Clear Sky Science · pt
Abordando o problema de desequilíbrio de dados na modelagem por aprendizado de máquina de eventos de apagão raros e disruptivos
Por que previsões de tempestade melhores importam para você
Quando uma grande tempestade derruba a energia, sentimos isso de forma muito pessoal: sem luz, sem aquecimento, alimentos estragados e comunicação interrompida. As concessionárias tentam prever essas falhas com antecedência para posicionar equipes de reparo e manter as pessoas seguras. Mas as tempestades mais severas são raras, o que significa que há surpreendentemente poucos dados sobre elas. Este artigo mostra como um tipo novo de inteligência artificial pode “imaginar” tempestades raras realistas, preenchendo lacunas nos registros e tornando as previsões de apagões mais precisas quando isso mais importa.
O desafio de aprender com desastres raros
A maioria dos apagões é causada pelo tempo, especialmente furacões, nor’easters, tempestades de neve e gelo e tempestades severas. Esses eventos estão se tornando mais intensos à medida que o clima esquenta, exercendo pressão extra sobre redes elétricas envelhecidas. Ainda assim, as tempestades mais danosas são, por definição, incomuns. Ferramentas estatísticas tradicionais e modelos de aprendizado de máquina tendem a aprender melhor com as muitas tempestades leves e moderadas, e têm dificuldade com o punhado de casos verdadeiramente extremos. Esse desequilíbrio nos dados leva a subestimações de danos justamente quando as concessionárias mais precisam de orientação confiável.
Ensinando computadores a criar novas tempestades
Para superar esse desequilíbrio, os autores constroem um sistema que gera tempestades sintéticas — isto é, eventos criados por computador que se parecem e se comportam como tempestades reais, mas não são cópias de nenhum evento passado específico. Eles se concentram em Connecticut, representando cada tempestade como uma grade de 815 células com 19 tipos de informação por célula, incluindo vento, chuva, pressão, turbulência, vegetação e disposição das linhas de energia. Primeiro, eles agrupam 294 tempestades históricas em 12 clusters com base em quantos e onde ocorreram “pontos problemáticos” — locais de danos que as equipes precisam reparar. As tempestades raras e de alto impacto acabam em quatro pequenos clusters que precisam ser reforçados.
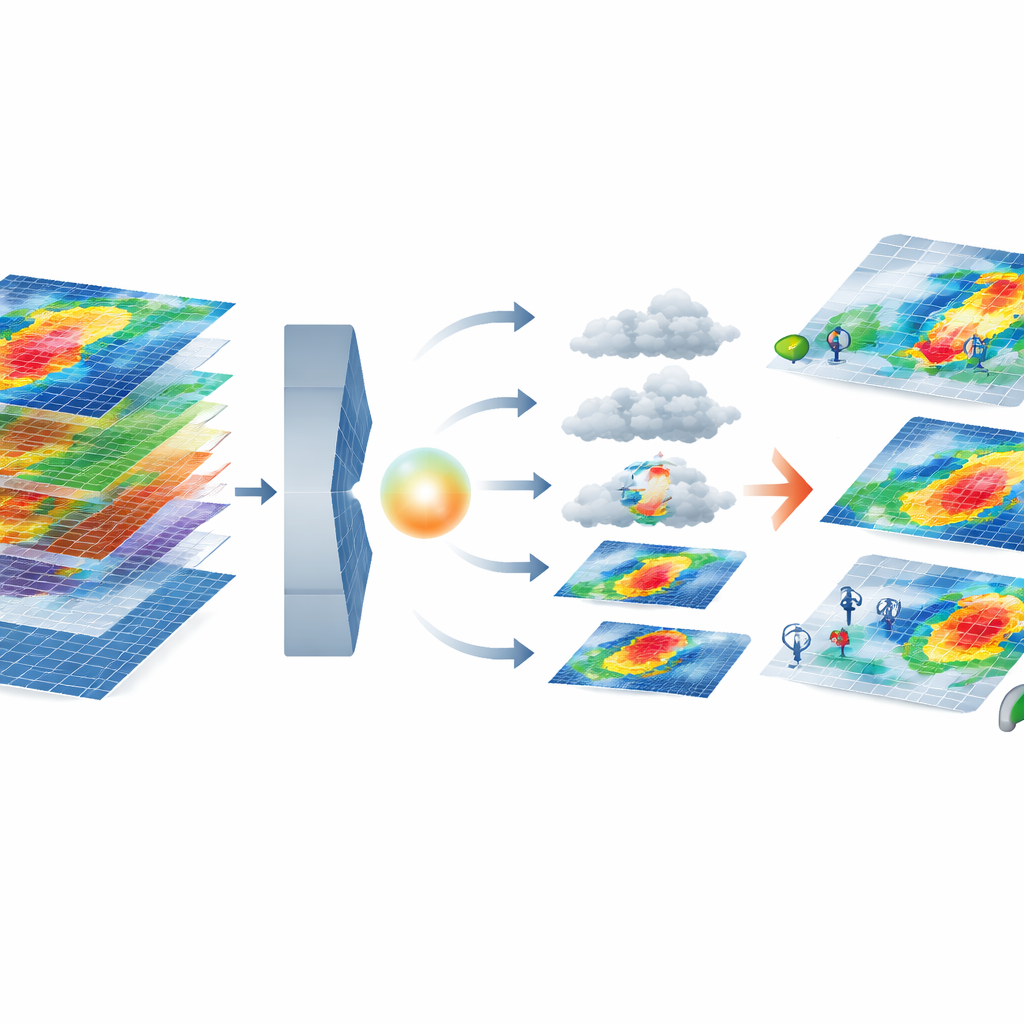
Como o novo modelo de IA constrói extremos realistas
O núcleo da estrutura combina duas ferramentas modernas de IA. Um autoencoder variacional comprime cada mapa de tempestade em múltiplas camadas para uma representação latente de menor dimensão que ainda preserva padrões importantes, como ventos mais fortes próximos à costa. Nesse espaço comprimido, um modelo de difusão aprende a partir do ruído aleatório e a refiná-lo gradualmente em uma tempestade realista, condicionado ao cluster de severidade de apagão solicitado. O sistema então seleciona as tempestades geradas usando um conjunto de métricas que comparam suas estatísticas com as de eventos reais — verificando não apenas características individuais como velocidade do vento, mas também como as características se movem em conjunto, capturadas por padrões de correlação. Somente tempestades sintéticas que correspondem de perto ao comportamento físico e estatístico de tempestades reais em um determinado cluster são mantidas.
Colocando tempestades sintéticas à prova
Os autores então fazem a pergunta crucial: essas tempestades sintéticas realmente ajudam a prever apagões? Eles treinam um modelo de previsão de apagões existente duas vezes — primeiro apenas com tempestades reais e depois com os mesmos dados enriquecidos com eventos sintéticos cuidadosamente selecionados para os clusters raros de alto impacto. Eles avaliam o desempenho usando um teste rigoroso de deixar-uma-tempestade-fora, que imita a previsão de eventos novos e não vistos. Com o enriquecimento sintético, o erro estrutural do modelo cai acentuadamente e o ajuste geral melhora. Para as tempestades raras e mais disruptivas, o erro quadrático médio central cai cerca de 45%, e medidas sumárias de habilidade, como a eficiência de Nash–Sutcliffe, passam de níveis piores que o baseline para um desempenho claramente útil. Uma comparação com uma augmentação “aleatória”, que adiciona tempestades sintéticas sem triagem de qualidade, mostra ganhos muito menores ou até negativos, ressaltando a importância da filtragem rigorosa.
O que isso significa para tempestades futuras
Em termos simples, este estudo mostra que permitir que a IA invente tempestades extremas fisicamente consistentes — e ser seletivo sobre em quais tempestades inventadas confiar — pode tornar as previsões de apagões mais confiáveis para os eventos que causam os maiores danos. Ao enriquecer dados escassos sobre eventos raros, mas devastadores, a abordagem ajuda as concessionárias a antecipar melhor quantos locais com danos enfrentarão e onde estarão. Embora demonstrada para um estado e um tipo de risco, a mesma estratégia poderia ser estendida a incêndios florestais, inundações e outras ameaças naturais, oferecendo uma nova forma de fortalecer o planejamento de infraestrutura em um mundo de extremos climáticos crescentes.
Citação: Azizi, M., Zhang, X., Yasenpoor, T. et al. Addressing the data imbalance issue in machine learning modeling of rare and disruptive outage events. Sci Rep 16, 8876 (2026). https://doi.org/10.1038/s41598-026-41838-z
Palavras-chave: dados sintéticos de tempestade, previsão de quedas de energia, modelos de difusão, clima extremo, desequilíbrio de dados