Clear Sky Science · pt
PlantCLR: pré-treinamento autossupervisionado contrastivo para detecção de doenças em plantas mais generalizável
Por que identificar doenças nas plantas de forma mais inteligente é importante
Doenças de plantas silenciosamente roubam comida da mesa do mundo, reduzindo a produtividade das colheitas e afetando a renda dos agricultores. Em muitas regiões, há apenas alguns especialistas treinados disponíveis para identificar problemas no campo, e obter sua ajuda pode ser lento ou impossível. Este estudo apresenta o PlantCLR, um sistema computacional que aprende a reconhecer doenças a partir de fotos de folhas com muito menos rótulos fornecidos por humanos do que o habitual. Ao tornar o diagnóstico automatizado mais preciso, confiável e fácil de implantar em hardware modesto, o trabalho aponta para ferramentas baseadas em smartphones ou câmeras de baixo custo que poderiam ajudar agricultores a detectar problemas precocemente e proteger suas colheitas.
De fotos de folhas a avisos precoces
Hoje, muitas doenças de plantas são diagnosticadas do modo tradicional: uma pessoa observa uma folha e decide se manchas, amarelamento ou curvamento são sinais de infecção. Esse julgamento pode variar entre especialistas e é facilmente prejudicado por sombras, fundos confusos ou diferentes estágios de crescimento. Sistemas de visão computacional baseados em deep learning começaram a ajudar, mas normalmente exigem dezenas de milhares de fotos cuidadosamente rotuladas. Na agricultura, essas imagens rotuladas são escassas e caras de coletar, enquanto enormes quantidades de imagens não rotuladas de telefones celulares e câmeras de campo muitas vezes ficam sem uso. O PlantCLR foi projetado para aproveitar esses dados não rotulados, aprendendo como folhas doentes e saudáveis tendem a parecer antes mesmo de ver qualquer rótulo.
Ensinar um modelo a aprender por comparação
O PlantCLR se baseia em uma abordagem recente chamada aprendizado contrastivo autossupervisionado, na qual um modelo se ensina comparando imagens em vez de ler rótulos. Primeiro, o sistema pega uma imagem de folha não rotulada e cria duas versões ligeiramente diferentes por meio de cortes aleatórios, reflexões, alterações de cor ou desfoque. Essas duas versões devem representar claramente a mesma folha, então o modelo é treinado para tratá‑las como um par correspondente e dar-lhes representações internas semelhantes, ao mesmo tempo em que afasta as representações de folhas diferentes no mesmo lote de treinamento. Essa etapa de pré-treinamento usa um backbone compacto, porém moderno, de processamento de imagens chamado ConvNeXt‑Tiny, emparelhado com um pequeno módulo extra usado apenas durante essa fase de aprendizado por comparação. 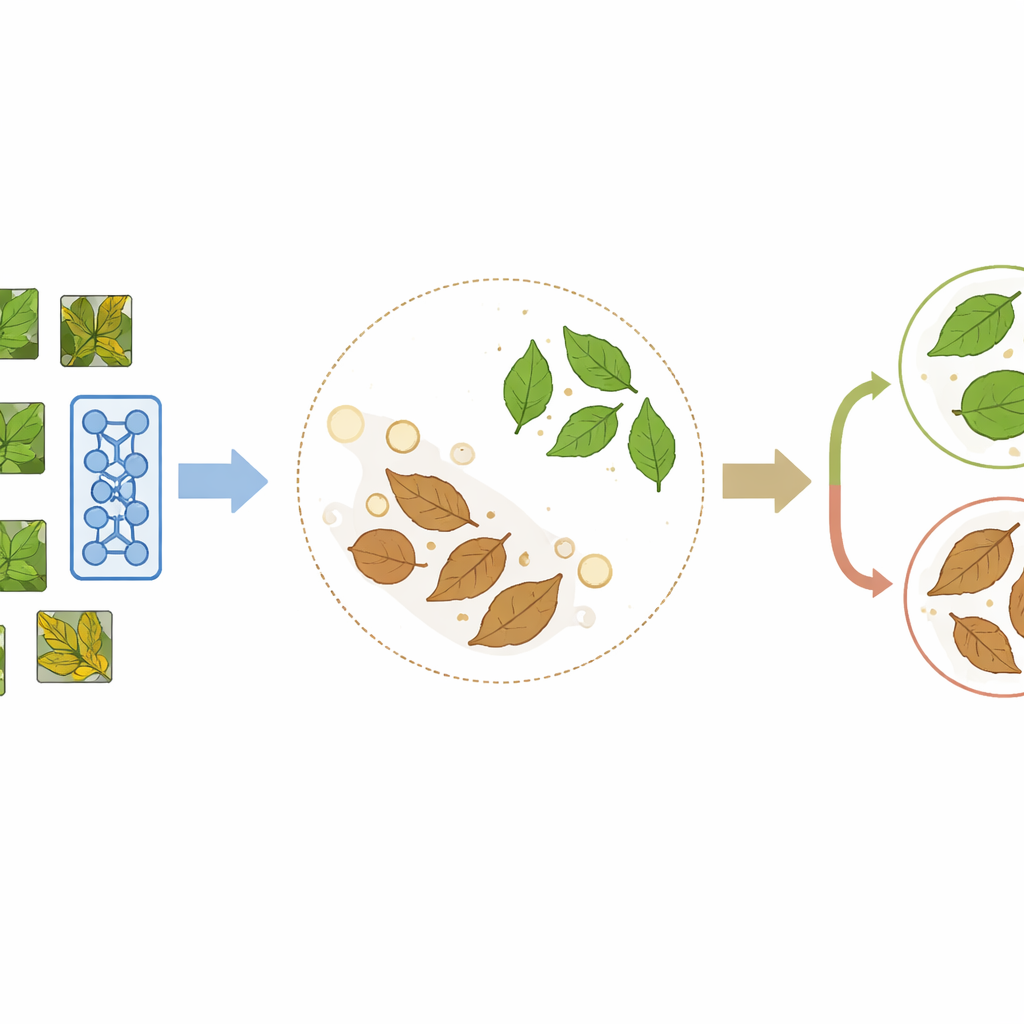
Colocando o sistema à prova
Para testar quão bem essa estratégia funciona na prática, os autores recorreram a dois conjuntos de folhas populares que simulam cenários do mundo real bastante diferentes. O conjunto PlantVillage contém mais de 54.000 imagens de folhas fotografadas em condições organizadas e controladas, geralmente com fundos limpos e sintomas claros em 38 categorias de doenças e culturas. Em contraste, o conjunto Cassava Leaf Disease contém cerca de 21.000 imagens de folhas de mandioca feitas diretamente no campo, com fundos bagunçados, iluminação desigual e folhas que se sobrepõem ou se torcem em muitas direções, em cinco classes que incluem várias infecções virais e bacterianas graves. O estudo usa o PlantVillage principalmente como uma fonte rica de imagens não rotuladas para pré-treinamento e então avalia o desempenho tanto nesse conjunto quanto, mais criticamente, nas fotos de mandioca de estilo de campo, mais desafiadoras.
Desempenho robusto em condições variáveis
O PlantCLR alcançou 99,10% de acurácia no conjunto de teste PlantVillage e 96,83% de acurácia no conjunto de teste Cassava, com pontuações F1 igualmente altas que mostram que o modelo se sai bem mesmo em doenças menos comuns. Esses números superam uma série de redes profundas conhecidas, incluindo DenseNet, ResNet, VGG e um modelo vision transformer, todos treinados de forma puramente supervisionada em condições cuidadosamente pareadas. 
Por que essa abordagem é um avanço
Para não especialistas, a mensagem principal é que o PlantCLR mostra como uma máquina pode se tornar um médico competente de plantas ao primeiro aprender com grandes coleções de imagens não rotuladas e depois refinar suas habilidades com um conjunto menor e rotulado. Essa estratégia não só alcança acurácia muito alta como também se mantém robusta quando a câmera sai do laboratório e vai para o campo, onde as condições são muito menos ordenadas. Como o modelo subjacente é relativamente leve, ele pode eventualmente ser implantado em hardware acessível, tornando a detecção avançada de doenças mais disponível para agricultores e agentes de extensão em todo o mundo. Em resumo, o estudo demonstra um caminho prático para ferramentas de monitoramento da saúde das plantas escaláveis, robustas e eficientes em rótulos, que poderiam ajudar a proteger o abastecimento de alimentos.
Citação: Shah, S.S.A., Saeed, F., Raza, M.U. et al. PlantCLR: contrastive self-supervised pretraining for generalizable plant disease detection. Sci Rep 16, 10550 (2026). https://doi.org/10.1038/s41598-026-45684-x
Palavras-chave: detecção de doenças em plantas, aprendizado autossupervisionado, aprendizado contrastivo, IA agrícola, monitoramento da saúde das culturas