Clear Sky Science · pt
Detecção de troca de amostras em investigações antidoping usando aprendizado de máquina
Por que pegar trapaceiros astutos importa
O esporte de alto rendimento depende da confiança: quando um atleta vence, queremos acreditar que o resultado foi limpo. Testes modernos de drogas são muito sensíveis, ainda que alguns atletas tentem driblá‑los trocando secretamente amostras de urina. Este estudo mostra como o aprendizado de máquina pode identificar quando um atleta reutiliza uma amostra “limpa” coletada anteriormente, um truque extremamente difícil de detectar com as verificações rotineiras atuais. O trabalho aponta para novas formas de proteger a integridade esportiva, examinando discretamente enormes bancos de dados de testes em busca de evidências ocultas de manipulação.
Uma brecha oculta nos testes atuais
Laboratórios antidoping normalmente analisam urina, porque muitas substâncias proibidas e seus produtos de degradação permanecem detectáveis por muito tempo nesse fluido. Perfis de hormônios esteroides naturais dos atletas são acompanhados ao longo de anos no Passe Biomédico do Atleta, de modo que um salto repentino nesses valores pode desencadear uma investigação. A introdução da urina de outra pessoa rompe esse padrão de longo prazo e frequentemente é detectável. O ponto cego real surge quando um atleta reutiliza secretamente sua própria urina anterior, livre de drogas. Nesse caso, o padrão de esteroides se encaixa perfeitamente no histórico do atleta e, se a amostra for analisada em outro laboratório ou muito depois da original, não existe atualmente uma forma automática de perceber que duas amostras são essencialmente a mesma.
Transformando a química da urina em padrões pesquisáveis
Os autores abordaram esse problema ao se concentrar na detalhada “impressão digital” formada por um conjunto de esteroides naturais e suas razões na urina. Reuniram 67.651 perfis de esteroides de um laboratório credenciado pela Agência Mundial Antidoping (WADA) coletados entre 2021 e 2023, abrangendo atletas masculinos e femininos. Cada perfil contém hormônios-chave, como testosterona e vários compostos relacionados, além das razões entre eles. Como casos reais de reutilização de amostras são raros e confidenciais, a equipe combinou esses dados do mundo real com pares sintéticos cuidadosamente elaborados: alguns pares foram feitos “semelhantes” ao adicionar um ruído de medição pequeno e realista, e outros foram tornados “diferentes” ao combinar aleatoriamente amostras de atletas distintos. Isso forneceu material de treinamento balanceado para um modelo computacional aprender o que “quase idêntico” realmente significa na prática.
Como o detector inteligente funciona
O núcleo do sistema é um tipo de rede neural artificial conhecida como rede convolucional, amplamente usada em reconhecimento de imagens. Aqui, em vez de imagens, a entrada é um par de perfis de esteroides dispostos lado a lado. A rede varre as características para captar relações locais sutis, como o modo como dois hormônios e sua razão se movimentam em conjunto. Para tornar os dados mais gerenciáveis e interpretáveis, os pesquisadores também usaram uma técnica chamada análise de componentes principais para projetar todos os perfis em um espaço tridimensional, onde medidas simples de distância podem destacar correspondências próximas. Durante o treinamento, a rede aprende a fornecer uma probabilidade de que dois perfis provenham da mesma urina subjacente, distinguindo similaridade real das diferenças biológicas normais observadas entre atletas e ao longo do tempo.
Colocando o método à prova
A equipe avaliou a abordagem em várias frentes. Primeiro, testaram em dados reservados de cada ano, usando perfis que não haviam sido vistos durante o treinamento, mas foram perturbados dentro da incerteza de medição esperada de 15%. A rede convolucional obteve consistentemente alta acurácia, identificando corretamente pares semelhantes enquanto mantinha baixas taxas de alarme falso, e superou métodos mais tradicionais como regressão logística, máquinas de vetor de suporte e modelos baseados em árvores. Em seguida, desafiaram o sistema com mais de 800 amostras de “confirmação”—exemplares reais de urina que laboratórios tinham reanalisado sob procedimentos ligeiramente diferentes. Essas amostras servem como um substituto realista para repetições ou reutilizações. Novamente, a rede teve desempenho excelente tanto para homens quanto para mulheres, com sensibilidade (capturar correspondências verdadeiras) e especificidade (evitar correspondências espúrias) muito boas, sugerindo que ela lida bem com o ruído de laboratório real e a variação biológica.
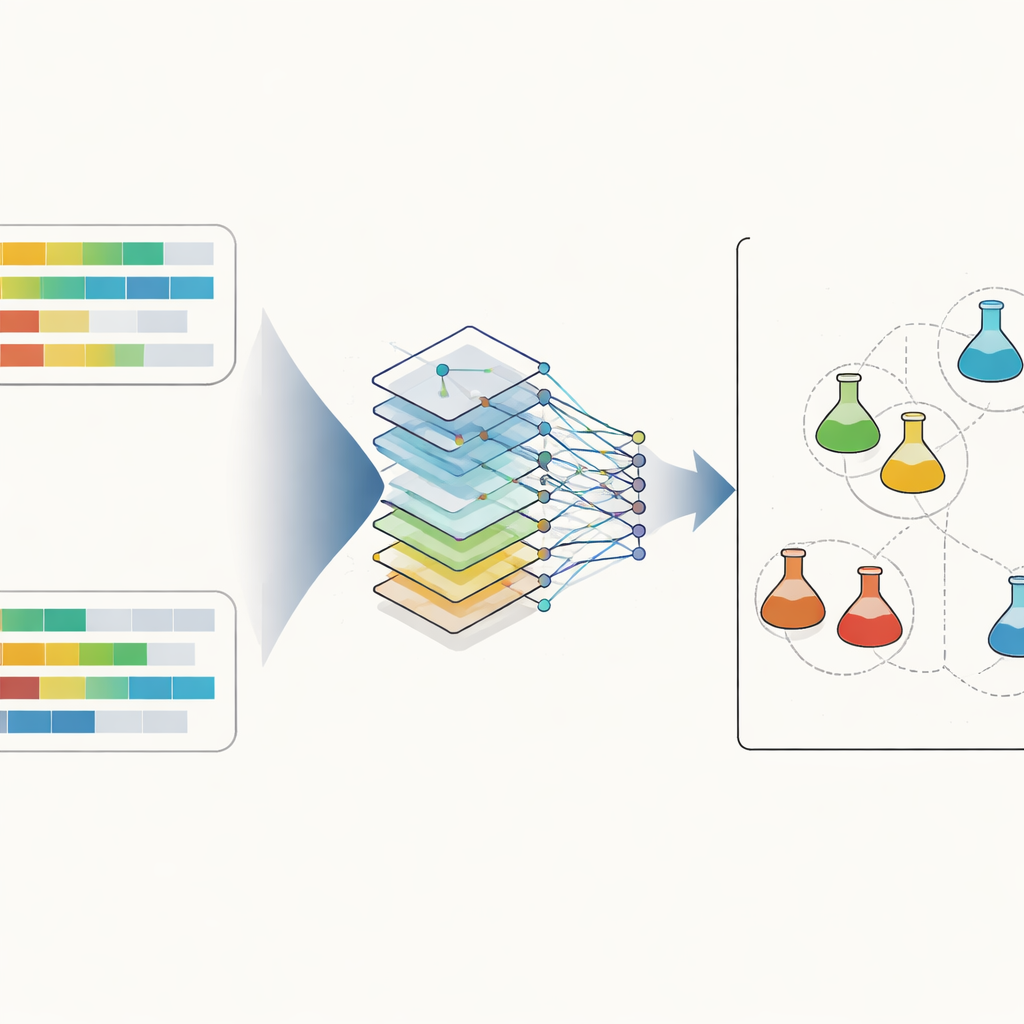
O que isso significa para um esporte limpo
Para não especialistas, a conclusão principal é que agora está se tornando viável vasculhar automaticamente vastos bancos de dados antidoping em busca de sinais de que uma amostra de urina supostamente nova é, na verdade, uma cópia quase perfeita de uma anterior. A estrutura de aprendizado de máquina proposta não substitui os testes existentes para substâncias proibidas; em vez disso, acrescenta uma verificação de fundo poderosa que pode sinalizar amostras suspeitamente semelhantes para uma revisão forense mais detalhada. Embora o método dependa em parte de dados simulados e utilize modelos complexos em formato “caixa‑preta” que não são totalmente transparentes, ele ainda oferece às autoridades esportivas uma ferramenta prática. Se integrado aos sistemas atuais do Passe Biomédico do Atleta, pode tornar a antes indetectável artimanha de reutilizar urina limpa muito mais arriscada, fortalecendo a confiança de que medalhas são conquistadas por mérito e não por manipulação.
Citação: Rahman, M.R., Piper, T., Thevis, M. et al. Detection of sample swapping in anti-doping investigations using machine learning. Sci Rep 16, 9230 (2026). https://doi.org/10.1038/s41598-026-43502-y
Palavras-chave: antidoping, perfis de esteroides na urina, troca de amostras, aprendizado de máquina, integridade esportiva