Clear Sky Science · pt
Estratégias de aprendizado de máquina em conjunto para mapeamento de prospectividade mineral sob escassez de dados
Encontrando minério com menos pistas
A sociedade moderna depende de metais como chumbo e zinco para baterias, eletrônicos e infraestrutura, mas os depósitos mais fáceis já foram descobertos. Em novas regiões, geólogos frequentemente dispõem apenas de algumas descobertas minerais confirmadas, amostras químicas esparsas e mapas incompletos para orientá‑los. Este estudo mostra como usar aprendizado de máquina não para perseguir a maior pontuação possível em dados passados, mas para gerar previsões nas quais os tomadores de decisão possam realmente confiar quando a informação é escassa.
Por que os dados são escassos no mundo real
O mapeamento de prospectividade mineral busca destacar partes de uma paisagem com maior probabilidade de conter minério. Ele combina camadas de informação, como tipos de rocha, falhas, imagens de satélite e química de sedimentos de drenagem, em um mapa de probabilidades que orienta o trabalho de campo e a perfuração. Em projetos em estágio inicial, porém, apenas alguns depósitos são conhecidos e muitas áreas do mapa nunca foram amostradas. Ferramentas padrão de aprendizado de máquina prosperam com conjuntos grandes e bem rotulados; quando enfrentam apenas algumas dezenas de exemplos positivos, podem ficar instáveis e excessivamente confiantes, fornecendo números que parecem precisos, mas têm fraca ligação com a realidade.
Transformando pistas esparsas em sinais úteis
Os autores trabalharam no distrito de chumbo‑zinco de Dehaq, no centro do Irã, uma região onde a mineralização está ligada a camadas específicas de calcário, falhas e zonas de alteração química. Eles construíram mapas digitais de rochas hospedeiras, densidade de fraturas e alteração a partir de levantamentos geológicos e imagens de satélite, e extraíram anomalias geoquímicas de 624 amostras de sedimento. Dessas evidências ricas, mas irregulares, foram destiladas apenas 108 localizações rotuladas: 27 com depósitos conhecidos e 81 sem. Para evitar que a classe majoritária dominasse os poucos exemplos de minério, utilizaram uma técnica que cria pontos de depósitos sintéticos realistas interpolando entre os existentes, equilibrando as classes apenas dentro dos dados de treinamento. Isso forneceu um conjunto mais balanceado de exemplos, mantendo conjuntos de validação e teste separados que espelham a raridade do mundo real. 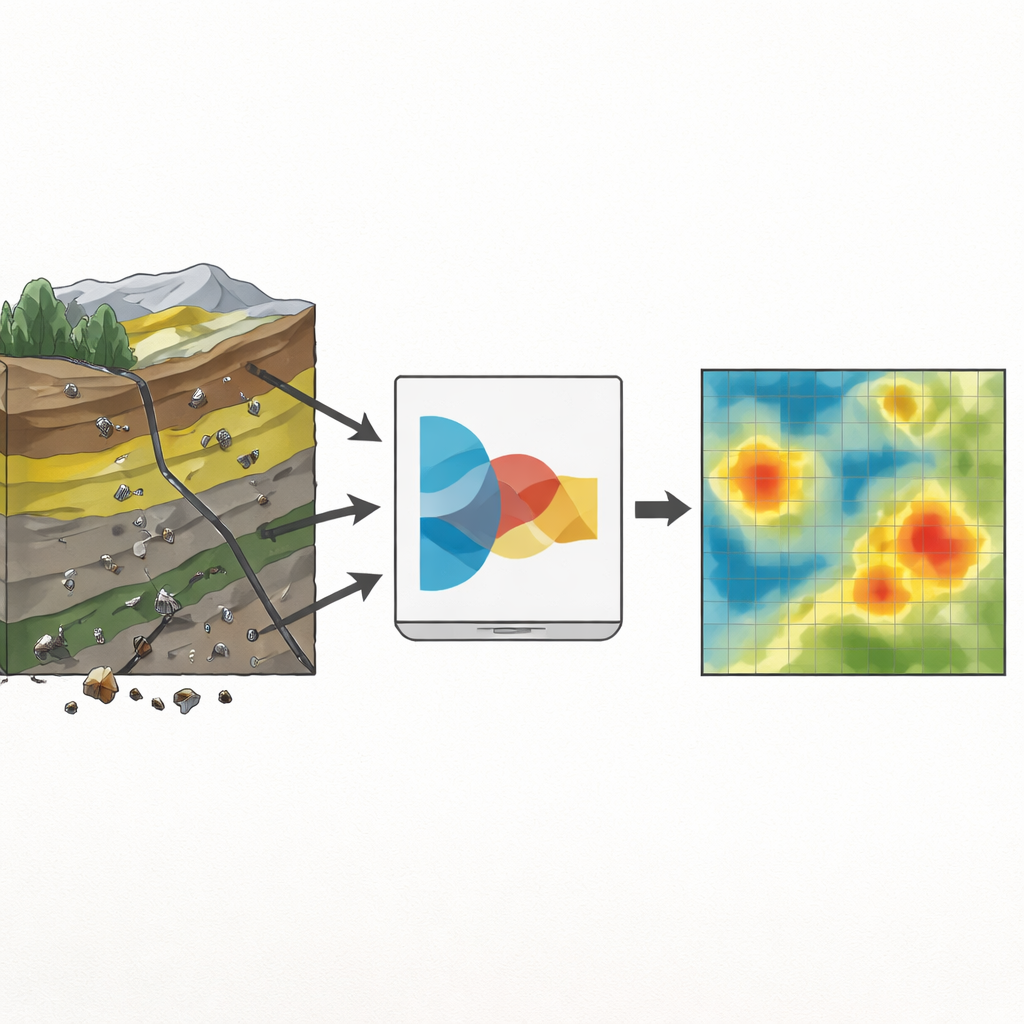
Construindo equipes de modelos em vez de um herói
Em vez de depender de um único algoritmo, o estudo combinou métodos com forças distintas. Um ensemble reuniu uma máquina de vetores de suporte, que traça a fronteira mais nítida possível entre classes, com um modelo probabilístico simples chamado Gaussian Naive Bayes. O outro misturou dois métodos baseados em árvores, LightGBM e AdaBoost, que se destacam em capturar padrões complexos em muitas variáveis. Em ambos os casos, a previsão final foi a média das estimativas de probabilidade dos modelos componentes, uma estratégia que frequentemente reduz oscilações bruscas no desempenho. Crucialmente, os autores compararam não apenas com que frequência esses modelos estavam certos, mas também o quão bem suas probabilidades previstas correspondiam à realidade — uma propriedade conhecida como calibração.
Ajustando para confiança, não apenas para pontuação
Escolher as configurações de um modelo — quão fortemente penaliza erros, quantas árvores cresce, e assim por diante — pode mudar dramaticamente seu comportamento. A equipe testou três estratégias comuns de ajuste: Grid Search, que varre sistematicamente um conjunto fixo de opções; Random Search, que amostra combinações aleatoriamente; e Otimização Bayesiana, que usa tentativas anteriores para inferir novas combinações promissoras. No papel, a Otimização Bayesiana entregou a única maior pontuação de discriminação (uma ROC–AUC de 0,95) para o ensemble baseado em vetores de suporte. Ainda assim, quando os autores examinaram curvas de calibração, que comparam probabilidades previstas com resultados reais, as versões obtidas por Grid Search de ambos os ensembles produziram resultados mais suaves e estáveis, especialmente na faixa de probabilidade intermediária onde geralmente se definem limites para exploração. 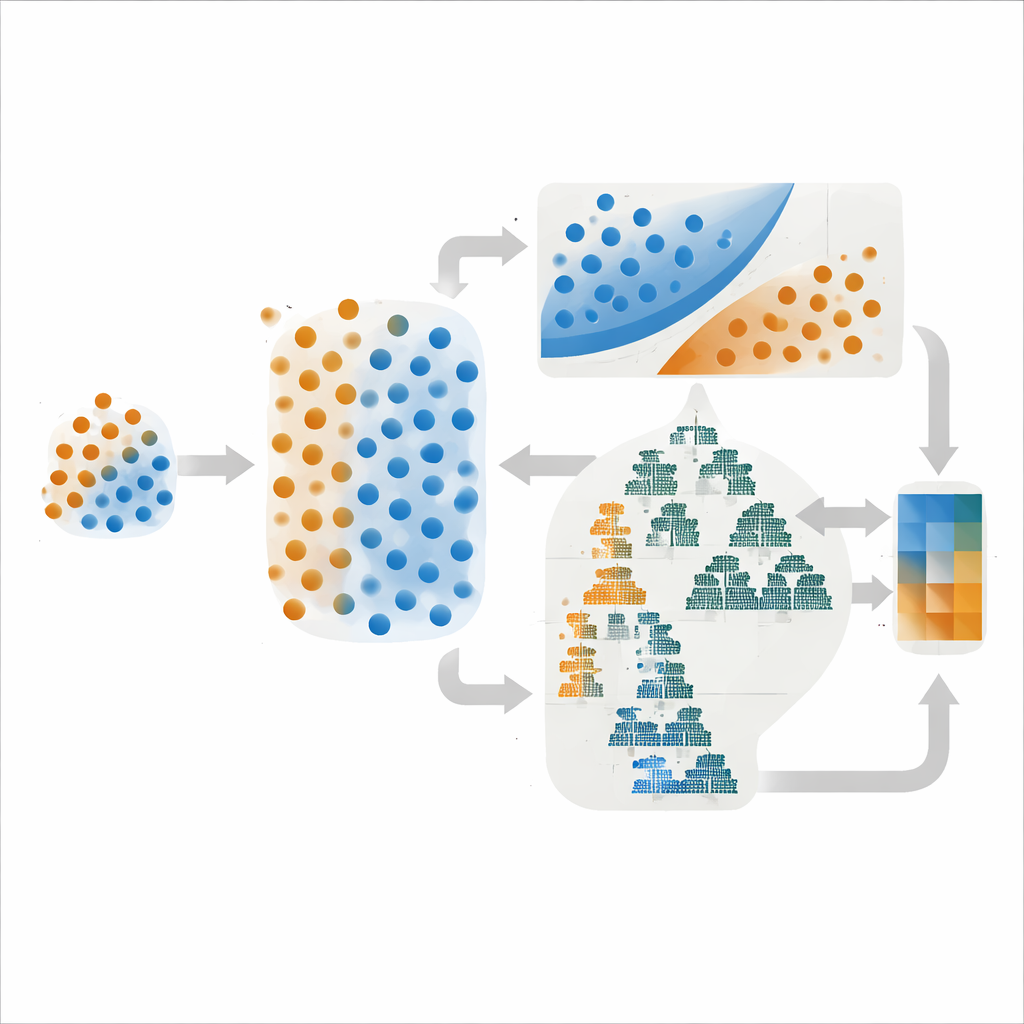
Dos números às decisões de campo
Para exploração inicial, onde cada furo de sondagem é caro, os autores argumentam que probabilidades bem comportadas importam mais do que extrair um pequeno ganho em acurácia. A recomendação mais prática é o ensemble mais simples de máquina de vetores de suporte mais Bayes, ajustado por Grid Search. Ele alcança forte discriminação ao mesmo tempo que oferece a ligação mais confiável entre valores de probabilidade e taxas reais de descoberta, o que permite aos geólogos definir limiares que correspondam à sua tolerância ao risco. À medida que os projetos amadurecem e mais dados se acumulam, modelos mais complexos baseados em árvores, como o ensemble LightGBM, podem ser introduzidos para refinar previsões, mas sempre com atenção à calibração. Deste modo, o aprendizado de máquina deixa de ser um gerador de pontuações em caixa‑preta e torna‑se um parceiro transparente na tomada de decisões conscientes sobre risco acerca de onde buscar a próxima geração de recursos minerais.
Citação: Amirajlo, P., Hassani, H., Pour, A.B. et al. Ensemble machine learning strategies for mineral prospectivity mapping under data scarcity. Sci Rep 16, 9171 (2026). https://doi.org/10.1038/s41598-026-40125-1
Palavras-chave: mapeamento de prospectividade mineral, aprendizado de máquina em conjunto, escassez de dados, calibração de modelos, exploração mineral