Clear Sky Science · pt
CMT-Unet: aproveitando um framework híbrido por estágios para maior precisão e eficiência na segmentação de imagens médicas
Visões mais nítidas do interior do corpo
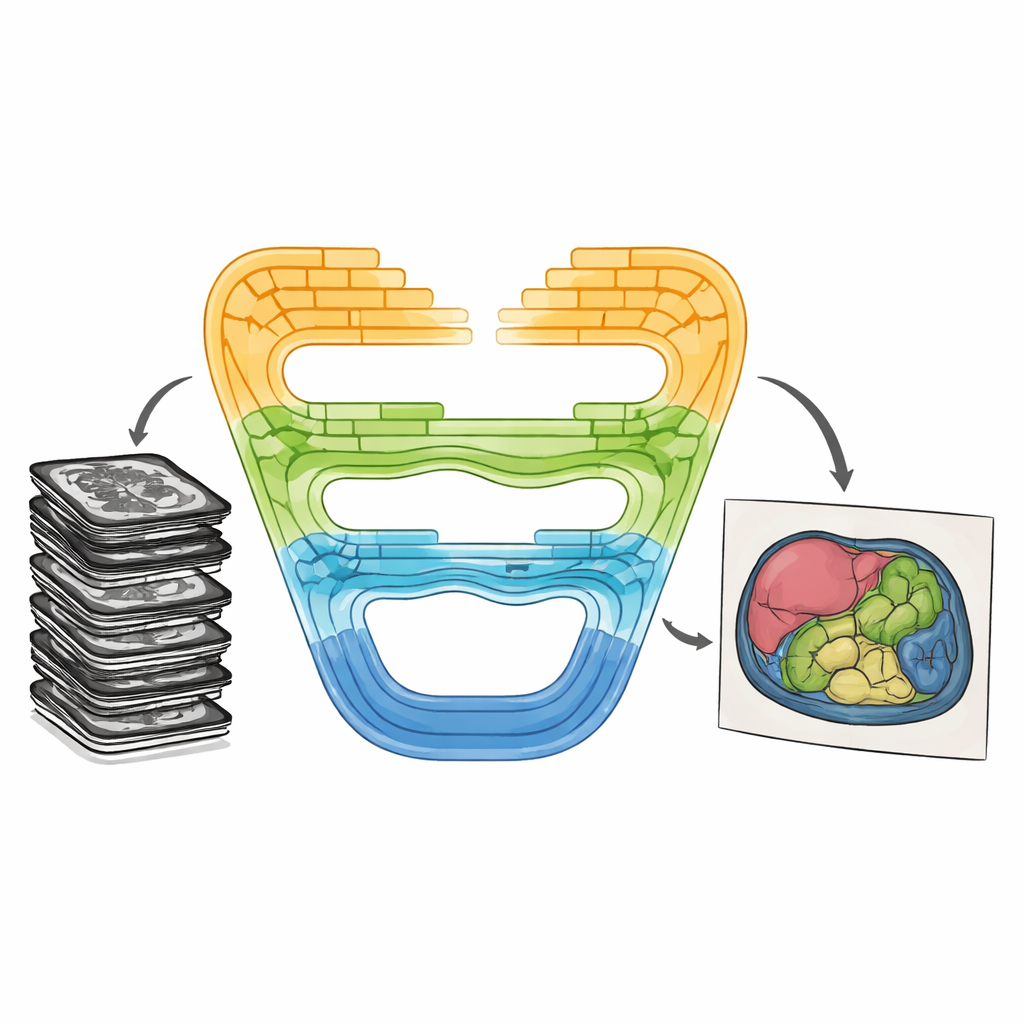
A medicina moderna depende fortemente de exames como tomografia computadorizada (TC) e ressonância magnética (RM) para observar o interior do corpo, mas transformar essas imagens em tons de cinza, muitas vezes borradas, em contornos nítidos de órgãos e tecidos ainda é um desafio. Médicos precisam de limites precisos para planejar cirurgias, acompanhar a função cardíaca ou medir como um tumor responde ao tratamento. Este artigo apresenta uma nova abordagem de visão computacional, chamada CMT-Unet, projetada para traçar esses contornos com mais precisão e eficiência, aproximando a análise automatizada de imagens do uso clínico cotidiano.
Por que os contornos das imagens importam
Antes de uma operação ou de um tratamento complexo, os clínicos muitas vezes precisam de um mapa em nível de pixel dos órgãos ou estruturas em um exame — um processo conhecido como segmentação. Tradicionalmente, especialistas delineavam essas regiões manualmente, tarefa demorada, cansativa e sujeita a variação entre observadores. Na última década, métodos de aprendizado profundo assumiram grande parte desse trabalho, especialmente modelos baseados em redes convolucionais e em mecanismos de atenção no estilo Transformer. Modelos convolucionais se destacam em captar detalhes locais finos, como bordas, enquanto Transformers são particularmente eficazes em capturar contexto amplo em toda a imagem. No entanto, cada abordagem tem suas compensações: convoluções podem perder relações de longo alcance, enquanto Transformers frequentemente exigem alto custo computacional e memória.
Combinando forças de uma nova maneira
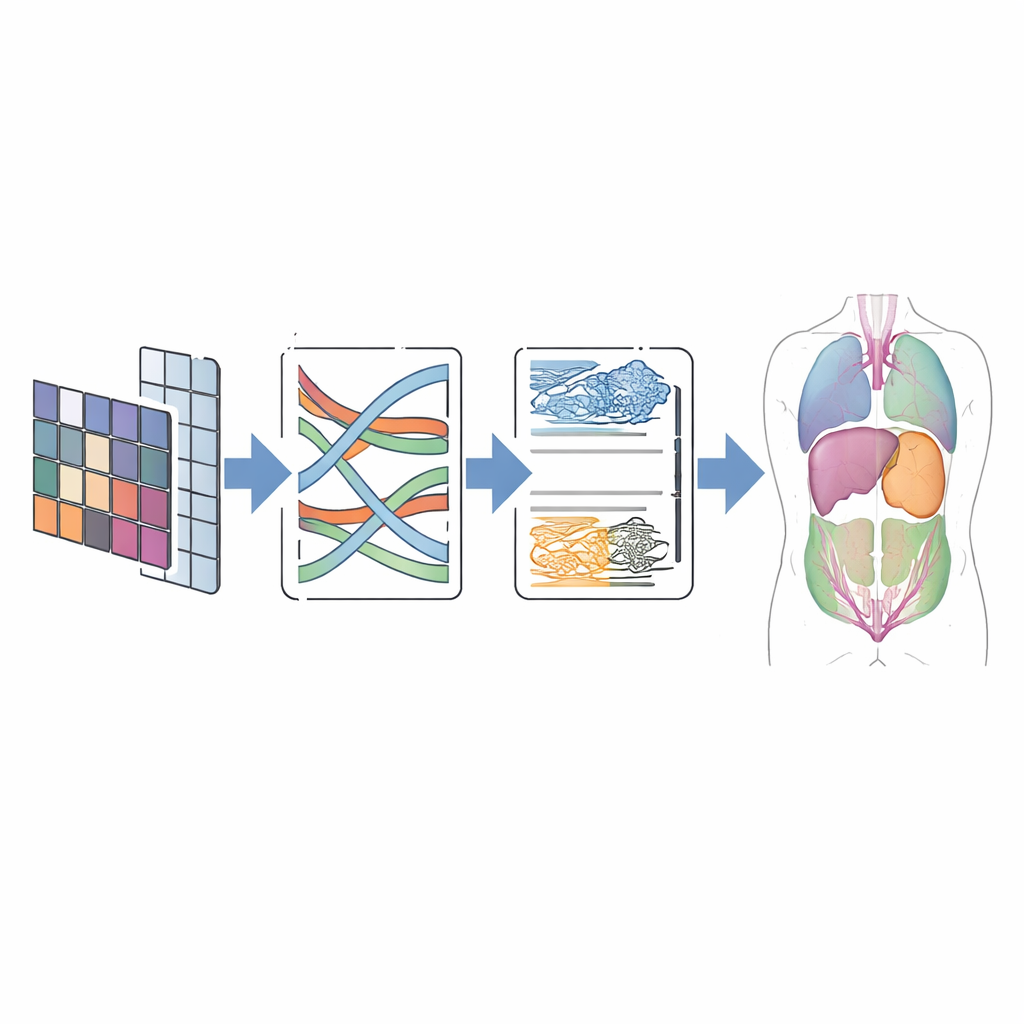
CMT-Unet enfrenta essas trocas cost-benefício ao entrelaçar três tipos de blocos de construção de forma por estágios, em vez de depender de um único tipo ao longo de toda a rede. Na frente do sistema, uma unidade convolucional com residual invertido aprende rapidamente padrões locais — bordas nítidas e texturas que ajudam a distinguir tecidos vizinhos. Nos estágios intermediários, um módulo baseado nos chamados modelos de espaço de estado, adaptado de uma arquitetura recente chamada Mamba, transmite informações ao longo de sequências de características de imagem de modo sensível ao contexto e computacionalmente enxuto. Em profundidade na rede, blocos Transformer aprimorados com atenção HiLo dividem a informação em componentes de alta e baixa frequência, permitindo ao modelo capturar tanto pequenos detalhes quanto formas amplas de órgãos antes de recombiná-los. Esse projeto em camadas espelha a progressão natural de pixels brutos a significado abstrato conforme as imagens são processadas.
Como o novo modelo funciona internamente
Na prática, CMT-Unet segue o layout em forma de U familiar e popular na imagem médica: um codificador que comprime informação em características mais ricas, um decodificador que reconstrói uma predição em tamanho real e conexões de salto que transferem detalhe espacial. A diferença chave está em quais módulos são usados em cada profundidade. A unidade convolucional inicial lida com a estrutura de grão fino que os componentes Mamba e Transformer poderiam borrar. O bloco MambaVision modificado melhora então o contexto de alcance médio ao misturar informação espacial por meio de operações bidimensionais especialmente desenhadas, evitando o custo elevado da atenção completa enquanto ainda vê além de patches locais. A atenção HiLo no estágio Transformer separa explicitamente bordas nítidas de padrões de fundo suaves, combinando-os de modo a preservar limites. Por fim, um módulo duplo de upsampling no decodificador ajuda a reconstruir contornos limpos e contínuos enquanto reduz artefatos comuns como padrões de tabuleiro de xadrez.
Testes em exames do mundo real
Para avaliar se esse desenho compensa, os autores testaram o CMT-Unet em dois conjuntos de dados públicos amplamente usados. O primeiro, chamado Synapse, contém TC abdominais com oito órgãos rotulados, incluindo fígado, rins e estômago. O segundo, ACDC, inclui imagens de RM cardíaca com rótulos para os ventrículos do coração e a parede muscular. Nesses benchmarks, o CMT-Unet alcançou pontuações de segmentação iguais ou superiores aos modelos líderes convulsionais, Transformer e híbridos, empregando um número moderado de parâmetros e uma quantidade de processamento manejável. Comparações visuais mostraram limites mais suaves e consistentes do ponto de vista anatômico, especialmente em regiões desafiadoras como as cavidades cardíacas, cruciais para medir função e planejar intervenções.
O que isso significa para pacientes e clínicas
Para leitores não especialistas, a conclusão principal é que o CMT-Unet oferece uma maneira mais inteligente de traçar estruturas em imagens médicas ao combinar cuidadosamente a ferramenta certa para cada estágio do processamento. Ao equilibrar detalhe local e contexto global, o modelo pode produzir contornos de órgãos precisos e limpos sem exigir recursos de supercomputador. Embora o trabalho atual se concentre em exames bidimensionais e em um conjunto limitado de bases públicas, a abordagem é promissora para extensões futuras a imagens tridimensionais e cenários clínicos mais amplos. Se validada adicionalmente, esse tipo de segmentação leve porém precisa poderia apoiar diagnósticos mais rápidos, planejamento de tratamento mais confiável e orientação em tempo real em ambientes hospitalares movimentados.
Citação: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Palavras-chave: segmentação de imagens médicas, aprendizado profundo, redes neurais híbridas, modelos de espaço de estado, imagem médica