui. Este artigo apresenta um novo framework, IMFLKD, que combina três ideias poderosas — blockchain, destilação de conhecimento e pontuação de reputação — para tornar esse tipo de aprendizado coletivo mais privado, mais robusto e mais justo no longo prazo.
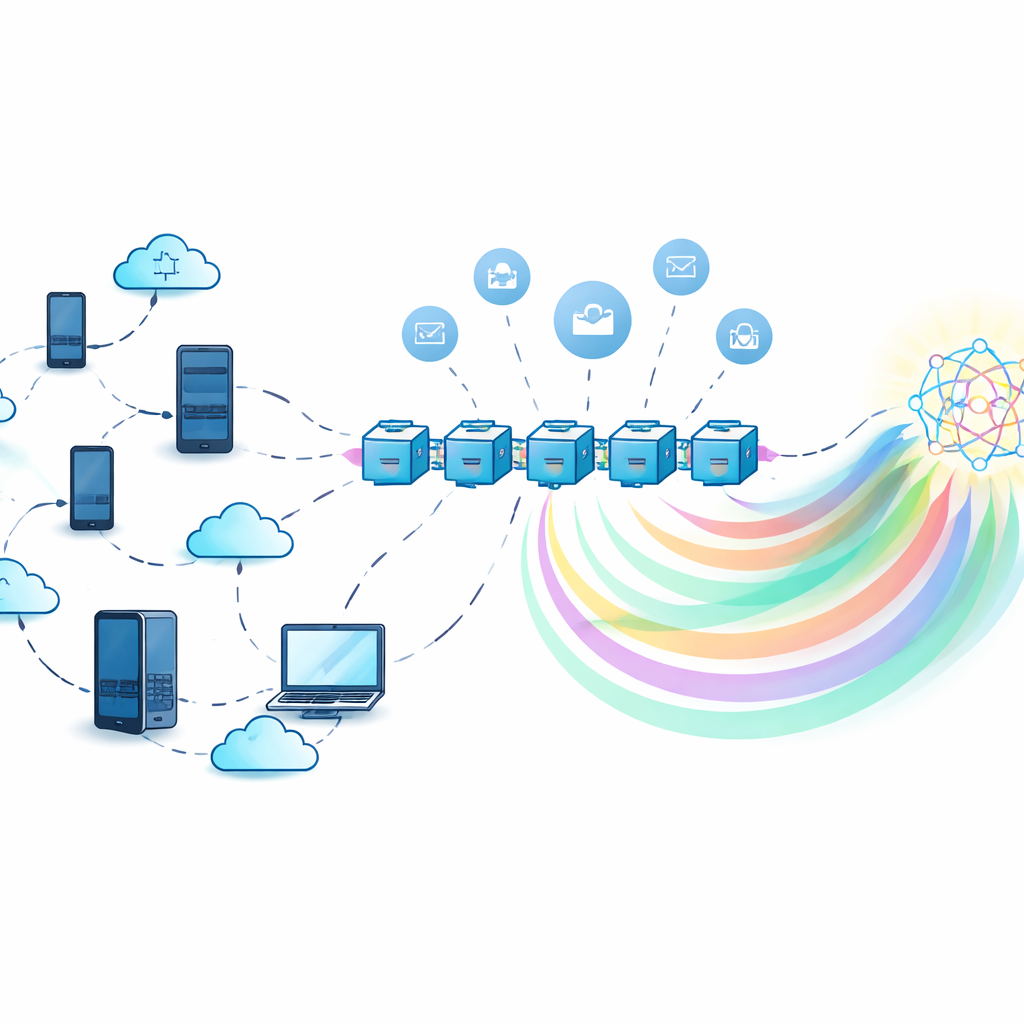
Treinar Juntos Sem Compartilhar Segredos
No aprendizado federado clássico, um servidor central coleta atualizações de modelo de muitos participantes e as combina. Isso evita o trânsito de dados brutos, mas o próprio servidor se torna um alvo atraente: se ele falhar, todo o sistema para, e se for não confiável, pode usar ou vazar informações ocultas nas atualizações do modelo. Os autores, em vez disso, usam um registro descentralizado em blockchain para coordenar o treinamento. Cada participante treina um modelo local em seus próprios dados e então interage com contratos inteligentes na blockchain que registram contribuições, agregam informações e distribuem recompensas, tudo sem depender de uma única autoridade central.
Compartilhando Conhecimento, Não Modelos Pesados
Para reduzir custos de comunicação e proteger ainda mais a privacidade, o framework se apoia na destilação de conhecimento. Em vez de enviar parâmetros completos do modelo, cada participante envia apenas “rótulos suaves” — as probabilidades previstas pelo modelo para um conjunto de entradas compartilhadas — que são muito mais leves e revelam menos sobre os dados de qualquer pessoa. Como um conjunto de dados compartilhado real pode não existir, o sistema usa um modelo generativo chamado autoencoder variacional condicional para criar um conjunto sintético “pseudo-público” que aproxima a distribuição geral de rótulos sem expor registros originais. Os participantes treinam em seus próprios dados, fazem previsões nesse conjunto sintético e então refinam seus modelos usando um sinal agregado derivado do conhecimento combinado de todos.
Medição de Quem Realmente Ajuda
Um desafio central em qualquer sistema colaborativo é decidir quem merece crédito. O IMFLKD enfrenta isso com um método de avaliação de contribuição em duas etapas baseado na agregação de rótulos. Primeiro, um algoritmo bayesiano leve examina as previsões de todos os participantes e infere tanto o rótulo mais provável para cada amostra quanto uma pontuação de qualidade para cada modelo, atualizando essas pontuações à medida que novas tarefas chegam. Essa abordagem funciona online, sem armazenar dados passados, e lida com contribuidores ruidosos ou maliciosos ao reduzir o peso de modelos que frequentemente discordam do consenso emergente. Experimentos mostram que essa agregação de rótulos melhora a acurácia em cerca de 10% em comparação com votação majoritária simples, mantendo-se rápida o suficiente para ambientes de grande escala e recursos limitados.
Convertendo Qualidade em Recompensas e Reputação
Uma vez conhecida a qualidade da contribuição, o IMFLKD usa um esquema de incentivos chamado soro da verdade ponderado pelos pares para transformá-la em recompensas. Os participantes são comparados com um consenso ponderado pela qualidade dos pares: aqueles cujas previsões se alinham com pares de alta qualidade ganham mais, enquanto os que se desviam ou frequentemente discordam são penalizados. Isso torna a declaração honesta a estratégia mais lucrativa no longo prazo, mesmo diante de conluio. Além disso, o sistema constrói uma pontuação de reputação multidimensional para cada participante, combinando qualidade de dados, nível de atividade e estabilidade comportamental, e ajustando comportamentos antigos com um fator de decaimento temporal. A reputação então retroalimenta as rodadas seguintes, influenciando quanto peso as previsões de um participante têm e se eles são selecionados para tarefas futuras.
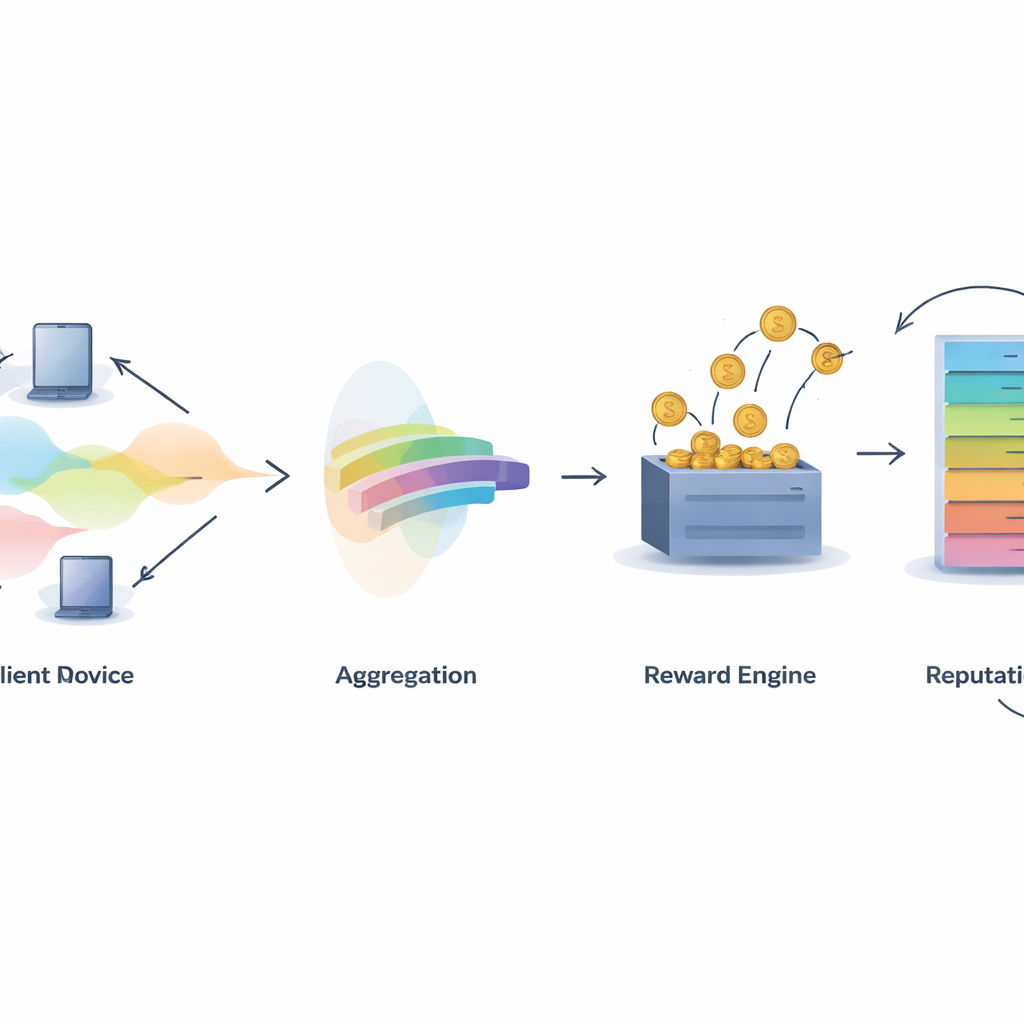
Construindo Confiança na Inteligência Coletiva
No geral, o framework IMFLKD demonstra que é possível coordenar o aprendizado entre muitos dispositivos independentes de forma eficiente, atenta à privacidade e resistente a aproveitadores e atacantes. Ao combinar geração de dados sintéticos, pontuação rigorosa de contribuições, recompensas com base em teoria dos jogos e rastreamento dinâmico de reputação em uma blockchain, o sistema incentiva os participantes a se comportarem de maneira honesta e consistente ao longo de muitas rodadas de treinamento. Para o público em geral, a conclusão é que podemos aproveitar o poder coletivo de dados distribuídos — como prontuários médicos, leituras de sensores ou dispositivos pessoais — sem entregar tudo a uma única empresa ou servidor, garantindo que quem fornece as informações mais úteis seja quem mais se beneficia.
Citação: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Palavras-chave: aprendizado federado, blockchain, destilação de conhecimento, mecanismos de incentivo, sistemas de reputação