Clear Sky Science · pt
Treinamento híbrido evolutivo-gradiente melhora previsões de séries temporais de longo prazo
Por que previsões de longo alcance melhores importam
Da demanda por eletricidade e do tráfego rodoviário até taxas de câmbio e o tempo local, nossas vidas são moldadas por sistemas que evoluem ao longo do tempo. Prever com precisão esses padrões dias ou semanas à frente pode economizar energia, reduzir congestionamentos e tornar empresas mais resilientes. Mas quanto mais longe olhamos para o futuro, mais difícil fica para as ferramentas de inteligência artificial atuais lidarem com condições transitórias, medições ruidosas e orçamentos de computação limitados. Este artigo apresenta uma nova forma de treinar modelos de previsão para que permaneçam precisos e estáveis mesmo quando o mundo se recusa a ficar parado.
Aprender a partir de muitos modelos em vez de apenas um
A maioria dos preditores modernos de séries temporais depende de uma única rede neural profunda treinada com descida de gradiente, o método padrão que ajusta parâmetros passo a passo para reduzir o erro. Isso funciona bem quando os dados se comportam de forma consistente, mas pode falhar quando as condições mudam, as medições são ruidosas ou o tempo de treinamento é curto. Em vez de inventar um novo projeto de rede, os autores propõem Evolutionary‑Guided Module Fusion with Gradient Refinement (EGMF‑GR), uma estrutura de treinamento que pode envolver arquiteturas existentes. A ideia central é manter uma pequena “população” de modelos que compartilham a mesma estrutura mas começam de configurações randômicas diferentes. Durante o treinamento, esses modelos exploram maneiras distintas de ajustar os dados, e o que estiver com melhor desempenho em cada momento é usado para orientar melhorias nos demais.
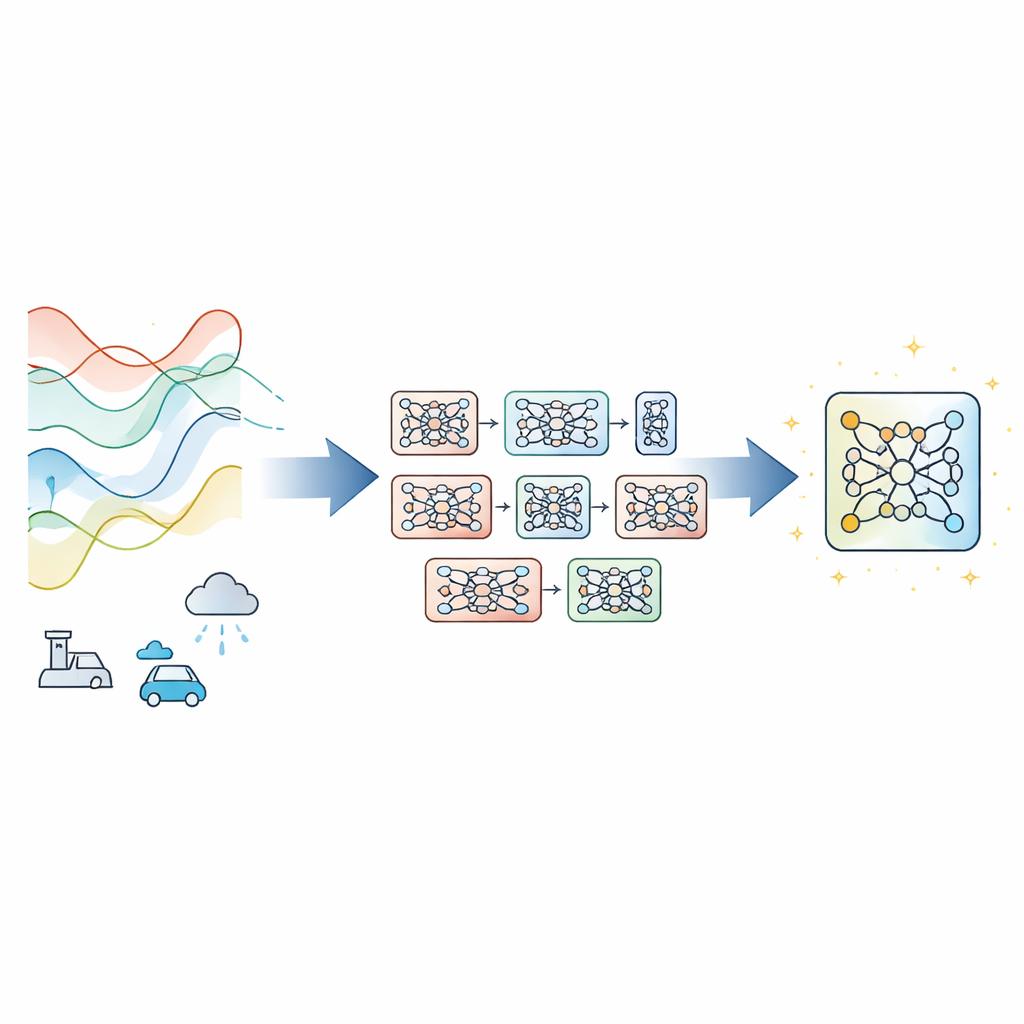
Tomando emprestado boas partes enquanto se preserva diversidade útil
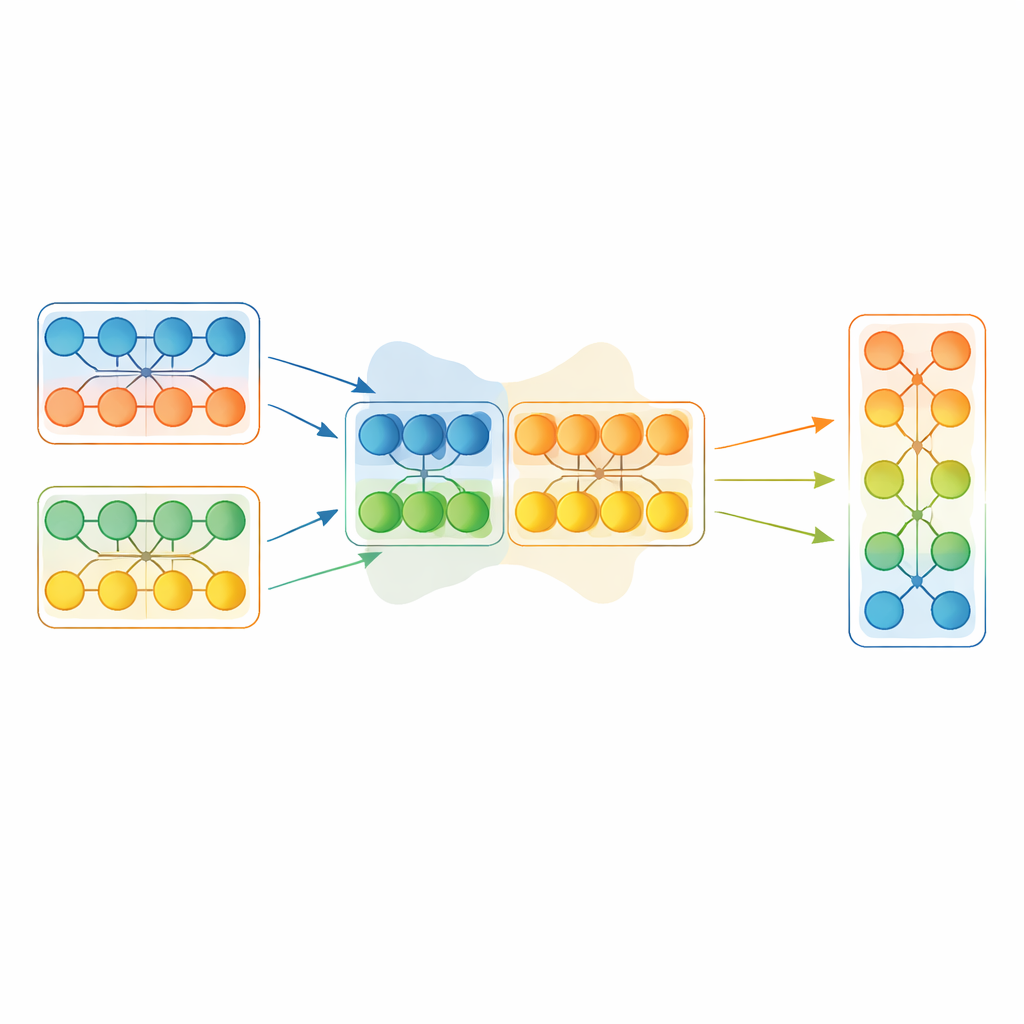
Em vez de copiar integralmente um modelo vencedor, o EGMF‑GR opera ao nível de módulos—blocos de construção repetidos dentro de uma rede, como pilhas de camadas. Para cada modelo na população, a estrutura alinha módulos correspondentes com aqueles do modelo atual com melhor desempenho e compara seus sinais internos enquanto processam o mesmo lote de entrada. Usa várias medidas simples de diferença, capturando tanto como os padrões de atividade são moldados quanto sua amplitude. Essas discrepâncias por módulo são então resumidas, e apenas módulos cujo comportamento se mostra outlier forte em relação aos pares são considerados para atualização. Quando isso acontece, o módulo atrasado é levado na direção do módulo correspondente do melhor modelo por meio de uma mistura ponderada de seus parâmetros, além de uma pequena perturbação aleatória para preservar a diversidade.
Deixando os gradientes arrumarem depois das grandes mudanças
Mesclar partes de diferentes redes pode introduzir alterações abruptas. Para evitar desestabilizar o treinamento, cada modelo fundido passa então por uma curta fase convencional de descida de gradiente sobre os dados de treinamento. Essa etapa de refinamento permite que a rede se readapte suavemente à sua nova configuração interna ao mesmo tempo em que mantém os benefícios do conhecimento emprestado. O procedimento geral alterna: selecionar o modelo atual com melhor desempenho com base em uma fatia retida de dados, fundir seletivamente módulos desse líder no restante da população e afinar brevemente todos com gradientes. De modo crucial, o método também sincroniza estados internos de manutenção, como médias móveis usadas por certas camadas, que costumam ser ignorados em esquemas mais simples de mesclagem de modelos mas podem afetar muito a estabilidade.
Comprovando ganhos em muitos sinais do mundo real
Para testar a estrutura, os autores aplicaram EGMF‑GR a vários backbones populares de previsão, incluindo modelos no estilo Transformer e um desenho recente baseado em convolução, sem alterar suas estruturas centrais. Avaliaram o desempenho em oito benchmarks públicos que abrangem uso de energia, fluxo de tráfego, taxas de câmbio e clima, e em múltiplos horizontes de previsão que vão de poucas horas a vários dias à frente. Sob um orçamento estritamente igualado de atualizações custosas por retropropagação, o treinamento híbrido reduziu consistentemente os erros de previsão e suavizou o comportamento de treinamento para a maioria das combinações modelo–conjunto de dados, especialmente em cenários de alta dimensionalidade ou com ruído. A equipe também comparou sua abordagem com truques comuns de modelo único, como médias móveis exponenciais e averaging estocástico de pesos, e constatou que a fusão de módulos baseada em população trouxe benefícios adicionais além do simples suavizar de pesos.
Continuar confiável quando as condições ficam ruins
Sistemas reais raramente se comportam como exemplos limpos de livro-texto, por isso os autores também testaram robustez em cenários mais difíceis: entradas corrompidas artificialmente, trechos ausentes de dados e períodos em que a dinâmica subjacente muda abruptamente. O EGMF‑GR ajudou claramente quando as entradas eram ruidosas ou parcialmente ausentes, sugerindo que emprestar comportamento de módulos estáveis do melhor modelo atual pode contrabalançar falhas locais. Durante mudanças de regime súbitas, a vantagem foi menor, indicando que alinhamentos excessivos às vezes podem retardar a adaptação a novos padrões. Isso aponta para refinamentos futuros nos quais a intensidade da fusão é reduzida quando o ambiente se torna altamente volátil.
O que isso significa para ferramentas de previsão do dia a dia
Em termos simples, o estudo mostra que treinar muitas versões cooperativas do mesmo modelo de previsão, permitindo que compartilhem apenas as partes que realmente se destacam como melhores, pode tornar previsões de longo alcance mais precisas e mais estáveis sem redesenhar os próprios modelos. O EGMF‑GR funciona como um esporte de equipe disciplinado: os membros ocasionalmente adotam os movimentos mais fortes uns dos outros e depois praticam um pouco por conta própria para se ajustar ao jogo atual. Para praticantes, isso oferece uma estratégia de treinamento plug‑in que pode reforçar sistemas de previsão existentes em finanças, energia, transporte e aplicações climáticas, especialmente quando os dados são confusos e os orçamentos de computação são apertados.
Citação: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Palavras-chave: previsão de séries temporais, treinamento evolutivo, redes neurais, fusão de modelos, mudança de distribuição