Clear Sky Science · pt
Avaliação de modelos de linguagem de IA ao responder perguntas relacionadas à gravidez avaliadas por especialistas em obstetrícia
Por que isso importa para futuros pais
A gravidez é um período cheio de perguntas, e muitas pessoas hoje recorrem a ferramentas online e chatbots para obter respostas rápidas. Este estudo fez uma pergunta simples, porém importante: em relação a preocupações comuns na gravidez, quão bons são os chatbots de inteligência artificial (IA) mais populares em fornecer informações claras, precisas e tranquilizadoras que os médicos considerariam confiáveis?
Comparando três “motores de resposta” digitais
Pesquisadores na Turquia propuseram comparar três modelos de linguagem de IA bem conhecidos — uma versão anterior do ChatGPT (3.5), uma versão mais nova (4.0) e o Gemini do Google. Eles focaram em dez perguntas do cotidiano que gestantes frequentemente fazem, como quais alimentos evitar, se exercício e sexo são seguros, o que sangramento precoce pode significar, como interpretar os movimentos fetais e quais sinais de alerta exigem atendimento urgente. Cada pergunta foi inserida nos três sistemas usando as mesmas instruções simples, com configurações ajustadas para reduzir a aleatoriedade, de modo que as respostas fossem consistentes em vez de informais ou criativas.
Cada modelo produziu uma resposta por pergunta, em turco, sem prompts de acompanhamento ou edição. As respostas foram então removidas de quaisquer indícios que pudessem revelar qual sistema as escreveu e embaralhadas em ordem aleatória. Dessa forma, os revisores humanos — especialistas em obstetrícia e ginecologia — julgaram apenas o que estava na página, não a marca ou o estilo de escrita que pudessem reconhecer. 
Como os médicos avaliaram as respostas
Setenta e cinco especialistas em obstetrícia, desde médicos em início de carreira até clínicos muito experientes, avaliaram todas as 30 respostas anonimizadas. Para cada resposta, eles usaram uma escala de cinco pontos para avaliar quatro qualidades: precisão (corresponde ao conhecimento médico e diretrizes atuais?), confiabilidade (a mensagem é internamente consistente e livre de orientações inseguras?), adequação ao paciente (o tom é apropriado e tranquilizador para não especialistas?) e compreensibilidade (a linguagem é clara, bem estruturada e fácil de seguir?). No total, os especialistas forneceram 9.000 avaliações individuais — um grande conjunto de dados que permitiu aos pesquisadores detectar diferenças relevantes entre as três ferramentas de IA.
Em seguida, a equipe utilizou métodos estatísticos apropriados para escalas de avaliação para comparar os modelos. Também verificaram quão consistentemente diferentes médicos avaliavam as mesmas respostas e exploraram se clínicos mais experientes avaliavam de forma distinta em relação aos colegas mais jovens. O objetivo não foi construir um chatbot funcional, mas obter um retrato cuidadoso de como esses sistemas se comportam em condições controladas ao responder perguntas realistas sobre gravidez.
Qual chatbot foi o melhor?
No geral, o ChatGPT-4.0, mais recente, saiu na frente. Os médicos classificaram suas respostas como as mais precisas e as mais adequadas ao paciente, e ele também teve o melhor desempenho em confiabilidade. O Gemini geralmente ficou no meio: suas respostas eram frequentemente claras e fáceis de ler, e em termos de compreensibilidade ele foi similar ao ChatGPT-4.0, mas tendia a ser um pouco menos detalhado e preciso. O ChatGPT-3.5, modelo mais antigo, recebeu consistentemente as notas mais baixas, frequentemente oferecendo explicações mais curtas ou menos completas. Curiosamente, quando se tratou de clareza básica e estrutura, os três modelos pareceram mais semelhantes, o que sugere que tornar o texto legível pode ser mais fácil do que garantir que cada detalhe médico seja correto e bem ponderado. 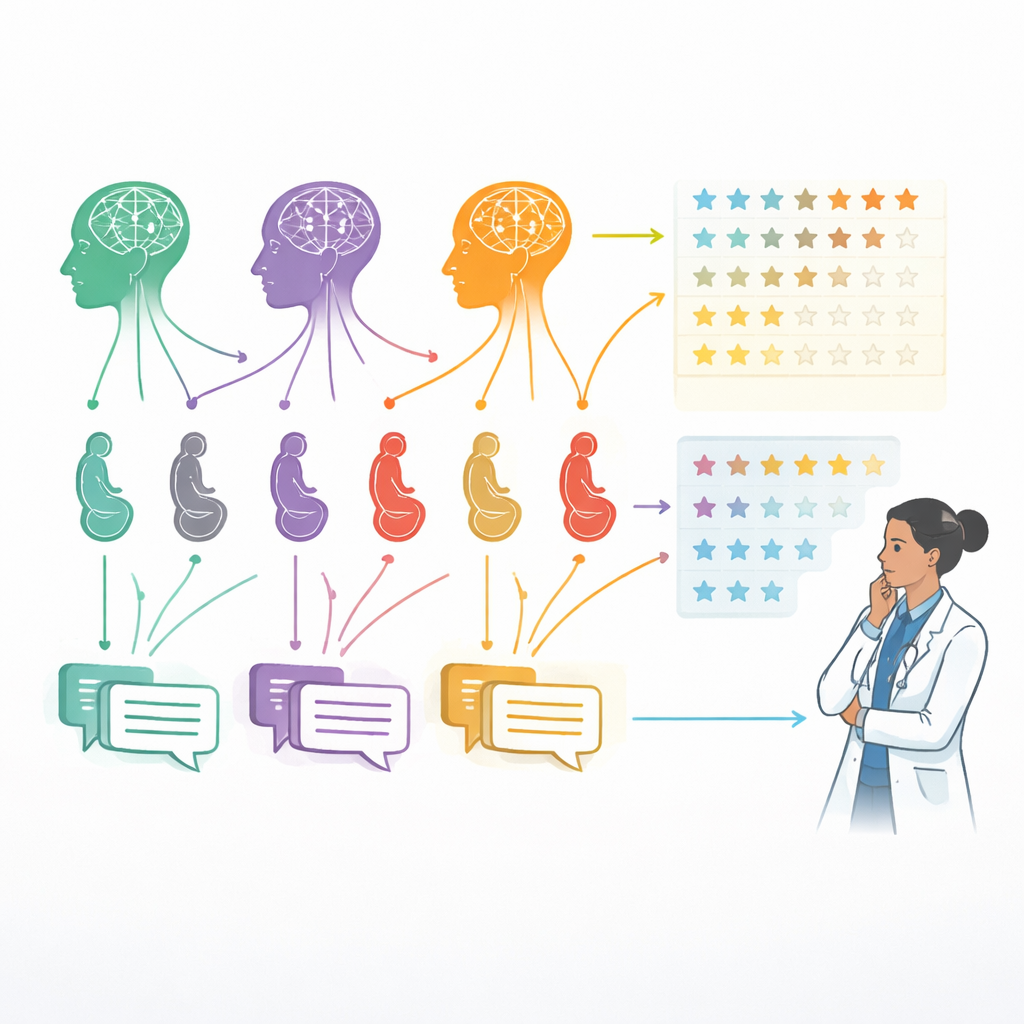
As avaliações dos médicos foram altamente consistentes entre si, indicando que os resultados não foram determinados por algumas opiniões extremas. Houve uma tendência modesta para que clínicos mais experientes dessem pontuações um pouco mais altas em confiabilidade no geral, mas suas opiniões não diferiram muito quanto à simpatia ou facilidade de compreensão das respostas.
O que isso significa para o uso no mundo real
Para um leigo, a conclusão é que ferramentas modernas de IA — especialmente o ChatGPT-4.0 — já podem fornecer informações sobre gravidez que muitos especialistas em obstetrícia consideram razoavelmente precisas, seguras e fáceis de ler. Dito isso, o estudo também ressalta um limite importante: mesmo o sistema de melhor desempenho não é um médico. Os pesquisadores não compararam as respostas dos chatbots a “padrões-ouro” de diretrizes oficiais, nem testaram como pacientes realmente interpretam ou agem com base no conselho. Como o trabalho foi realizado inteiramente em turco, o desempenho em outras línguas e culturas pode ser diferente.
Em termos práticos, esses chatbots de IA podem ser companheiros úteis para aprender sobre gravidez, especialmente quando uma consulta está distante ou o tempo com um profissional é curto. Eles podem apoiar, mas não devem substituir, conversas com profissionais de saúde. Os autores enfatizam que a supervisão de especialistas continua essencial para detectar erros, evitar falsos tranquilizadores e garantir que situações mais complexas ou de alto risco recebam o atendimento pessoal e presencial necessário.
Citação: Keyif, B., Yurtçu, E., Başbuğ, A. et al. Evaluation of AI language models in answering pregnancy-related questions assessed by obstetrics specialists. Sci Rep 16, 9322 (2026). https://doi.org/10.1038/s41598-026-40609-0
Palavras-chave: educação na gravidez, chatbots de IA, aconselhamento de saúde online, obstetrícia, qualidade da informação ao paciente