Clear Sky Science · pt
Abordagem dinâmica de aprendizado de máquina para previsão de carga de trabalho em ambientes de nuvem
Por que a previsão inteligente de tráfego importa
Cada vez que você transmite um vídeo, acompanha um grande evento esportivo online ou faz compras durante uma promoção-relâmpago, milhares de outras pessoas podem estar clicando ao mesmo tempo. Nos bastidores, os data centers em nuvem se esforçam para manter os sites rápidos sem desperdiçar dinheiro com máquinas ociosas. Este artigo aborda uma pergunta simples com enorme impacto prático: como os sistemas em nuvem podem antecipar ondas súbitas de tráfego web com precisão suficiente para ligar e desligar servidores no momento certo, em vez de chutar e pagar demais?
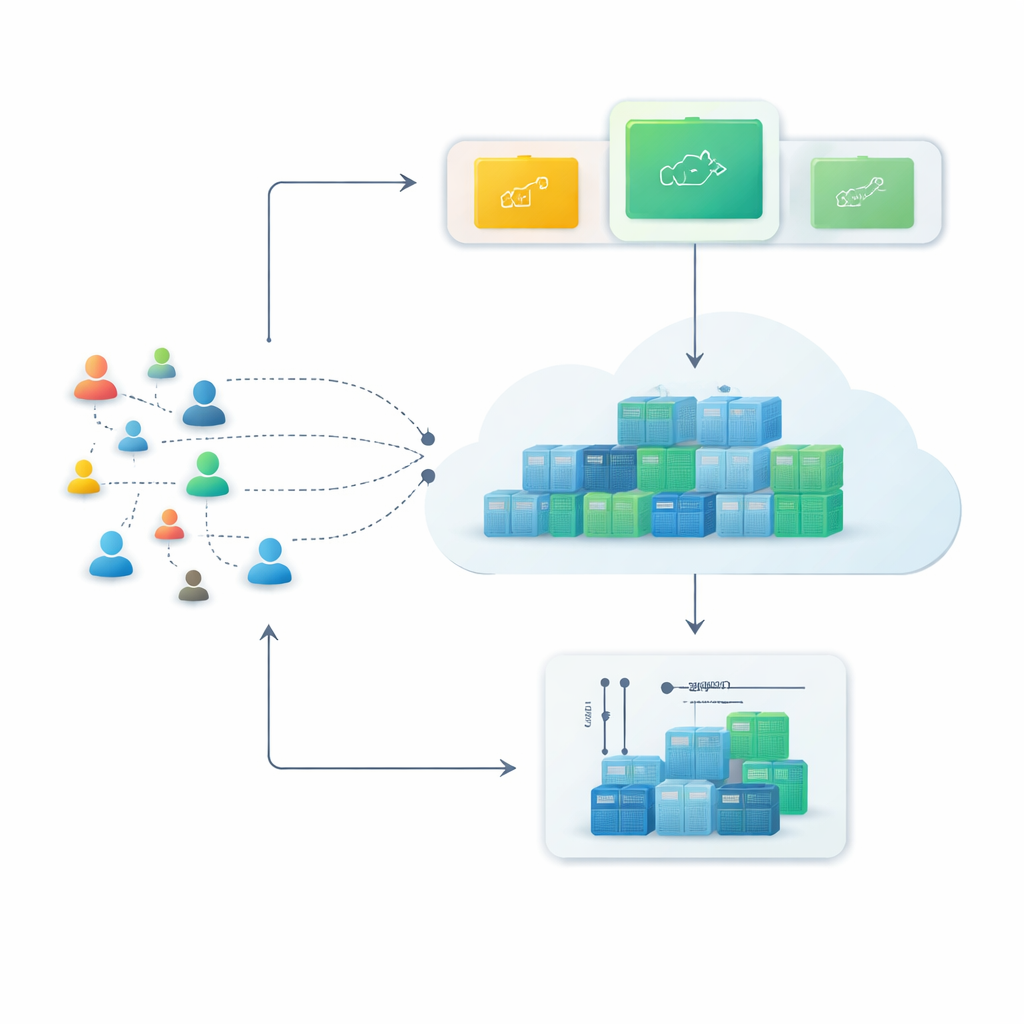
De servidores rígidos a containers flexíveis
Plataformas modernas em nuvem dependem cada vez mais de containers, pequenos pacotes de software que podem ser iniciados ou parados em segundos. Em comparação com máquinas virtuais tradicionais, os containers são mais leves e podem ser empacotados com maior densidade, tornando-os ideais para serviços que precisam crescer rapidamente durante períodos de maior demanda e encolher depois. Ainda assim, essa flexibilidade só compensa se o sistema conseguir prever problemas — se puder antecipar quantas requisições web chegarão nos próximos minutos e preparar o número certo de containers com antecedência.
Por que a previsão única não funciona sempre
Pesquisas anteriores testaram muitas formas de prever tráfego web, desde estatística clássica até redes neurais profundas. Alguns métodos funcionam bem quando a demanda varia suavemente ao longo do dia; outros se saem melhor quando o tráfego salta de forma imprevisível, como durante uma partida da Copa do Mundo. O problema é que nenhum método é o melhor o tempo todo. Se os operadores escolherem um modelo favorito e permanecerem fiéis a ele, a precisão pode cair abruptamente sempre que o comportamento dos usuários mudar, levando tanto a sites lentos quanto a filas de máquinas subutilizadas que consomem dinheiro e energia silenciosamente.
Um ciclo de aprendizado que nunca para de se adaptar
Para contornar isso, os autores propõem uma arquitetura em loop fechado que chamam de Monitorar–Treinar–Testar–Deploy. A ideia é tratar a previsão como um processo vivo. Primeiro, o sistema registra continuamente as requisições web em um histórico com carimbo de tempo. Em seguida, treina em paralelo vários métodos de previsão diferentes, cada um tentando aprender padrões naquele histórico recente. Depois, testa esses modelos candidatos nos dados mais recentes e os pontua conforme o quanto suas estimativas se desviam da realidade. Apenas o modelo com melhor desempenho é encarregado de fazer previsões em tempo real, que orientam quantos containers rodar. À medida que novo tráfego chega, o ciclo se repete: se os erros de previsão crescerem além de um nível tolerado por dois ciclos consecutivos, o sistema re-treina automaticamente e pode transferir o controle para um modelo diferente.
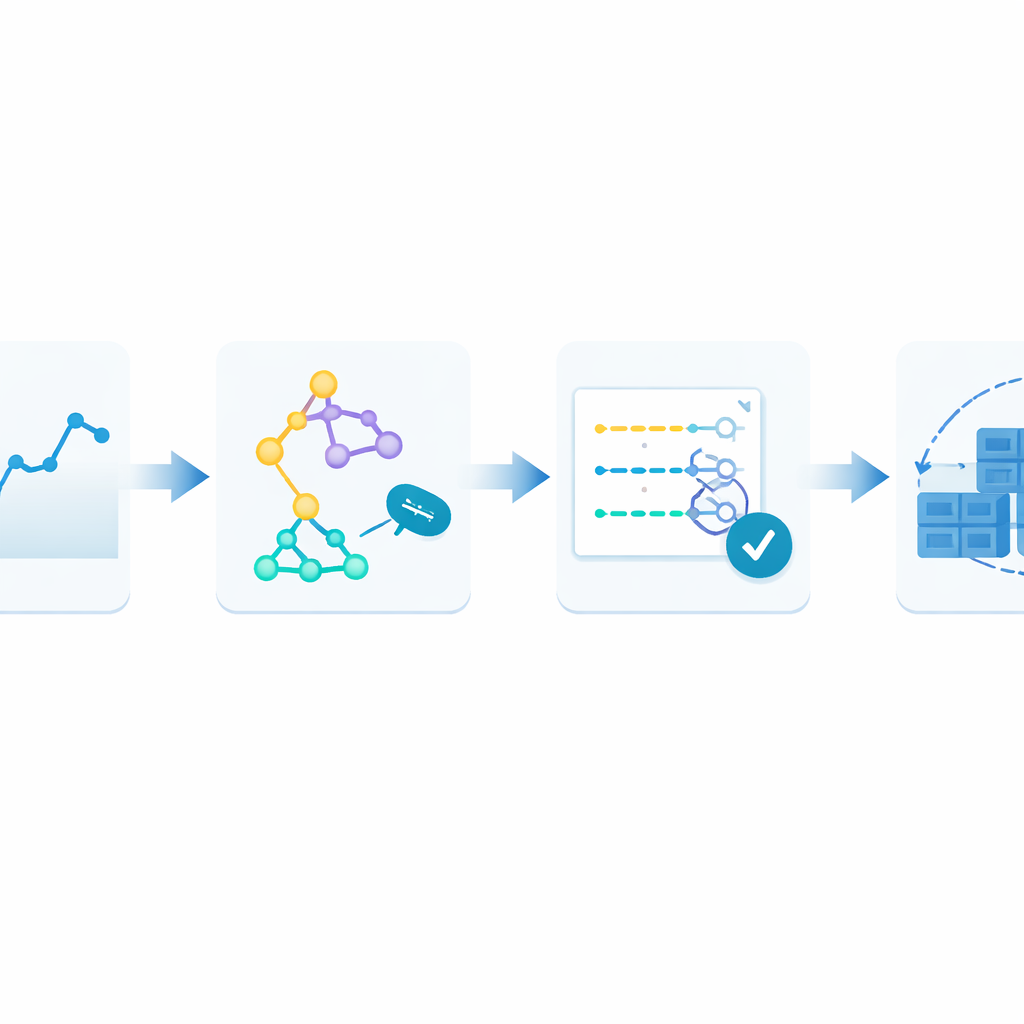
Colocando a arquitetura à prova
Os pesquisadores avaliaram essa abordagem usando tanto traços sintéticos quanto reais de atividade web. Geraram vários padrões idealizados — curvas suaves em formato de sino, cargas que aumentam de forma constante em velocidades diferentes e tráfego altamente errático — e também usaram registros dos sites oficiais da Copa do Mundo de 1998 e 2018, onde o interesse dispara abruptamente. Para cada caso, compararam três ou quatro ferramentas de previsão conhecidas, incluindo um método baseado em estatística, um modelo de vetor de suporte, um conjunto de árvores de decisão e, em experimentos posteriores, um tipo popular de rede neural recorrente. O resultado chave foi que o “vencedor” mudava conforme a situação: modelos estatísticos simples se destacavam quando a demanda era estável, enquanto métodos baseados em aprendizado eram claramente superiores quando o tráfego ficava selvagem e com picos.
Ganhos em precisão e eficiência
Ao alternar continuamente para o modelo que naquele momento melhor se adequava ao comportamento observado, a arquitetura reduziu os erros de previsão em até cerca de 15% em comparação com a manutenção de qualquer modelo fixo. Igualmente importante, isso foi feito sem executar todos os modelos o tempo todo. Apenas um preditor fica ativo durante a operação ao vivo; os demais são re-treinados e verificados periodicamente, mantendo a carga computacional moderada. Os autores também introduzem um limiar que se torna progressivamente mais rigoroso para quando re-treinar, de modo que o sistema fique menos tolerante a erros repetidos, reduzindo o risco de longos períodos de previsões ruins.
O que isso significa para usuários comuns da nuvem
Na prática, o estudo mostra que plataformas em nuvem podem ser geridas de forma mais inteligente ao permitir que modelos de previsão compitam e ao adaptar sua escolha ao longo do tempo. Para os usuários, isso pode se traduzir em experiências online mais suaves durante grandes eventos e em menos lentidões quando multidões aparecem inesperadamente. Para os provedores, promete uso mais enxuto dos recursos computacionais, menores custos operacionais e menos energia desperdiçada. Em vez de apostar em um único algoritmo engenhoso, este trabalho defende um ciclo de controle flexível que continua aprendendo, testando e revisando como antecipa a demanda em um mundo digital cada vez mais imprevisível.
Citação: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Palavras-chave: previsão de carga na nuvem, autoscaling, containers, aprendizado de máquina, séries temporais