Clear Sky Science · pt
KM-DBSCAN: um framework aprimorado de detecção de fronteira baseado em densidade e centróide para redução de dados rumo à IA verde
Por que tornar a IA menor pode torná‑la mais verde
A inteligência artificial tem um custo oculto: eletricidade. Treinar modelos modernos de aprendizado de máquina frequentemente significa processar milhões de pontos de dados em hardware que consome muita energia, o que por sua vez gera emissões de carbono. Este artigo apresenta o KM‑DBSCAN, uma nova forma de reduzir conjuntos de dados antes do treinamento sem descartar as informações que os modelos realmente precisam. Ao manter apenas os dados mais informativos, o método acelera o aprendizado, reduz o consumo de energia e ainda entrega previsões precisas em tarefas que vão do reconhecimento de dígitos manuscritos à detecção precoce de câncer de pele.
Dados demais, energia demais
Por anos, a crença dominante na IA foi que mais dados quase sempre levam a modelos melhores. Embora isso possa melhorar a acurácia, também implica tempos de treinamento mais longos, computadores maiores e contas de eletricidade mais altas. Pesquisadores passaram a distinguir entre "IA Vermelha", que persegue acurácia a qualquer custo, e "IA Verde", que busca equilibrar desempenho com impacto ambiental. Uma rota promissora para uma IA mais verde é a redução de dados: em vez de alimentar um modelo com todos os exemplos disponíveis, identifica‑se um conjunto muito menor de casos que ainda definem bem o problema, especialmente os casos fronteiriços difíceis que determinam as decisões de um classificador.
Misturando duas ideias simples em um filtro inteligente
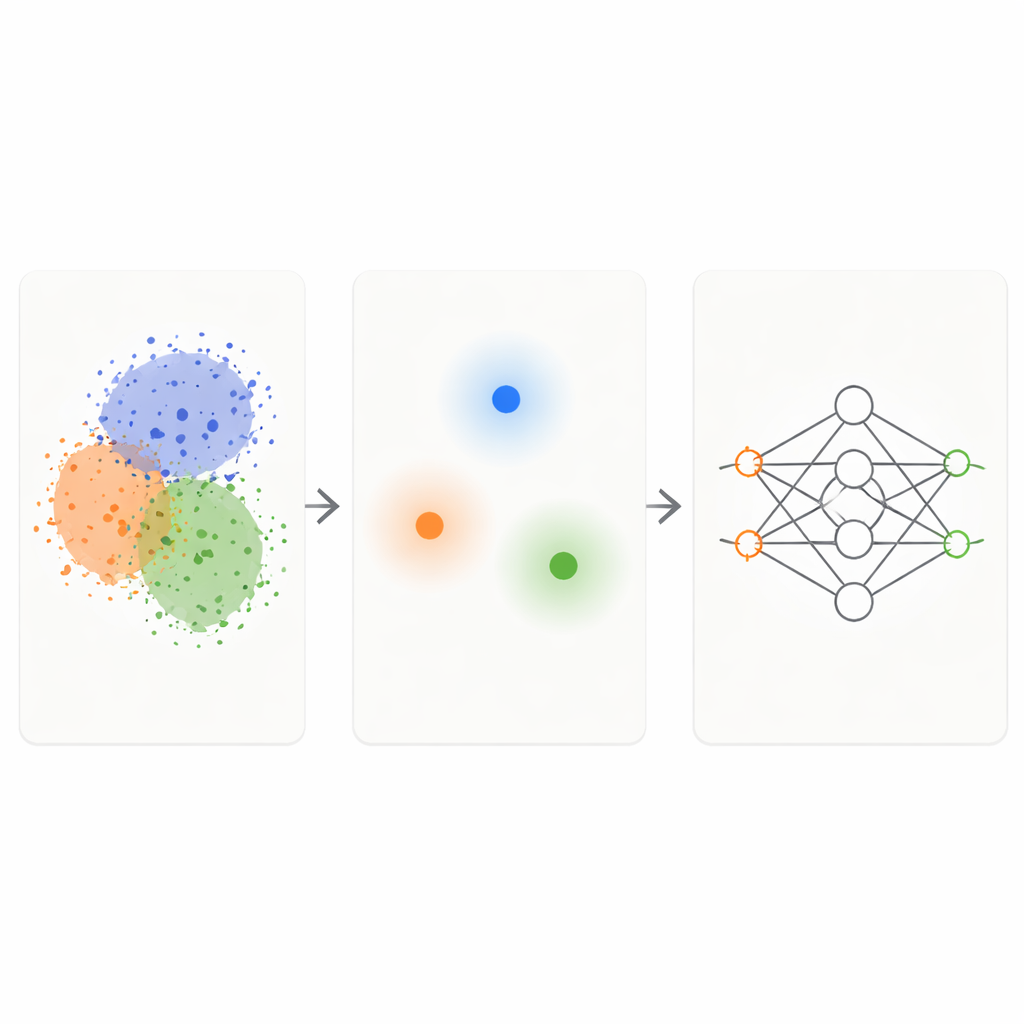
O framework KM‑DBSCAN combina duas técnicas de agrupamento bem conhecidas para atuar como um filtro inteligente sobre os dados brutos. Primeiro, um método rápido chamado K‑Means agrupa pontos em clusters compactos e substitui cada grupo por um centro representativo, ou centróide. Isso reduz o problema de milhares ou milhões de pontos para algumas centenas de representantes. Em seguida, um método baseado em densidade (DBSCAN) é executado sobre esses centróides para identificar quais regiões estão nas fronteiras entre clusters e quais são interiores densos e homogêneos ou ruído isolado. Ao operar no nível dos centróides, o DBSCAN fica muito mais rápido e menos sensível a escolhas delicadas de parâmetros do que quando aplicado diretamente a todos os pontos de dados.

Manter apenas os casos difíceis e informativos
Uma vez que o KM‑DBSCAN identifica onde diferentes grupos se tocam ou se sobrepõem, ele mantém apenas os pontos de dados que estão próximos a essas fronteiras e descarta tanto pontos do interior profundo quanto outliers evidentes. Pontos interiores são em grande parte redundantes: todos parecem semelhantes e enviam ao modelo a mesma mensagem sobre sua classe. Pontos de fronteira, em contraste, dizem ao modelo exatamente onde uma classe termina e outra começa. Em conjuntos de dados sintéticos de brinquedo, essa estratégia reproduz as mesmas fronteiras de decisão que um classificador aprende a partir dos dados completos, mesmo quando a maior parte dos pontos é removida. Em conjuntos de dados do mundo real, como Banana, dígitos USPS, o conjunto de renda Adult, dados de colisões de veículos, variedades de feijão seco e imagens de pele com melanoma, os conjuntos reduzidos preservam a estrutura chave do problema enquanto ficam uma ordem de grandeza menores.
Velocidade, economia de carbono e aplicações reais
Os autores testaram o KM‑DBSCAN como pré‑processamento para vários modelos populares, incluindo máquinas de vetores de suporte, perceptrons multicamadas e redes neurais convolucionais. Em muitos casos, treinar com os dados reduzidos foi de dezenas a milhares de vezes mais rápido, mantendo quase a mesma acurácia—e às vezes até melhorando‑a ligeiramente. Por exemplo, no reconhecimento de dígitos manuscritos, o método reduziu o conjunto de treinamento para apenas 1,4% do tamanho original e ainda aumentou um pouco a acurácia, enquanto tornou o treinamento 284 vezes mais rápido. Em uma tarefa de previsão de renda com classes desbalanceadas, obteve um aceleramento de 6907 vezes usando cerca de 3% dos dados com perda mínima de acurácia. Em um experimento de detecção de melanoma, uma rede neural profunda alcançou mais de 90% de acurácia ao treinar com menos de um terço do conjunto original de imagens de pele, com emissões de carbono reduzidas em mais de 70%.
O que isso significa para a IA do dia a dia
Para não especialistas, a mensagem chave é que seleção mais inteligente pode vencer volume bruto. O KM‑DBSCAN demonstra que escolher cuidadosamente quais exemplos um modelo vê—focando nos casos fronteiriços mais informativos—pode reduzir drasticamente tempo de computação e consumo de energia mantendo previsões confiáveis. Essa abordagem se encaixa bem no impulso mais amplo pela IA Verde, onde a qualidade dos dados e o desenho cuidadoso dos pipelines de treinamento importam tanto quanto o tamanho bruto do modelo. Se amplamente adotado, esse tipo de filtragem consciente de dados poderia tornar tudo, desde análise de imagens médicas até sistemas de segurança viária, mais sustentável, aproximando ferramentas poderosas de IA de organizações que não dispõem de enormes recursos de computação.
Citação: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Palavras-chave: IA verde, redução de dados, agrupamento, eficiência em aprendizado de máquina, detecção de melanoma