Clear Sky Science · pt
Detecção precoce de doença renal crônica com base em um modelo de aprendizado de máquina aprimorado por SURD
Por que detectar problemas renais cedo é importante
A doença renal crônica costuma progredir de forma silenciosa, apresentando poucos sinais de alerta até que os rins já estejam seriamente danificados. No entanto, exames simples de sangue e urina podem revelar problemas anos antes, quando o tratamento pode retardar ou até prevenir um declínio grave. Este estudo explora uma nova maneira de analisar esses resultados de exames de rotina usando modelos computacionais avançados, mas interpretáveis, para que pessoas em alto risco possam ser identificadas mais cedo e os médicos entendam por quê.
Transformando dados confusos de check-ups em sinais claros
Os pesquisadores partiram de um conjunto de dados público amplamente utilizado com 400 pessoas, a maioria já diagnosticada com doença renal crônica. Cada pessoa tinha 25 medidas, que iam da pressão arterial e hemograma a achados de urina e histórico médico, como diabetes e hipertensão. Muitas entradas estavam incompletas, então a equipe usou técnicas estatísticas cuidadosas para preencher valores ausentes em vez de simplesmente descartar pacientes. Também equilibraram os dados para que casos saudáveis e doentes ficassem mais representados de maneira uniforme, ajudando os modelos computacionais a aprender a reconhecer ambos os grupos de forma justa.
Indo além de correlações simples
A maioria das ferramentas de previsão médica trata cada resultado de exame separadamente: observa quão fortemente uma medida, como glicemia, está ligada à doença. Mas no organismo, os fatores de risco raramente agem sozinhos. Alguns exames fornecem quase a mesma informação, enquanto outros só se tornam informativos em combinação. Para capturar isso, os autores usaram uma estrutura chamada SURD que divide a contribuição de cada característica em três partes: informação compartilhada com outros exames, informação única e informação que só aparece quando as características atuam em conjunto. Isso permitiu agrupar valores laboratoriais e achados clínicos em conjuntos “únicos”, “redundantes” e “sinérgicos” antes de alimentá-los aos modelos de previsão.
Treinando vários modelos e escolhendo o mais confiável
Com esses grupos de características baseados em SURD em mãos, a equipe treinou dez modelos diferentes de aprendizado de máquina, desde árvores de decisão simples até abordagens mais complexas como florestas aleatórias e redes neurais. Eles compararam o desempenho quando os modelos usaram todas as características disponíveis versus apenas um conjunto combinado de únicas e sinérgicas. Em quase todos os tipos de modelo, esse conjunto enxuto guiado por SURD teve desempenho igual ou superior ao conjunto completo de 25 variáveis, muitas vezes melhorando o equilíbrio entre identificar corretamente pacientes doentes e evitar falsos alarmes. Em particular, modelos baseados em árvores, como florestas aleatórias e árvores com boosting, alcançaram pontuações quase perfeitas no conjunto de dados original.
Testando o método em dados hospitalares do mundo real
Desempenho excelente em um pequeno conjunto de referência pode ser enganoso se um modelo falhar quando exposto a pacientes mais variados. Para evitar isso, os autores validaram sua abordagem usando um banco de dados hospitalar muito maior, com mais de 27.000 pacientes de unidades de terapia intensiva. Nesse conjunto, o modelo de floresta aleatória construído com as características selecionadas pelo SURD ainda distinguiu pacientes com e sem doença renal com precisão extremamente alta. Seu desempenho superou claramente o de uma árvore de decisão mais simples, indicando que o método pode generalizar além de um conjunto de pesquisa cuidadosamente curado para registros do mundo real, mais bagunçados.
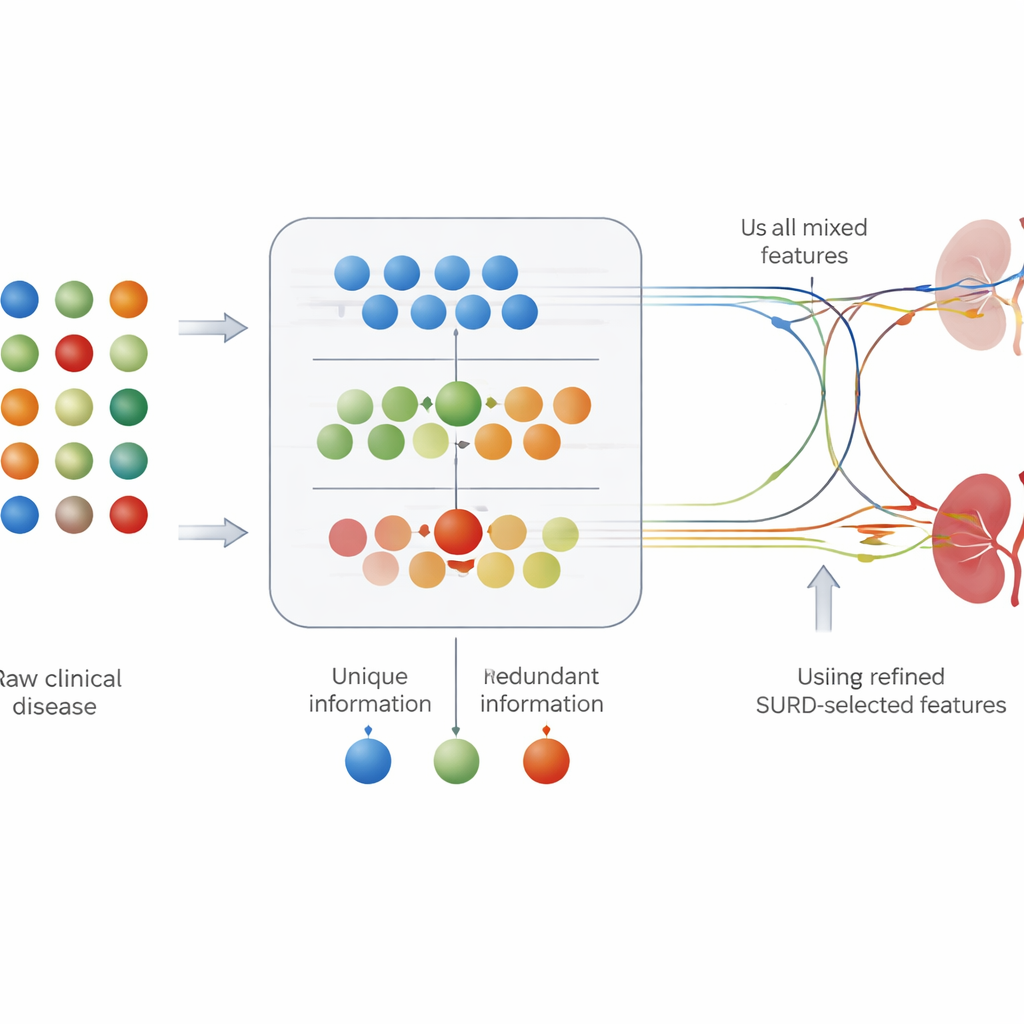
Vendo quais exames importam e por quê
A precisão por si só não basta para uso clínico; os médicos também precisam saber quais resultados de exames estão impulsionando uma previsão. O estudo combinou SURD com ferramentas modernas de explicação que atribuem a cada característica uma contribuição para a decisão do modelo em um determinado paciente. Essa análise destacou marcadores de risco familiares, como creatinina sérica (um indicador direto da função renal), níveis de hemoglobina, concentração urinária e a presença de diabetes ou hipertensão. Interessantemente, o SURD mostrou que alguns desses fatores atuam majoritariamente em conjunto com outros, enquanto a creatinina se destaca como um sinal fortemente informativo por si só. Juntas, essas técnicas oferecem tanto uma visão global de quais exames o modelo utiliza quanto detalhamentos ao nível do paciente sobre por que determinada pessoa é prevista como de alto risco.
O que isso significa para o cuidado diário
Em termos simples, o estudo mostra que é possível construir um calculador de risco de doença renal que seja ao mesmo tempo altamente preciso e razoavelmente transparente. Ao separar informações sobrepostas daquelas realmente únicas em dados rotineiros de laboratório e histórico, os modelos guiados por SURD fazem previsões mais nítidas sem se tornar uma caixa-preta misteriosa. Embora sejam necessários mais trabalhos em grupos de pacientes mais amplos e diversos, essa abordagem poderia, eventualmente, ajudar os clínicos a detectar problemas renais mais cedo, concentrar a atenção nos exames mais informativos e explicar aos pacientes, em termos diretos, quais aspectos da sua saúde estão colocando os rins em risco.
Citação: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
Palavras-chave: doença renal crônica, previsão de risco renal, aprendizado de máquina médico, IA explicável, prontuários eletrônicos