Clear Sky Science · pt
Alguns novos modelos quantitativos de resposta aleatória usando embaralhamento opcional e parcial para dados sensíveis
Por que fazer perguntas difíceis é tão complicado
Muitas das questões sociais mais importantes — sobre uso de drogas, renda oculta, sonegação fiscal ou comportamentos ilegais — são justamente aquelas que as pessoas menos querem responder honestamente. Se temem julgamento ou punição, podem mentir ou recusar-se a responder, e isso torna os resultados das pesquisas enganosos. Este artigo apresenta novas maneiras de desenhar pesquisas para que as pessoas possam ocultar com segurança suas respostas pessoais, ao mesmo tempo em que permitem aos pesquisadores medir, com alta precisão, quão comuns esses comportamentos sensíveis realmente são na população.
Como o acaso pode proteger sua privacidade
Desde a década de 1960, estatísticos usam um artifício inteligente conhecido como resposta aleatória. Em vez de responder diretamente a uma pergunta sensível, a pessoa usa um dispositivo aleatório — como o lançamento de uma moeda ou um girador — para decidir se dará a resposta verdadeira ou uma resposta disfarçada. Como apenas o entrevistado vê o resultado do dispositivo aleatório, nenhum observador externo pode saber se uma resposta particular é genuína. Ainda assim, sabendo as regras aleatórias, os pesquisadores conseguem reconstruir médias precisas para todo o grupo. Trabalhos posteriores estenderam essa ideia de perguntas de sim–não para perguntas numéricas, como quantas vezes alguém quebrou a lei ou quanto de renda não declarada possui.

Permitir que as pessoas escolham quanto querem ocultar
Métodos tradicionais de privacidade tratam todos da mesma forma: a resposta de cada entrevistado é embaralhada do mesmo modo, mesmo que algumas pessoas não estejam especialmente preocupadas com a pergunta. Essa abordagem “tamanho único” pode desperdiçar informação e ainda não fazer com que pessoas cautelosas se sintam seguras. Para corrigir isso, os pesquisadores desenvolveram modelos opcionais. Nesses, cada pessoa pode ou reportar seu número verdadeiro ou enviar uma versão embaralhada, dependendo do seu nível de conforto. O novo estudo se baseia nessa ideia para dados numéricos, criando quatro modelos que misturam respostas diretas com diferentes tipos de embaralhamento — às vezes adicionando ruído aleatório, às vezes multiplicando por um fator aleatório e às vezes usando várias etapas de randomização.
Quatro novas maneiras de equilibrar segurança e precisão
Os autores introduzem quatro modelos relacionados, rotulados M1 a M4. Todos têm como objetivo estimar o nível médio de um número sensível na população sem viés, o que significa que, em média, recuperam o valor verdadeiro. M1 estende um método existente adicionando uma segunda etapa de randomização, o que aumenta a incerteza sobre a resposta de cada pessoa enquanto mantém o cálculo geral simples. M2 combina uma primeira etapa em que algumas pessoas respondem diretamente com uma segunda etapa que embaralha as respostas seja por multiplicação, seja por adição de ruído aleatório. M3 e M4 generalizam ainda mais desenhos multiopção anteriores, oferecendo aos entrevistados várias formas possíveis de disfarçar seu valor verdadeiro. Essas camadas extras de escolha e aleatoriedade criam mais “cobertura” para os indivíduos ao mesmo tempo em que permitem aos estatísticos desenrolar o padrão geral.
Mensurando tanto privacidade quanto precisão
Como mais embaralhamento pode proteger as pessoas, mas também borrar os dados, a questão crucial é como avaliar a troca entre privacidade e precisão. Os autores comparam seus quatro modelos a sete métodos anteriores bem conhecidos usando vários critérios. Eles analisam eficiência estatística, que reflete quão variável é a estimativa final, e medidas de privacidade, que capturam o quão distantes os valores reportados tendem a estar do número verdadeiro de uma pessoa. Também usam uma pontuação combinada — chamada medida phi — que permite ao analista escolher quanto peso dar à privacidade versus à eficiência. Em uma ampla gama de cenários, os novos modelos, especialmente M1 e M4, mostram pontuações combinadas consistentemente melhores do que os métodos mais antigos.
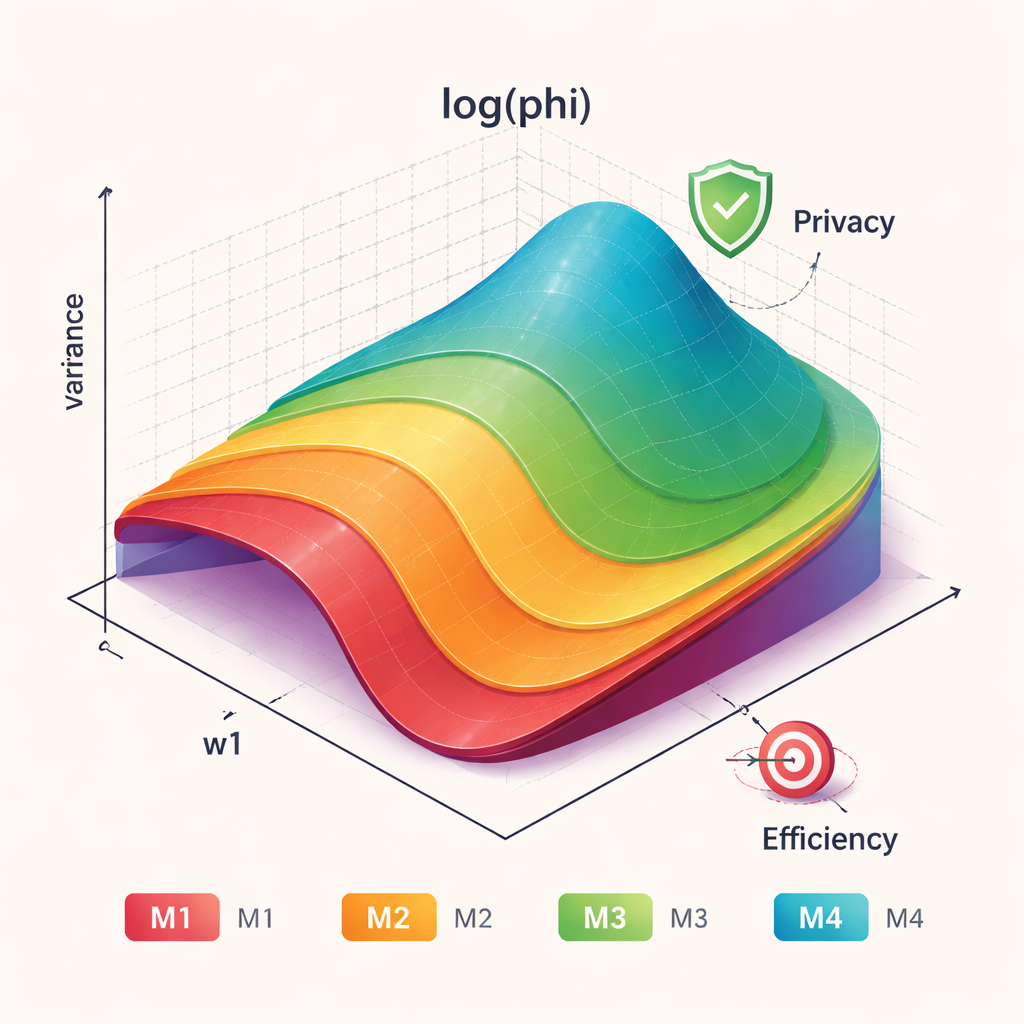
Escolhendo a ferramenta certa para um tema sensível
O estudo não afirma que um único modelo seja o melhor para todas as situações. Em vez disso, oferece orientações claras sobre quando usar cada abordagem. Quando proteger a privacidade individual é a prioridade máxima e os pesquisadores estão dispostos a aceitar um pouco mais de ruído estatístico, os modelos M1 a M3 são recomendados. Eles oferecem garantias fortes de que a resposta verdadeira de uma única pessoa não pode ser facilmente adivinhada. Quando os organizadores da pesquisa se preocupam mais em extrair o máximo de precisão possível a partir de dados limitados — por exemplo, em estudos pequenos ou caros — o modelo M4 tende a ter desempenho superior. No geral, a mensagem para não especialistas é tranquilizadora: ao desenhar cuidadosamente as regras aleatórias por trás de uma pesquisa, é possível fazer perguntas numéricas muito sensíveis de maneira eticamente mais segura para os participantes e cientificamente mais confiável.
Citação: Iqbal, S., Hussain, Z. & Omer, T. Some new quantitative randomized response models using optional and partial scrambling for sensitive data. Sci Rep 16, 7734 (2026). https://doi.org/10.1038/s41598-026-40714-0
Palavras-chave: pesquisas que preservam a privacidade, resposta aleatória, dados sensíveis, metodologia de pesquisas, confidencialidade estatística