Clear Sky Science · pt
Geração de novo e triagem in silico de candidatos a peptídeos antidiabéticos via uma arquitetura deep learning–attention com fusão de características físico-químicas
Por que um desenho de peptídeos mais inteligente é importante para o diabetes
O diabetes afeta centenas de milhões de pessoas no mundo todo e os medicamentos atuais não funcionam perfeitamente para todos. Muitos tratamentos perdem eficácia ao longo do tempo ou causam efeitos colaterais. Uma opção promissora é uma classe de pequenas proteínas chamadas peptídeos antidiabéticos, que podem ajustar a glicemia com alta precisão. O desafio é que descobrir novos peptídeos em laboratório é caro e lento. Este estudo introduz um fluxo de trabalho orientado por computador que pode inventar e filtrar um grande número de potenciais peptídeos antidiabéticos, apontando aos pesquisadores os candidatos mais promissores para testes experimentais.
A partir de peptídeos conhecidos para diabetes até dados iniciais limpos
Os pesquisadores começaram reunindo uma coleção de alta qualidade de peptídeos que demonstraram experimentalmente influenciar a glicemia, principalmente por afetarem hormônios como GLP-1 ou enzimas como DPP-IV. Esses formaram os exemplos “positivos”. Em seguida, construíram um conjunto “negativo” correspondente de peptídeos sem atividade antidiabética reportada, escolhidos cuidadosamente para que comprimento, composição e química básica se assemelhassem aos positivos. Para evitar enganar o modelo com quase-duplicatas, usaram ferramentas de similaridade de sequência para garantir que peptídeos estreitamente relacionados nunca aparecessem tanto nos grupos de treinamento quanto nos de teste. Essa divisão consciente de homologia assegurou que o sistema fosse avaliado pela capacidade de reconhecer padrões genuinamente novos, em vez de memorizar exemplos antigos.
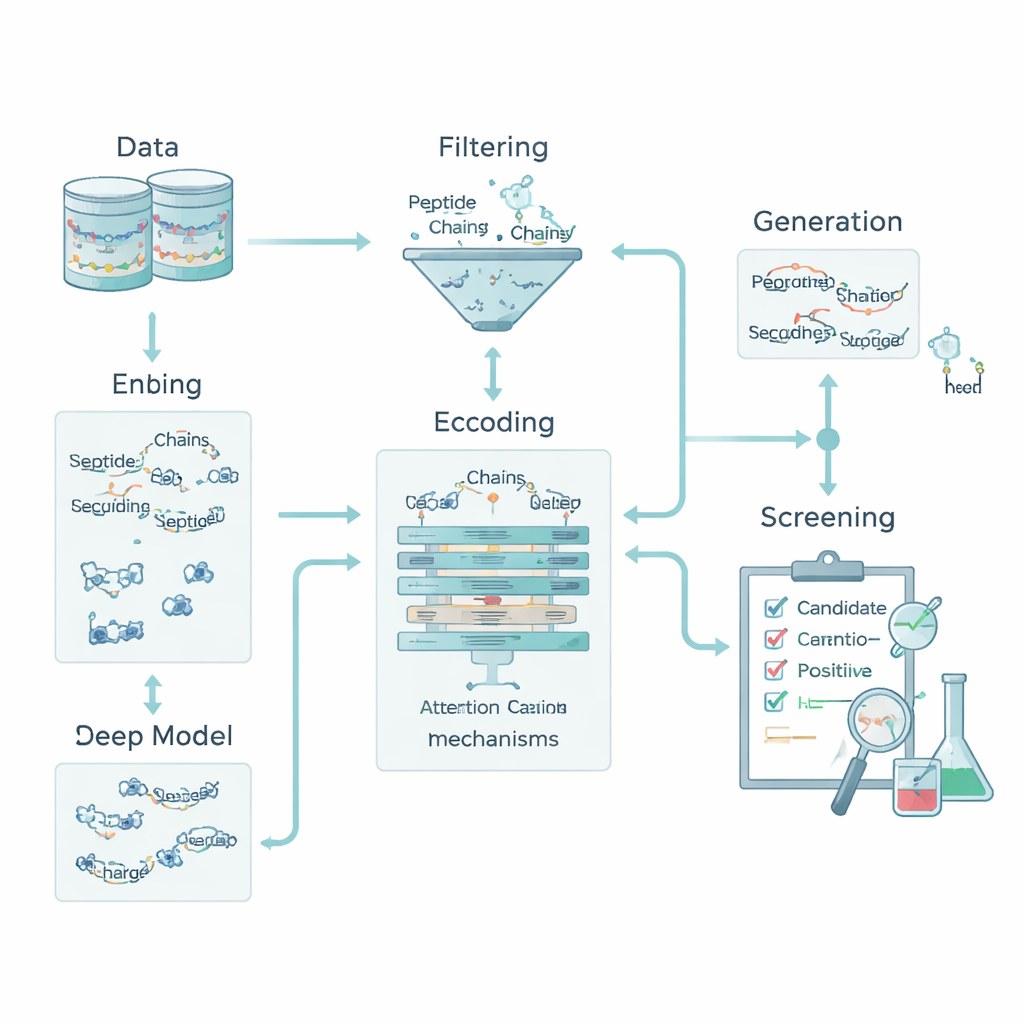
Codificando a química para que máquinas leiam peptídeos
Para um computador, um peptídeo é apenas uma sequência de letras que representam aminoácidos. Para conectar essas letras à biologia, a equipe transformou cada aminoácido em cinco atributos químicos básicos: sua hidrofobicidade, sua carga elétrica, sua tendência a formar ligações de hidrogênio, sua massa e se possui um anel aromático. Isso transformou cada peptídeo em uma pequena “imagem” que captura tanto a ordem quanto a química. Além disso, foram adicionados descritores do peptídeo inteiro, como carga total, hidrofobicidade média e o índice de Boman, que se relaciona à tendência do peptídeo de se ligar a outras proteínas. Juntos, esses recursos permitem ao modelo considerar tanto padrões locais—pequenos motivos de aminoácidos—quanto propriedades globais que influenciam como um peptídeo se comporta no organismo.
Um motor de deep learning que explica suas escolhas
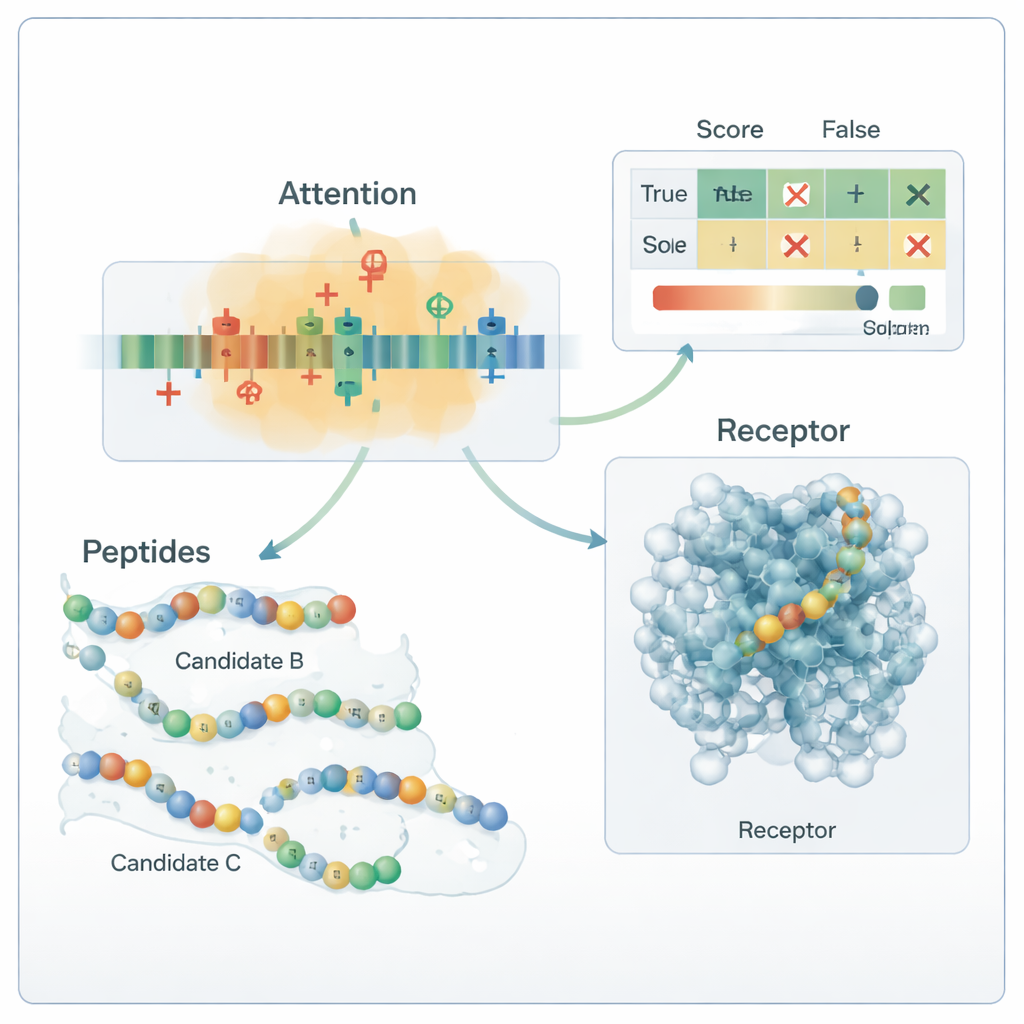
O núcleo do fluxo de trabalho é um modelo híbrido de deep learning. Uma rede neural convolucional (CNN) percorre o peptídeo, procurando por pequenos motivos que tendem a aparecer em peptídeos ativos, de modo análogo a filtros em um sistema de reconhecimento de imagens. Sobre isso, uma camada de attention aprende quais posições na sequência são mais importantes, capturando relações de longo alcance entre resíduos distantes. A saída desse motor de sequência é combinada com os descritores químicos globais e passada para vários classificadores padrão de aprendizado de máquina—support vector machines, árvores de decisão, k-nearest neighbors e árvores com gradient boosting. Um método de otimização especializado, chamado OptimizedTPE, ajusta automaticamente seus parâmetros, equilibrando precisão e risco de overfitting. O mecanismo de attention também fornece “mapas de importância” ao nível de resíduos, ajudando cientistas a ver quais partes de cada peptídeo influenciam as decisões do modelo.
Inventando novos candidatos enquanto evita vazamento de dados
Para superar o pequeno número de peptídeos antidiabéticos conhecidos, a equipe adicionou uma etapa de geração que alimenta apenas o processo de treinamento. Eles usaram uma combinação de estratégias—mutações guiadas, recombinação de motivos e um autoencoder variacional—to propor novas sequências que se assemelham, mas não copiam, peptídeos ativos conhecidos. Esses candidatos foram então filtrados por rígidos “portões de descritor” que impõem cargas, tamanhos e propensão de ligação realistas, além de ferramentas externas que pontuam similaridade com peptídeos bioativos conhecidos. Somente sequências que passam por esses filtros e permanecem claramente distintas de todos os peptídeos de teste são mantidas como positivos fracamente rotulados para treinamento; nenhuma é jamais usada para avaliar o modelo. Essa abordagem ampliou o conjunto de treinamento mantendo um banco de testes limpo e imparcial.
Como o sistema se sai e o que isso significa
Quando desafiado com um painel inteiramente independente de 180 peptídeos estudados experimentalmente coletados da literatura recente, a estrutura rotulou corretamente cerca de 99 em cada 100 sequências, com precisão e recall próximos de 0,99. Em termos práticos, isso significa que raramente deixa de identificar um peptídeo antidiabético verdadeiro e raramente classifica um peptídeo inativo como promissor. Análises dos mapas de attention e testes de mutação mostraram que o modelo aprendeu regras quimicamente sensatas: ele depende fortemente de resíduos carregados positivamente e de certos resíduos hidrofóbicos conhecidos por serem importantes para a ligação a alvos relacionados ao diabetes. Simulações de docking molecular sugeriram ainda que alguns dos peptídeos gerados podem estabelecer contatos plausíveis com o receptor humano GLP-1. Embora essas predições ainda exijam confirmação em laboratório, o estudo demonstra uma maneira reprodutível e biologicamente fundamentada de explorar o vasto espaço de possíveis fármacos peptídicos e priorizar os poucos mais prováveis de ajudar no controle do diabetes.
Citação: Asl, Z.R., Rezaee, K., Ansari, M. et al. De novo generation and in silico screening of anti-diabetic peptide candidates via a deep learning–attention framework with physicochemical feature fusion. Sci Rep 16, 6580 (2026). https://doi.org/10.1038/s41598-026-39985-4
Palavras-chave: peptídeos antidiabéticos, deep learning, descoberta de fármacos, projeto de peptídeos, receptor GLP-1