Clear Sky Science · pt
Repensar a engenharia de contexto usando uma arquitetura baseada em atenção
Por que ajudantes de software mais inteligentes importam
Cada clique que você dá em um aplicativo corporativo — fazer login, enviar um arquivo, rodar um relatório — deixa um rastro. Se o software pudesse prever com confiabilidade seu próximo movimento, ele poderia carregar dados antecipadamente, sugerir atalhos e responder quase instantaneamente. Este artigo explora uma nova maneira de ensinar computadores a entender tão bem esses rastros de ações que assistentes digitais possam antecipar o que você fará em seguida, o que você está tentando alcançar e quando está prestes a encerrar a sessão.
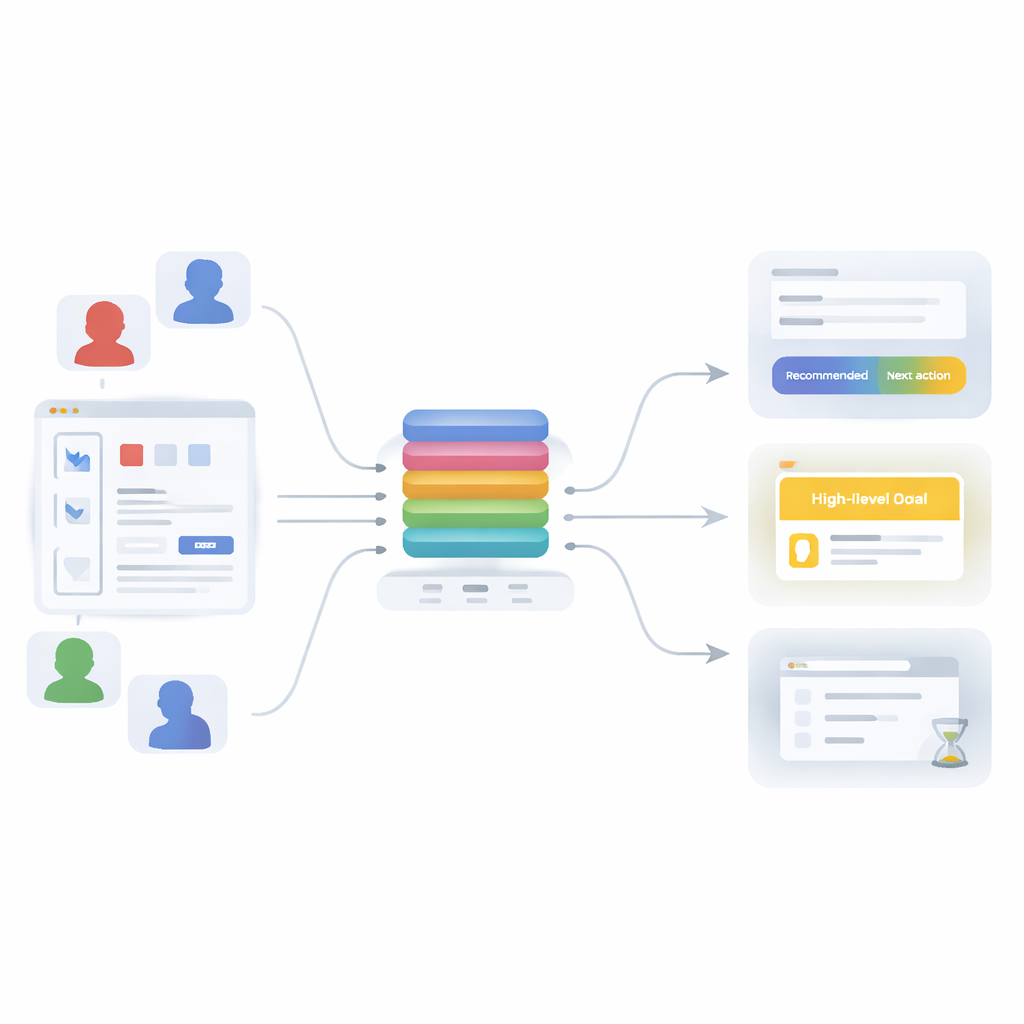
De cadeias simples a padrões ricos
Muitos sistemas existentes que tentam adivinhar o próximo passo de um usuário dependem de cadeias de Markov, uma ferramenta matemática clássica que considera apenas a ação mais recente para prever a seguinte. Embora rápidas e convenientes, essas abordagens de “memória de um passo” falham em ambientes reais de trabalho, onde tarefas como montar um pipeline de aprendizado de máquina ou preparar um painel se desenrolam em muitos passos e envolvem diferentes ferramentas. Os autores argumentam que modelos tão simples perdem estruturas de longo alcance, lidam apenas com um objetivo de previsão por vez e são difíceis de comparar entre estudos porque normalmente dependem de logs privados e escolhas opacas de limpeza de dados.
Um novo projeto de aprendizado multitarefa
Para superar essas limitações, o artigo introduz um modelo transformer baseado em atenção — a mesma família de técnicas por trás das ferramentas de linguagem modernas — reimaginado para o comportamento do usuário. Em vez de aprender apenas uma coisa, o modelo é treinado para resolver três tarefas relacionadas ao mesmo tempo: prever a próxima ação (qual API o usuário chamará), inferir o objetivo geral da sessão (como executar um fluxo de trabalho de machine learning, fazer análise de dados, gerenciar usuários ou criar visualizações rápidas) e decidir se a etapa atual provavelmente é a última da sessão. As três tarefas compartilham uma “espinha” comum que transforma um histórico curto de ações recentes em uma representação rica e única do que está acontecendo, a qual é então encaminhada a três pequenos módulos de predição.
Construindo um ambiente de teste realista in silico
Como os logs reais de atividade empresarial costumam ser sensíveis e difíceis de compartilhar, os autores constroem um ambiente simulado sofisticado que imita como profissionais de dados usam uma grande plataforma interna. Eles definem 100 APIs distintas agrupadas em 10 áreas funcionais, incluindo autenticação, entrada de dados, processamento, treinamento de modelos, visualização, exportação e administração. Quatro perfis de usuário — cientistas de dados, analistas de negócios, desenvolvedores e usuários avançados — seguem fluxos de trabalho característicos, embora imperfeitos, com probabilidades que refletem tanto comportamento rotineiro quanto desvios ocasionais. O conjunto de dados resultante contém 2.000 sessões de usuário e 20.000 chamadas de API, com objetivos de sessão como “pipeline de machine learning” e “visualização rápida” que produzem caminhos reconhecíveis, como fazer login, carregar dados, processá-los, criar um gráfico e exportar o resultado.
Quão bem o modelo aprende a antecipar
Treinado nesse ambiente estruturado porém variado, o modelo transformer mostra que o aprendizado baseado em atenção pode capturar melhor as regularidades ocultas no comportamento do usuário do que métodos antigos. Para a tarefa principal — adivinhar a próxima chamada de API entre 100 opções — ele acerta exatamente quase 80% das vezes, e coloca a escolha correta entre suas cinco principais sugestões em mais de 99,9% das vezes, um salto de mais de quatro vezes em relação a uma cadeia de Markov básica. Ao mesmo tempo, identifica corretamente o objetivo geral da sessão em cerca de 82% dos casos e detecta quase perfeitamente quando uma sessão está prestes a terminar. Os autores também enfatizam que o modelo é relativamente compacto e eficiente, tornando seu uso em tempo real viável para assistentes ao vivo que precisam responder sem atraso perceptível.
Ferramentas para outros reutilizarem e ampliarem
Para tornar sua abordagem mais do que um experimento isolado, os autores divulgam um pacote de software open-source chamado context-engineer, junto com o conjunto de dados simulado completo. Com esses recursos, outros pesquisadores e profissionais podem reproduzir os resultados relatados, testar modelos alternativos em um benchmark compartilhado ou integrar seus próprios logs internos mapeando ações e rótulos de sessão para um formato numérico simples. Essa abertura aborda um grande obstáculo na área, onde muitos sistemas anteriores não podiam ser comparados de forma justa ou reaproveitados porque seus dados e código não estavam disponíveis.
O que isso significa para usuários comuns
Para um público não especializado, a principal conclusão é que o artigo oferece uma receita prática para fazer ferramentas digitais parecerem “um passo à frente”. Ao aprender conjuntamente o que as pessoas estão tentando fazer, o que provavelmente clicarão em seguida e quando estão finalizando, o sistema proposto baseado em transformer transforma históricos de usuário em uma forma de consciência de contexto. Em aplicações reais, isso pode significar chatbots que preparam o próximo relatório antes de você pedir, plataformas de análise que sugerem ações de acompanhamento sensatas e painéis corporativos que reduzem discretamente o tempo de espera. Embora o estudo atual seja baseado em dados simulados e precise ser testado em logs reais, ele estabelece uma base clara e reprodutível para construir ajudantes de software mais inteligentes e antecipatórios em vários tipos de plataformas digitais.
Citação: Yin, Y. Rethink context engineering using an attention-based architecture. Sci Rep 16, 8851 (2026). https://doi.org/10.1038/s41598-026-43111-9
Palavras-chave: previsão de comportamento do usuário, recomendação sequencial, transformer baseado em atenção, assistentes digitais proativos, engenharia de contexto