Clear Sky Science · pt
Uma abordagem de aprendizado de máquina baseada em kNN para automatizar a avaliação de causalidade de eventos adversos
Por que isso importa para pessoas que tomam medicamentos
Quando um novo medicamento chega ao mercado, sua história está apenas começando. Milhões de pessoas o usarão no mundo real e algumas experimentarão problemas de saúde que podem ou não ser causados pelo fármaco. Determinar quais reações são realmente relacionadas ao medicamento é vital para a segurança dos pacientes, mas hoje esse trabalho é lento, complexo e em grande parte manual. Este estudo investiga como uma forma simples, porém poderosa, de inteligência artificial pode ajudar especialistas a revisar esses relatórios de segurança mais rapidamente e com maior consistência, sem substituir o julgamento humano que, em última instância, protege os pacientes.
Como histórias de segurança viram dados
Empresas farmacêuticas e órgãos reguladores dependem de relatórios de segurança de casos individuais, que são resumos estruturados das experiências reais das pessoas com medicamentos. Cada relatório pode incluir o que deu errado (por exemplo, dor de cabeça ou problema hepático), quão grave foi, quais outros medicamentos e doenças estavam presentes e o que o revisor original pensou sobre a ligação com o fármaco. Para mais de 800.000 relatórios desse tipo, referentes a seis medicamentos comercializados, os revisores médicos da empresa já haviam decidido se cada evento adverso estava relacionado ao medicamento, não estava relacionado ou era impossível de julgar porque faltavam informações ou havia conflitos. Os pesquisadores usaram esse rico registro histórico como material de treinamento para um modelo computacional que aprenderia a imitar essas decisões humanas em novos casos.

Ensinando um computador a identificar casos semelhantes
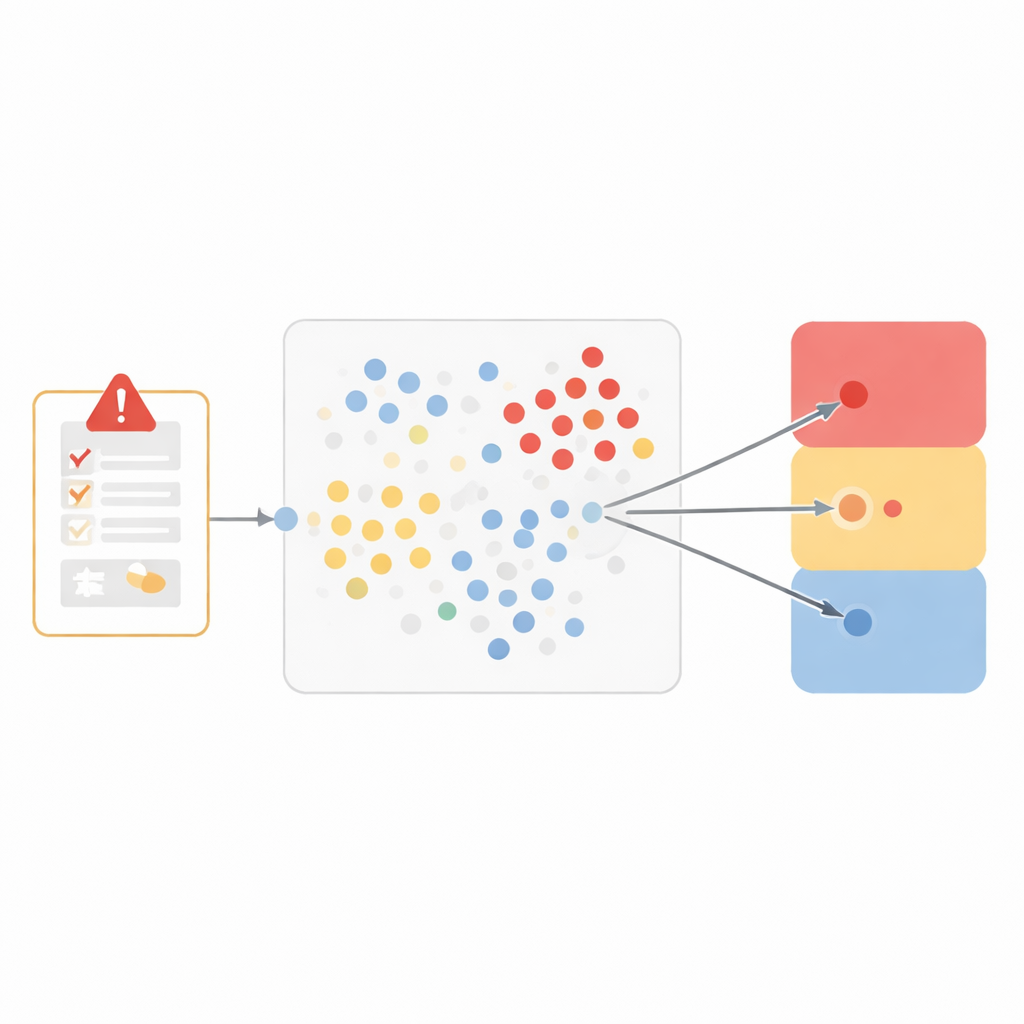
Em vez de construir um sistema caixa-preta, a equipe escolheu um método particularmente transparente chamado “vizinhos mais próximos”. A ideia é intuitiva: se dois casos parecem muito parecidos, provavelmente compartilham a mesma conclusão sobre se o medicamento causou o problema. Para capturar similaridade, os pesquisadores representaram cada evento adverso como um perfil de sete partes, incluindo o termo médico para o evento, o que aconteceu quando o medicamento foi interrompido e reiniciado, se o problema era esperado para aquele medicamento, a opinião do comunicante, outros medicamentos em uso, histórico médico e a gravidade do evento. Em seguida, mediram quão próximos dois casos estavam nesse espaço de sete dimensões, dando mais peso a características que importam mais para a causalidade, como o evento exato e o que ocorreu quando o tratamento foi alterado.
Da proximidade para uma decisão em três vias
Quando um novo relatório chega, o modelo consulta os dados históricos para encontrar os dez casos mais semelhantes. Em seguida, verifica como esses vizinhos foram classificados e os deixa “votar” entre três desfechos amplos: provavelmente relacionado ao medicamento, não relacionado ou improvável, e não passível de avaliação. Essa divisão em três vias equilibra nuance clínica e desempenho confiável. Testado em mais de 250.000 eventos anteriormente não vistos, o modelo correspondia de perto aos revisores humanos para eventos considerados relacionados e para aqueles julgados não avaliáveis, com baixas taxas de erro e fortes pontuações que combinam precisão e completude. Teve mais dificuldade com o grupo menor de eventos claramente não relacionados, refletindo o desafio que sistemas de aprendizado de máquina enfrentam quando um tipo de exemplo é relativamente raro.
Reduzindo a névoa do “não é possível determinar”
Um problema prático no trabalho de segurança do mundo real é que o rótulo “não passível de avaliação” pode se tornar um guarda-chuva quando as informações são escassas ou ambíguas, o que dificulta enxergar padrões reais de segurança. Os pesquisadores adicionaram uma ferramenta de ajuste que torna o modelo mais cauteloso ao atribuir esse rótulo. Em vez de escolher “não passível de avaliação” sempre que ele vence por maioria simples entre casos semelhantes, o modelo agora exige uma porcentagem maior de vizinhos apoiando essa escolha. Ao elevar esse limiar, a equipe conseguiu reduzir drasticamente a frequência com que o modelo classificava um caso como não avaliável e melhorar o desempenho para as outras duas categorias, ao custo de algum aumento na discordância para os eventos mais difíceis de julgar. Um painel baseado na web permite que os revisores médicos ajustem esse limiar por produto, vejam instantaneamente como o equilíbrio de desfechos muda e concentrem sua atenção em casos onde o modelo e os humanos discordam.
O que isso significa para a segurança de medicamentos no futuro
Para uma amostra de casos recentes que revisores humanos haviam rotulado como não avaliáveis, o sistema destacou centenas onde sua conclusão foi diferente. Quando revisores seniores reexaminaram esses casos, concordaram com o modelo em mais de dois terços das ocasiões, mostrando que essas ferramentas podem sinalizar padrões negligenciados e apoiar a supervisão de qualidade em vez de substituir especialistas. O trabalho demonstra que uma abordagem clara, baseada em similaridade, pode introduzir a inteligência artificial na segurança de medicamentos de forma explicável, ajustável e alinhada com a prática médica. À medida que mais dados se acumularem e narrativas em texto forem adicionadas usando tecnologias modernas de linguagem, sistemas como esse poderão ajudar a garantir que riscos emergentes sejam detectados mais cedo, mantendo os clínicos firmemente no controle das decisões finais.
Citação: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
Palavras-chave: farmacovigilância, eventos adversos relacionados a medicamentos, avaliação de causalidade, aprendizado de máquina, k vizinhos mais próximos