Clear Sky Science · pt
Atribuição de câmera de origem usando uma rede neural convolucional explicável baseada em regras
Por que suas fotos podem revelar mais do que você imagina
Cada foto que você tira carrega pistas ocultas sobre a câmera que a capturou. Para investigadores digitais, essas pistas podem ajudar a confirmar se uma imagem é genuína, rastrear de qual dispositivo ela veio ou conectar fotos de diferentes cenas de crime. Hoje, ferramentas poderosas de inteligência artificial (IA) detectam esses padrões melhor do que humanos — mas frequentemente operam como caixas-pretas misteriosas. Este artigo apresenta uma maneira de abrir essa caixa: um método baseado em regras que explica como um modelo de aprendizado profundo decide qual câmera fez uma foto, em uma forma que um perito humano pode entender e confiar.
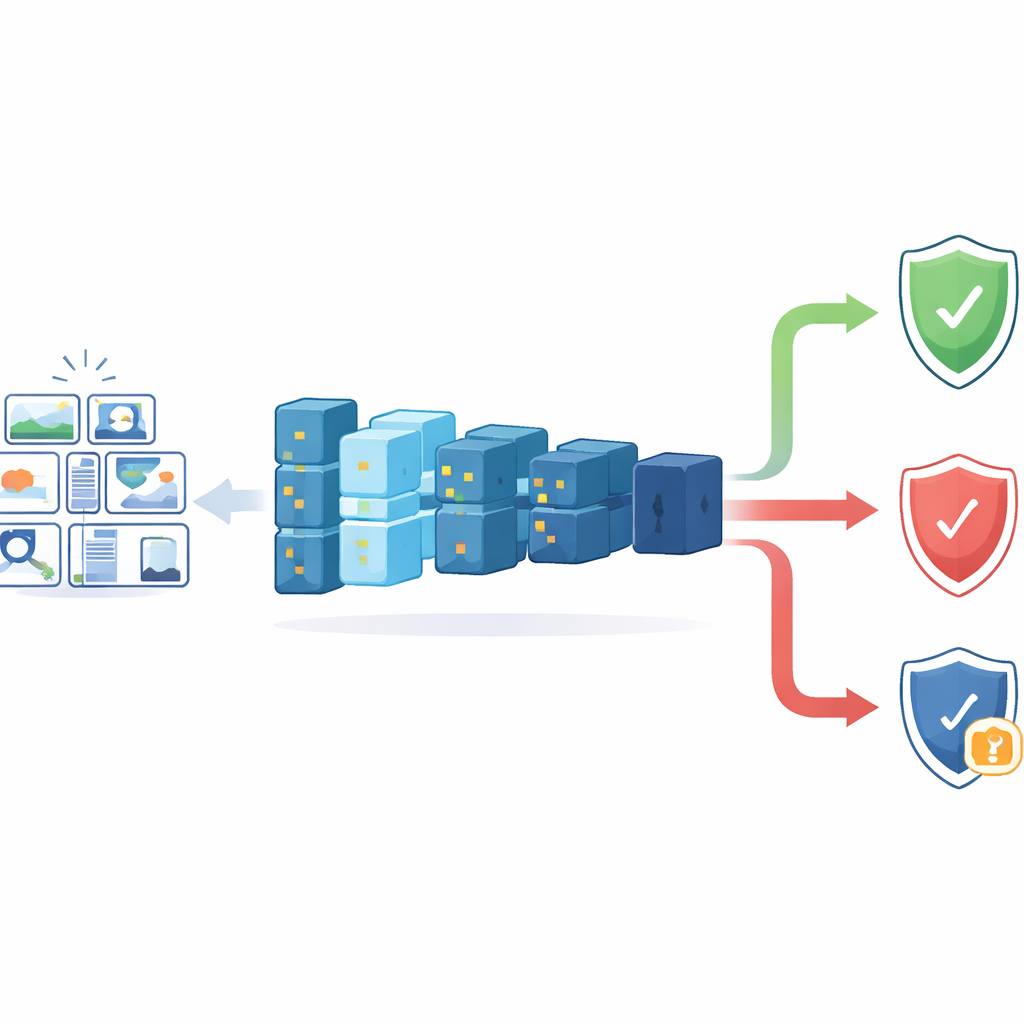
O desafio de confiar em ferramentas forenses inteligentes
A forense digital moderna precisa vasculhar enormes volumes de dados — de smartphones, backups em nuvem e redes sociais — muito além do que analistas humanos podem inspecionar manualmente. Sistemas de aprendizado profundo podem rapidamente sinalizar imagens ou sugerir quais são relevantes, mas seu funcionamento interno é notoriamente opaco. Em ambientes sensíveis, como tribunais, dizer simplesmente “a rede neural acha isso” não é suficiente. As ferramentas de explicação existentes geralmente destacam regiões da imagem que o modelo considerou importantes, o que é útil para tarefas como reconhecimento de rostos ou objetos. Contudo, para identificação da câmera de origem, o sinal crucial não é um recurso visível, e sim uma impressão digital do sensor — padrões de ruído sutis que as pessoas não enxergam. Como resultado, as ferramentas visuais de explicação atuais não mostram claramente por que um modelo acha que uma imagem veio de uma câmera específica, nem ajudam o perito a identificar quando o modelo está errado.
Uma nova maneira de observar o raciocínio da rede neural
Os autores introduzem o xDFAI, um framework projetado especificamente para forense digital que explica como uma rede neural convolucional (CNN) chega a suas decisões sem alterar o modelo original. Em vez de tratar a rede como uma caixa opaca única, o xDFAI examina seu interior camada por camada. Para cada camada e cada classe de câmera, identifica um conjunto de padrões internos recorrentes, chamados “traços”, que acendem consistentemente quando o modelo acredita que uma imagem pertence àquela câmera. Esses traços são extraídos de um modelo treinado usando métodos de atribuição existentes e então filtrados para manter apenas os padrões que aparecem de forma confiável em muitas imagens de treinamento. Juntos, esses traços formam um mapa estruturado de como as pistas sobre a identidade da câmera evoluem à medida que a imagem percorre a rede.
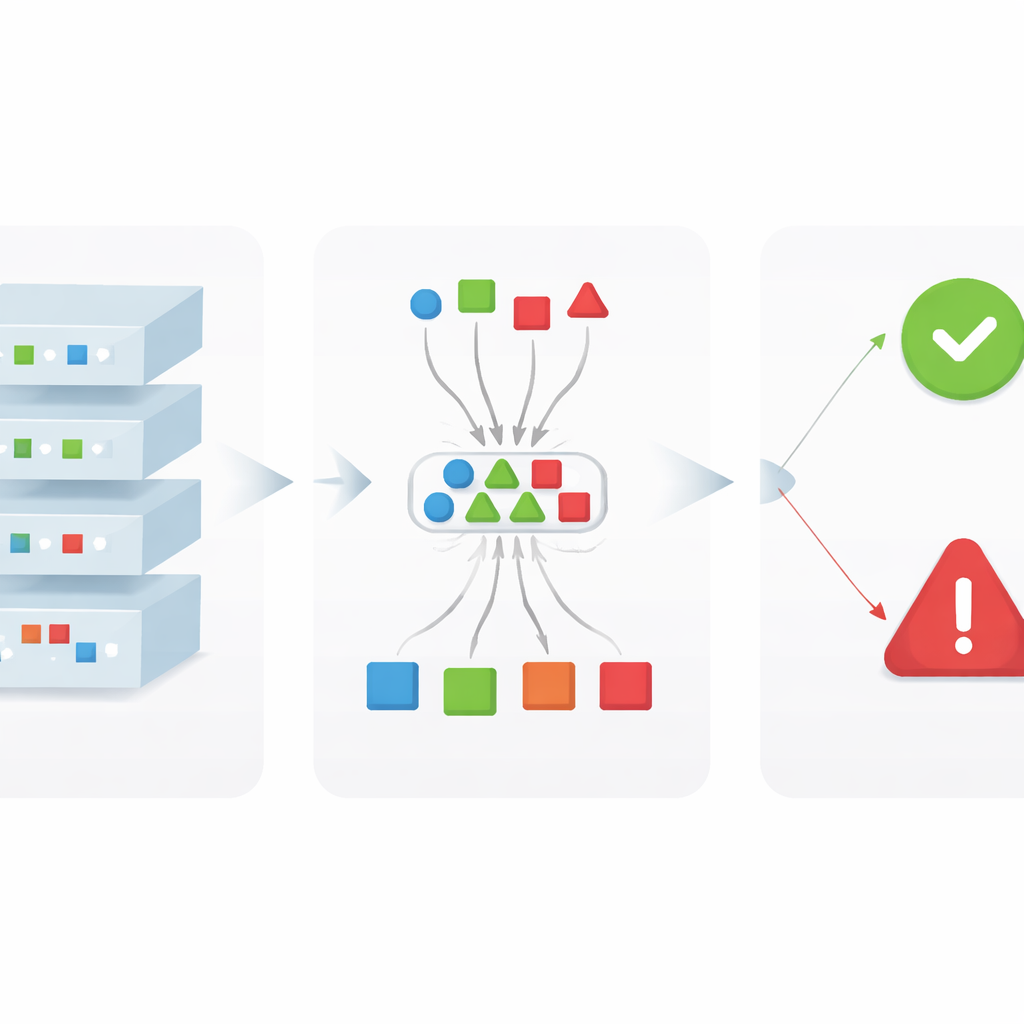
Deixar as camadas votarem e transformar votos em regras
Uma vez conhecidos os traços, o xDFAI os usa para examinar novas imagens não vistas. Para uma foto de teste, o framework mede quão semelhantes são as ativações internas dessa foto aos traços armazenados para cada câmera em cada camada. Cada camada, efetivamente, lança votos para os modelos de câmera cujos traços ela mais se assemelha. Uma “votação majoritária” entre camadas resume então com que força a rede, como um todo, apoia cada câmera candidata. Crucialmente, os autores não usam esse voto para substituir a previsão do modelo; em vez disso, usam-no como uma verificação. Regras lógicas simples comparam a votação majoritária com a previsão original: se a câmera prevista também recebe forte apoio de muitas camadas, a decisão é confirmada; se os votos estão dispersos ou favorecem outra câmera, o comportamento é sinalizado como anômalo e mostrado ao perito como um possível erro do modelo.
Testando o framework
Para demonstrar o xDFAI, os autores o aplicam a uma CNN de sete camadas treinada para identificar qual dos 27 modelos de câmera capturou uma imagem, usando um conjunto de dados forense bem conhecido. A CNN base já apresenta desempenho muito bom, classificando corretamente cerca de 97% das imagens de teste. Quando as regras do xDFAI são aplicadas por cima, o sistema sinaliza automaticamente 27 das 37 previsões erradas como suspeitas. Esses casos sinalizados deixam de ser contados como identificações confiantes, o que aumenta a precisão — a fração de decisões aceitas que são realmente corretas — de 97,33% para 99,2%, reduzindo apenas levemente a acurácia geral. Para trabalho forense, onde uma única atribuição errada pode ter consequências graves, esse trade-off é altamente desejável: menos falsos positivos entre as conclusões que os analistas escolhem confiar.
O que isso significa para investigações no mundo real
Este trabalho demonstra que é possível manter todo o poder de um modelo moderno de aprendizado profundo enquanto se adicionam explicações acessíveis ao humano que respeitam regras de integridade forense — sem re-treinamento, sem adulterar o modelo original e sem depender apenas de mapas de calor vagos. Ao expor traços internos estáveis, agregá-los por meio de um esquema transparente de votação e expressar o resultado como regras simples, o xDFAI fornece aos peritos uma maneira de confirmar ou questionar atribuições de câmera geradas por IA. Embora o estudo se concentre na identificação da fonte da câmera, as mesmas ideias poderiam ser estendidas a outras tarefas forenses de atribuição. A longo prazo, abordagens como esta podem ajudar a reduzir a lacuna entre sistemas de IA altamente precisos e o nível de transparência e confiabilidade exigido em tribunais e na prática investigativa.
Citação: Nayerifard, T., Amintoosi, H. & Ghaemi Bafghi, A. Source camera attribution using a rule-based explainable convolutional neural network. Sci Rep 16, 9137 (2026). https://doi.org/10.1038/s41598-026-40387-9
Palavras-chave: forense digital, IA explicável, identificação de câmera, redes neurais convolucionais, forense de imagens