Clear Sky Science · pt
Colisões exatas de características em redes neurais
Quando Imagens Diferentes Enganam uma Máquina Inteligente
Os sistemas modernos de inteligência artificial conseguem reconhecer rostos, ler exames médicos e guiar carros autônomos. Já sabemos que eles podem ser enganados por mudanças mínimas e cuidadosamente projetadas em uma imagem. Este trabalho mostra algo ainda mais surpreendente: as próprias redes podem ser cegas a alterações enormes e óbvias, tratando imagens muito diferentes como se fossem a mesma. Entender como e por que isso acontece é crucial se quisermos sistemas de IA em que possamos realmente confiar.
De Pequenos Ajustes a Grandes Pontos Cegos
Redes neurais profundas impulsionam os avanços atuais em visão, linguagem e muitos outros campos. Pesquisas anteriores sobre exemplos adversariais revelaram que uma alteração quase imperceptível em uma imagem pode levar uma rede a classificá‑la incorretamente com alta confiança. Trabalhos mais recentes descobriram o problema oposto: algumas redes mal reagem a mudanças grandes e óbvias, e ainda assim produzem previsões quase idênticas. Nesses casos, as características internas extraídas de duas imagens muito diferentes “colidem”, isto é, a rede as representa de maneira quase igual. Este estudo leva a ideia muito mais adiante, provando que redes comuns não têm apenas colisões aproximadas, mas podem apresentar colisões de característica exatas, em que duas entradas distintas são mapeadas para exatamente os mesmos sinais internos.
Como as Colisões Surgem Dentro da Rede
Para explicar essas colisões, os autores examinam o interior das redes neurais e se concentram em suas matrizes de pesos, os números treinados que conectam uma camada à outra. Uma colisão de características ocorre quando duas entradas diferentes produzem a mesma saída em alguma camada; uma vez que isso acontece, todas as camadas subsequentes também veem a mesma coisa e, portanto, não conseguem distinguir as entradas. Matematicamente, isso ocorre quando a diferença entre duas entradas pertence ao “espaço nulo” dos pesos de uma camada: direções no espaço de entrada que a camada ignora completamente. Os autores mostram que sempre que uma matriz de pesos tem um autovalor zero ou mapeia de um espaço de dimensão mais alta para um de dimensão mais baixa, tais direções ignoradas devem existir. Como a maioria das arquiteturas do mundo real, incluindo modelos populares para classificação, segmentação e detecção de objetos, usa muitas dessas camadas, as colisões não são casos raros, mas uma propriedade quase inevitável dessas redes.
Uma Nova Maneira de Construir Entradas Colidentes
Com base nessa percepção, o artigo apresenta uma receita prática chamada busca no espaço nulo. Em vez de depender de tentativa e erro ou truques baseados em gradiente, esse método usa diretamente o espaço nulo da primeira matriz de pesos. Partindo de qualquer imagem, os autores computam um vetor que a primeira camada ignora e então adicionam uma versão escalada desse vetor à imagem. Como essa direção é invisível para a camada, as características internas da rede — e a predição final — permanecem exatamente as mesmas, mesmo que a própria imagem pareça fortemente distorcida para um observador humano. A mesma ideia se estende a camadas convolucionais e, em princípio, a camadas posteriores também. Os autores inspecionam muitos modelos padrão e constatam que a maioria possui numerosas direções ignoradas, o que significa que inúmeras imagens colidentes podem ser geradas dessa maneira para uma ampla gama de tarefas.
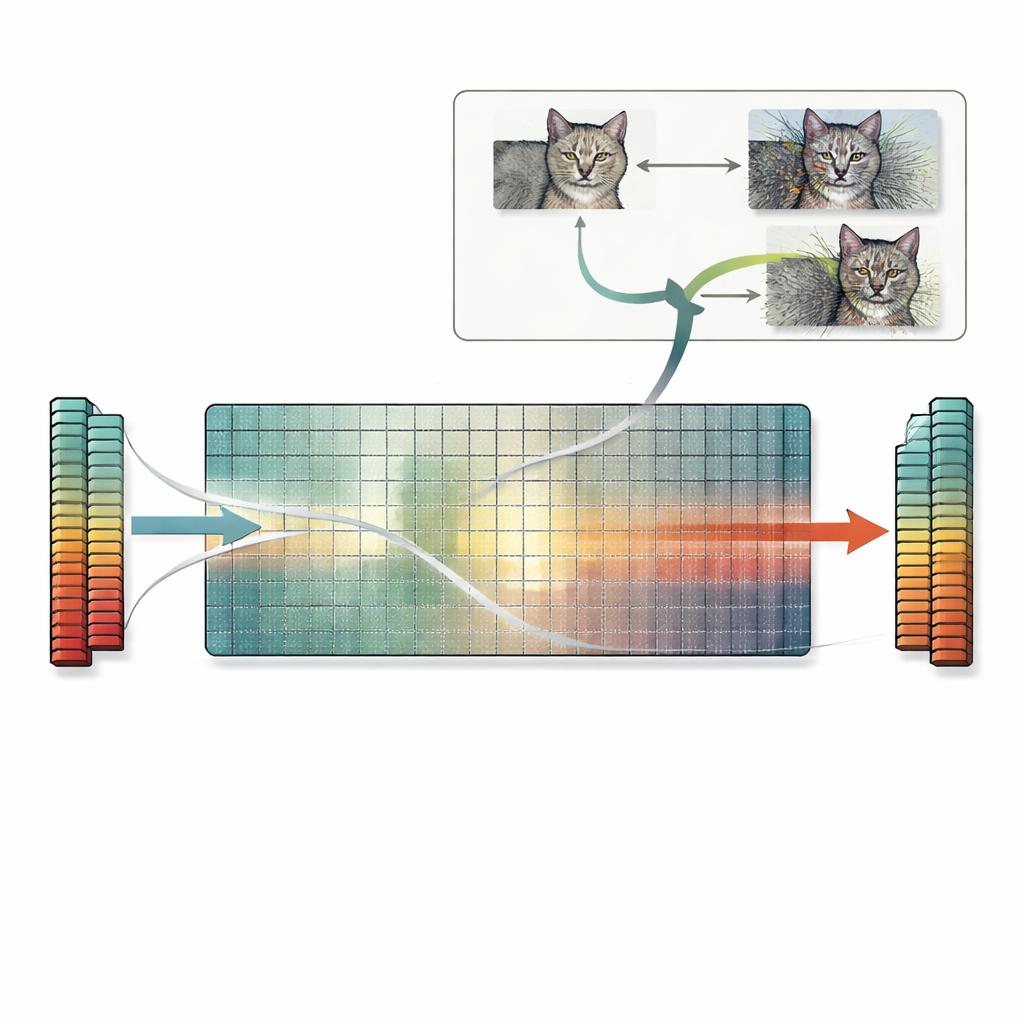
Riscos Ocultos para Similaridade, Explicações e Segurança
Essas colisões exatas de características têm consequências de amplo alcance. Duas imagens com características colidentes não apenas compartilharão a mesma predição; frequentemente também compartilharão os mesmos mapas de explicação produzidos por ferramentas populares de interpretabilidade. Isso pode fazer com que uma imagem irreconhecível e altamente perturbada pareça tão bem suportada quanto uma imagem limpa, minando a confiança em métodos de explicação. O problema também afeta medidas de similaridade baseadas em características que dependem de redes neurais: tais métricas podem julgar uma imagem fortemente corrompida como “idêntica” à original porque as características coincidem exatamente, mesmo que pontuações simples baseadas em pixels sinalizem corretamente grandes diferenças. Por fim, a busca no espaço nulo pode ser combinada com ataques adversariais padrão, produzindo muitas imagens adversariais diferentes que todas resultam na mesma predição errada e permanecem dentro dos limites usuais de perturbação, aprofundando preocupações de segurança existentes.
O Que Isso Significa para Construir IA Mais Segura
Em termos simples, este trabalho mostra que as redes neurais atuais frequentemente descartam informação de maneiras previsíveis, deixando direções inteiras no espaço de entrada que não afetam suas decisões. Atacantes podem explorar esses pontos cegos para criar imagens bizarras ou adversariais que uma rede trata como idênticas às normais. Os autores sugerem usar contagens simples dessas direções ignoradas como forma de avaliar quão vulnerável um modelo pode ser, e argumentam que redes mais enxutas e melhor regularizadas, com espaços nulos menores, poderiam ser mais robustas. Embora muito ainda precise ser testado na prática, a mensagem central é clara: se quisermos IA confiável, devemos prestar atenção não apenas ao que as redes respondem, mas também ao que elas ignoram.
Citação: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Palavras-chave: redes neurais, exemplos adversariais, colisões de características, robustez do modelo, busca no espaço nulo