Clear Sky Science · pt
Um sistema de recuperação multiusuário que preserva a privacidade para inteligência artificial multimodal
Por que manter buscas inteligentes privadas é importante
Muitos de nós hoje dependem de inteligência artificial baseada na nuvem para vasculhar nossas fotos, documentos e até exames médicos. Esses sistemas são poderosos porque entendem tanto imagens quanto palavras, mas também levantam uma questão difícil: como aproveitar essa conveniência sem entregar o significado dos nossos dados mais sensíveis a servidores distantes? Este artigo apresenta o PMIRS, um novo sistema que busca permitir que muitos usuários pesquisem coleções mistas de imagem e texto enquanto mantêm suas informações ocultas das máquinas em nuvem que realizam essas buscas.
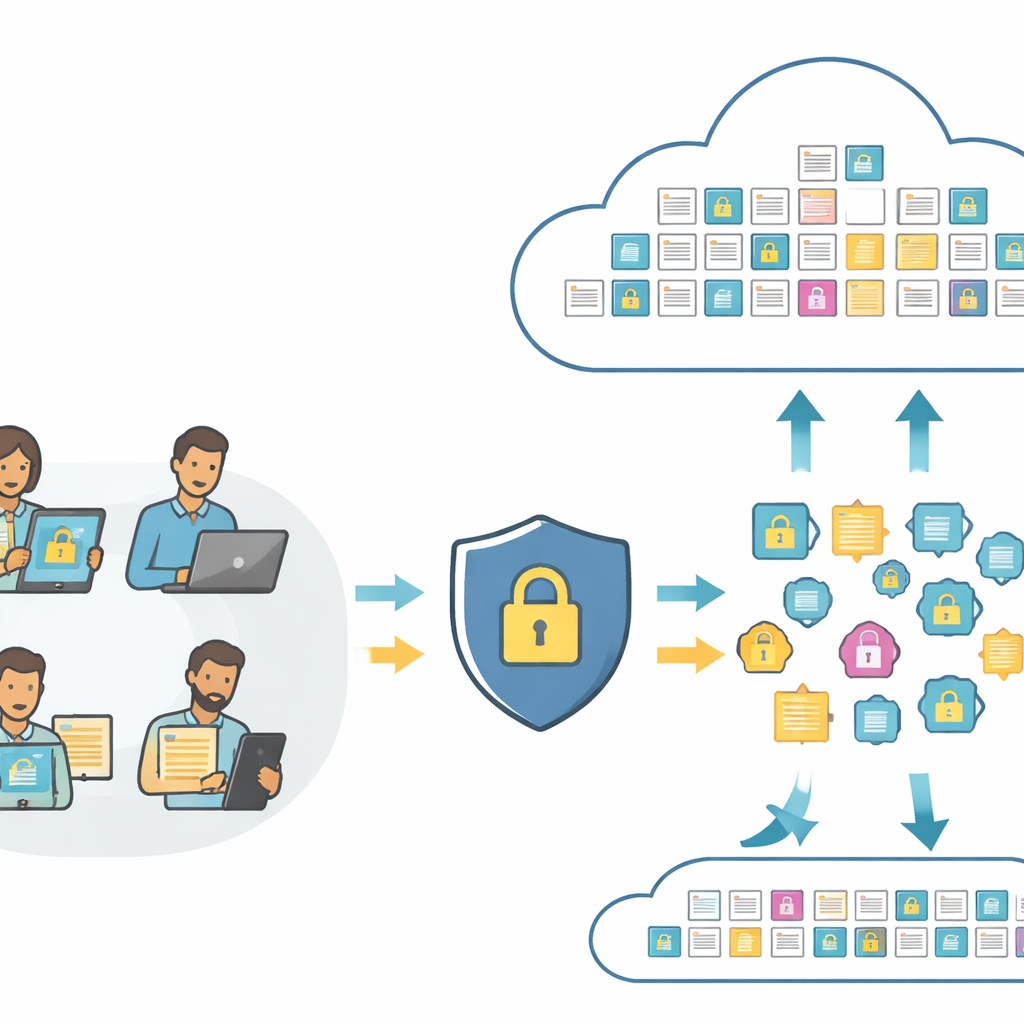
Pesquisar imagens e texto sem revelar seu significado
No coração das ferramentas modernas de busca estão os “embeddings” — impressões digitais numéricas que capturam o conteúdo de uma foto ou de uma frase para que um computador possa compará-los. Sistemas padrão enviam essas impressões diretamente para a nuvem, onde podem ser analisadas ou até mal utilizadas. O PMIRS reorganiza esse fluxo. Os usuários primeiro enviam suas imagens e textos brutos para uma camada local, que os transforma em impressões usando um modelo compacto de visão e linguagem. Antes de qualquer coisa sair do lado do usuário, as impressões são embaralhadas de forma controlada e então criptografadas. A nuvem vê apenas essas impressões protegidas e cópias totalmente criptografadas dos dados armazenados, mas ainda assim consegue realizar a correspondência e retornar os melhores resultados.
Aprender com muitos usuários sem centralizar seus dados
Treinar um bom modelo imagem–texto normalmente requer reunir enormes quantidades de exemplos rotulados em um só lugar — um claro risco à privacidade. O PMIRS, em vez disso, usa aprendizado federado. Nesse esquema, o modelo subjacente, adaptado da conhecida arquitetura CLIP, é enviado a muitos dispositivos. Cada um treina localmente em seus próprios pares imagem–texto privados e envia de volta apenas os pesos do modelo atualizados, que por sua vez são criptografados. Um servidor central faz a média dessas atualizações para melhorar um modelo compartilhado sem jamais ver as fotos ou descrições brutas de qualquer usuário. Os autores ainda reduzem e afinam o modelo por meio de um processo em etapas de “destilação” que poda partes desnecessárias preservando a precisão, tornando o sistema leve o suficiente para implantação prática.
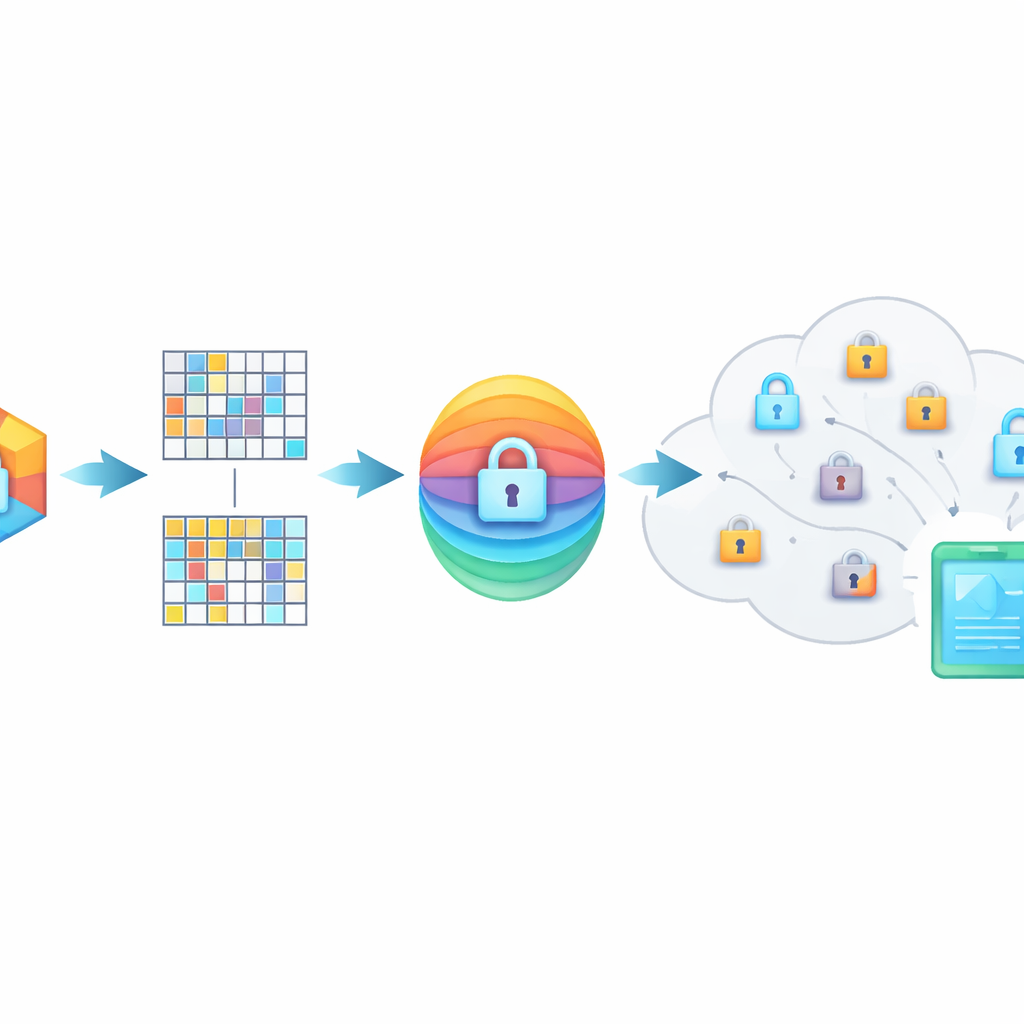
Ocultando o significado dentro de impressões embaralhadas
O PMIRS protege consultas com um escudo em duas camadas. Primeiro, cada impressão é cortada em blocos e cada bloco é transformado por uma matriz secreta, além de um padrão de ruído cuidadosamente projetado. Esse embaralhamento oculta a estrutura original dos dados, mas é preparado de forma que, quando dois itens relacionados são ambos transformados, sua similaridade permanece a mesma. Em segundo lugar, o resultado é criptografado usando o método AES amplamente adotado, com chaves que nunca são enviadas abertamente pela rede. Para situações em que uma pessoa precisa buscar nos dados de outra — como um médico consultando um especialista — o sistema usa um protocolo de troca de chaves Diffie–Hellman para que possam concordar em segredos compartilhados sem expô-los a ouvintes.
Como o sistema se sai na prática
Para testar se essas proteções impõem um custo excessivo, os pesquisadores construíram um benchmark que emparelha imagens do cotidiano com frases curtas em linguagem natural — mais próximo de como as pessoas realmente descrevem coisas do que rótulos de uma só palavra. Eles compararam o PMIRS com uma busca padrão baseada em CLIP em três temas: cenas naturais, objetos manufaturados e atividades ou paisagens. Em vários tamanhos de repositório, o PMIRS encontrou consistentemente um melhor equilíbrio entre capturar todos os resultados corretos (recall) e evitar correspondências falsas (precision), levando a uma pontuação F1 média — uma medida combinada de acurácia — cerca de 7,7% maior que a linha de base. Importante, os tempos de resposta ficaram abaixo de aproximadamente 180 milissegundos, rápidos o bastante para uso interativo, e muitas vezes ligeiramente mais rápidos que a linha de base não protegida apesar das etapas adicionais de proteção.
O que isso significa para usuários cotidianos
Em termos simples, o PMIRS mostra que é possível construir ferramentas de busca na nuvem que entendem bem imagens e texto, atendem muitos usuários ao mesmo tempo e ainda mantêm o significado dos dados de cada pessoa fora do alcance do provedor de nuvem. Ao combinar treinamento local, embaralhamento inteligente das impressões, criptografia forte e troca de chaves segura, o sistema oferece um fluxo de ponta a ponta que preserva a privacidade em vez de proteger apenas uma etapa. Embora ainda não cubra todos os ataques possíveis e necessite de refinamento e testes no mundo real, o trabalho aponta para serviços futuros — como busca de imagens médicas, bots de suporte ao cliente ou arquivos corporativos — em que as pessoas podem usufruir de buscas multimodais ricas com muito menos preocupação de que seu conteúdo pessoal será revelado ou mal utilizado.
Citação: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Palavras-chave: IA que preserva a privacidade, recuperação multimodal, aprendizado federado, busca criptografada, computação em nuvem segura