Clear Sky Science · pt
Predição, sintaxe e fundamentação semântica no cérebro e em grandes modelos de linguagem
Como seu cérebro antecipa a próxima palavra
Quando você escuta uma história, muitas vezes parece fácil acompanhá-la—mas sob a superfície, seu cérebro está constantemente adivinhando o que virá a seguir. Ao mesmo tempo, sistemas modernos de IA, como grandes modelos de linguagem (LLMs), também predizem palavras futuras para gerar texto fluente. Este estudo une esses dois mundos, investigando como o cérebro humano antecipa palavras em tempo real e como esses processos se comparam à forma como um modelo avançado de IA funciona.
Ouvindo uma história no laboratório
Para estudar a compreensão da linguagem natural, os pesquisadores foram além de listas artificiais de palavras ou sentenças curtas e isoladas. Em vez disso, 29 voluntários jovens ouviram cerca de 50 minutos de um audiolivro de ficção científica em alemão enquanto sua atividade cerebral era registrada. Duas técnicas complementares foram usadas simultaneamente: eletroencefalografia (EEG), que mede pequenas variações de voltagem no couro cabeludo, e magnetoencefalografia (MEG), que detecta os campos magnéticos gerados pela atividade cerebral. Juntas, essas metodologias conseguem rastrear as respostas do cérebro a cada palavra com precisão de milissegundos enquanto as pessoas acompanham uma narrativa contínua.
Acompanhando diferentes tipos de palavras
O audiolivro foi automaticamente dividido em palavras individuais e rotulado por classe gramatical: substantivos (como “planet”), verbos (como “run”), adjetivos (como “dark”) e nomes próprios. Para cada palavra da história, os cientistas recortaram uma janela curta do sinal de EEG e MEG antes e depois da pronúncia da palavra e então fizeram a média desses trechos dentro de cada classe de palavra. Isso revelou “assinaturas” elétricas e magnéticas confiáveis para os diferentes tipos de palavra, incluindo componentes bem conhecidos associados ao significado e à estrutura frasal. Importante: a equipe observou que a atividade relativa a substantivos começava a se acumular mesmo antes do início efetivo da palavra, sugerindo que o cérebro estava especialmente preparado para esse tipo de palavra no contexto.
Onde significado encontra movimento
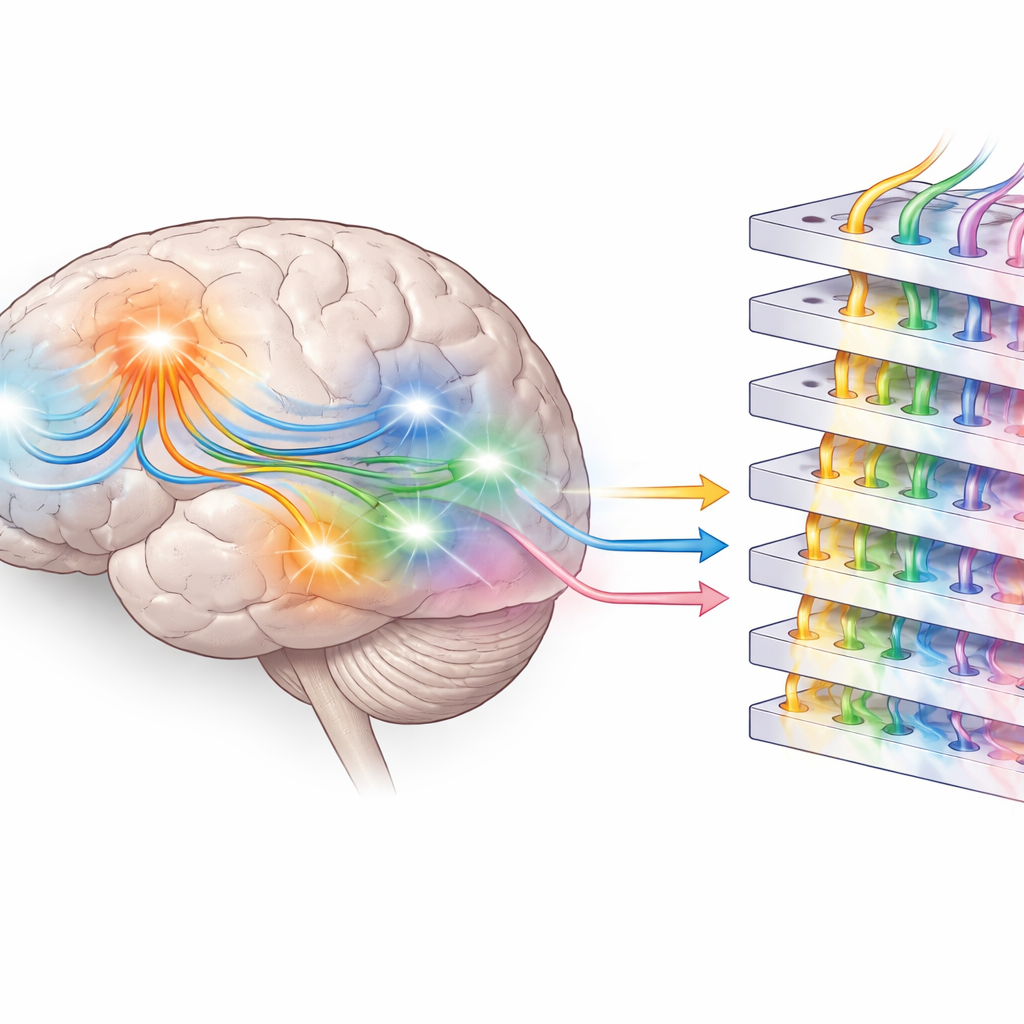
Para identificar onde no cérebro esses sinais surgiam, os pesquisadores usaram modelos computacionais para estimar as prováveis fontes dos padrões de MEG e EEG dentro da cabeça. Substantivos não ativaram apenas as regiões clássicas da linguagem nos lobos temporais; também engajaram áreas compatíveis com partes do sistema sensorimotor, próximas de regiões envolvidas em movimento e sensação corporal. Verbos, em contraste, mostraram um padrão diferente e mais restrito. Isso sustenta a ideia de linguagem “incorporada” (embodied), na qual compreender uma palavra—especialmente um substantivo concreto—reativa em parte redes ligadas à percepção e à ação, fundamentando o significado em experiências sensoriais passadas em vez de apenas em regras abstratas.
Comparando cérebros e grandes modelos de linguagem
A equipe então recorreu ao modelo de linguagem Llama 3.2, da Meta, para fornecer um ponto de referência computacional. Primeiro, testaram a “predição semântica” alimentando o modelo com o contexto precedente do audiolivro e perguntando quão provável ele julgava ser a palavra seguinte real. Substantivos mostraram-se os mais fáceis de predizer pelo modelo, refletindo seu papel central na construção da história. Em seguida, os pesquisadores exploraram a “predição sintática” examinando as ativações internas, ou embeddings, dentro do Llama. Mesmo sem treinamento adicional, camadas internas do modelo naturalmente agrupavam palavras de acordo com a classe gramatical da palavra seguinte, e uma rede de prova simples frequentemente conseguia prever qual classe de palavra viria a seguir. Ao longo das camadas, a estrutura interna para nomes próprios e substantivos tornava-se mais distinta, ecoando a separação crescente de papéis observada nos padrões de atividade cerebral.
Dois tipos de prontidão para palavras
Em conjunto, os resultados sugerem que o cérebro se prepara para a linguagem que está por vir em pelo menos dois níveis. Em regiões temporais, a atividade antes do início da palavra parece refletir uma espécie de prontidão gramatical ou “sintática”—conhecimento sobre onde certos tipos de palavra tendem a aparecer em uma frase. Em regiões mais frontais e sensorimotoras, os padrões de prontidão parecem conter expectativas “semânticas” mais ricas, ligadas a significado e experiência, especialmente para substantivos e nomes. Grandes modelos de linguagem, treinados apenas para predizer a próxima palavra, desenvolvem suas próprias estruturas internas em camadas que espelham parcialmente essas distinções, mas lhes falta fundamentação direta no mundo físico. Ao combinar registros cerebrais de alta velocidade com análises de IA de ponta, este trabalho ajuda a esclarecer como humanos antecipam palavras durante a escuta cotidiana e até que ponto as máquinas atuais se aproximam dessa característica central da compreensão linguística humana.
Citação: Kölbl, N., Rampp, S., Kaltenhäuser, M. et al. Prediction, syntax and semantic grounding in the brain and large language models. Sci Rep 16, 8728 (2026). https://doi.org/10.1038/s41598-026-41532-0
Palavras-chave: predição de linguagem, cérebro e IA, grandes modelos de linguagem, fundamentação semântica, EEG MEG linguagem