Clear Sky Science · pt
Melhoria da esparsidade do sinal-fonte baseada no algoritmo de transformação síncrona de extração de máximos locais para estimativa de matriz mista em UBSS
Desembaralhando sinais ocultos
Muitas das tecnologias de que dependemos — redes sem fio, radares, scanners médicos e até microfones inteligentes — precisam detectar sinais fracos que estão irremediavelmente misturados. Imagine tentar acompanhar várias conversas ao mesmo tempo em um café lotado usando apenas dois ouvidos. Este artigo apresenta um novo método para “desembaralhar” sinais sobrepostos quando há menos sensores do que fontes, um cenário notoriamente difícil. Ao aprimorar a forma como observamos os sinais em tempo e frequência e ao melhorar a maneira como os computadores agrupam dados relacionados, os autores mostram que podem separar misturas com maior precisão e confiabilidade, mesmo em condições ruidosas do mundo real. 
Por que sinais misturados são tão difíceis de separar
Em muitos sistemas, vários sinais independentes viajam pelo mesmo canal e são captados por um pequeno número de receptores. Essa situação, chamada separação cega de fontes subdeterminado, significa que há mais sinais desconhecidos do que medições. Métodos clássicos de separação de sinais geralmente supõem o oposto, por isso falham aqui. Um truque moderno crucial é explorar a esparsidade: em uma representação adequada, cada fonte está ativa apenas em alguns instantes ou frequências. Se, na maioria dos instantes, apenas uma fonte domina, a nuvem de dados observados tende a formar aglomerados cujas direções codificam como cada fonte se misturou nos receptores. Encontrar esses aglomerados com precisão, contudo, depende de ter uma representação em que a energia de cada fonte esteja nitidamente concentrada em vez de espalhada.
Afilando a imagem de um sinal
Para descobrir a esparsidade, engenheiros frequentemente transformam sinais em uma representação tempo–frequência que mostra quais componentes de frequência estão presentes em quais instantes. A simples transformada de Fourier de curto tempo faz isso ao deslizar uma janela no tempo e calcular muitos pequenos espectros, mas ela borrata a energia e não consegue, simultaneamente, fornecer boa resolução temporal e precisão de frequência. Variantes mais avançadas, como synchrosqueezing e synchroextracting, tentam puxar a energia espalhada em direção à crista que segue a frequência instantânea de um sinal. Esses métodos melhoram o foco, mas continuam vulneráveis ao ruído: quando perturbações aleatórias são comprimidas ao longo das mesmas cristas do sinal, o resultado pode ser uma faixa brilhante porém borrada que oculta estruturas finas.
Encontrando picos locais para aumentar a esparsidade
Com base nessas ideias, os autores introduzem a Transformada de Extração Síncrona de Máximos Locais, ou LMSET. Em vez de empurrar toda a energia próxima em direção a uma crista de frequência, o LMSET percorre o plano tempo–frequência e, para cada instante, fixa-se em picos locais ao longo do eixo de frequência. Apenas os coeficientes ao redor desses máximos locais são mantidos e reatribuídos, enquanto o restante é suprimido. Essa mudança simples produz uma representação na qual a energia de cada componente do sinal se concentra em curvas finas e limpas com muito menos pontos dispersos. Em simulações com sinais de teste multicomponentes, o LMSET produz a menor entropia de Rényi, uma medida padrão de concentração, superando métodos convencionais e de ponta em uma ampla faixa de níveis de ruído. Em termos simples, o LMSET fornece uma imagem mais clara de onde cada sinal vive no tempo e na frequência.
Agrupamento mais inteligente para aprender a mistura oculta
Uma imagem mais nítida é apenas metade da batalha; o próximo passo é agrupar os pontos resultantes para estimar a matriz de mistura desconhecida que descreve como cada fonte contribui para cada receptor. Muitas abordagens dependem do fuzzy C-means, um método de agrupamento popular que frequentemente fica preso em soluções ruins porque é muito sensível à estimativa inicial e a pontos discrepantes. Para superar essas fraquezas, os autores acoplam o LMSET a um novo esquema de agrupamento mais robusto. Primeiro, usam um algoritmo de busca baseado em PID, inspirado na teoria de controle, para explorar todo o espaço de possíveis centros de cluster e evitar posições iniciais ruins. Em seguida, introduzem um mecanismo de pesos booleanos para atenuar outliers e empregam uma estratégia baseada em entropia de informação que reduz a sensibilidade às condições iniciais. Juntas, essas etapas permitem que o agrupamento trave nas direções verdadeiras das fontes ocultas de forma mais consistente.
O que os testes revelam
Os autores testam seu pipeline completo — LMSET mais o agrupamento aprimorado — em misturas de sinais de comunicação modulados digitalmente, incluindo QAM, QPSK e FSK, em ambientes silenciosos e ruidosos. Eles comparam as matrizes de mistura estimadas com as reais usando erro angular e erro quadrático médio normalizado. De modo geral, usar LMSET em vez de uma transformada tradicional reduz os erros, porque os pontos de dados formam aglomerados mais compactos e distintos. Entre os métodos de agrupamento, o fuzzy C-means robusto otimizado por PID proposto alcança as menores desvios angulares médios e as melhores pontuações de erro. No conjunto, o método combinado melhora a precisão da estimação da matriz de mistura em quase 20% em relação às abordagens convencionais, mantendo desempenho forte mesmo quando os níveis de ruído são altos. 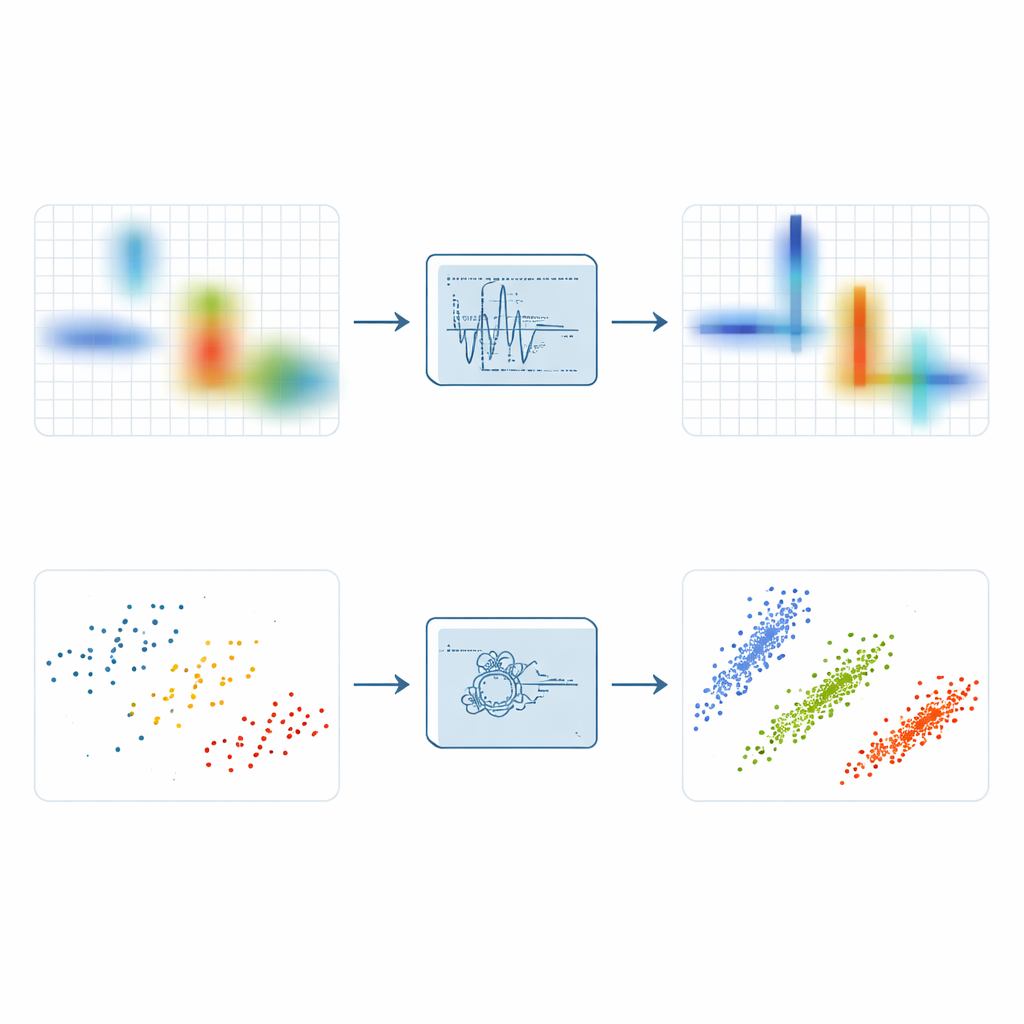
Por que isso importa além da teoria
Para não especialistas, a principal conclusão é que os autores encontraram uma forma melhor de observar e agrupar sinais emaranhados para que cada fluxo original possa ser recuperado com mais clareza. Ao focar em picos locais no panorama tempo–frequência e combinar essa visão com uma estratégia de agrupamento mais cuidadosa, seu método torna o problema impossível do café — muitas vozes, poucos ouvidos — um pouco mais solucionável. Esse avanço pode beneficiar aplicações que vão desde enlaces por satélite que precisam separar transmissões sobrepostas até sistemas médicos que necessitam isolar sinais biológicos fracos enterrados no ruído, oferecendo informações mais claras a partir das mesmas medições limitadas.
Citação: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Palavras-chave: separação cega de fontes, esparsidade do sinal, análise tempo–frequência, algoritmos de agrupamento, comunicações sem fio