Clear Sky Science · pt
R-GAT: classificação de documentos sobre câncer aproveitando uma rede residual baseada em grafos para cenários com dados limitados
Por que classificar artigos sobre câncer importa
Cada dia, cientistas publicam centenas de novos estudos sobre câncer, desde detecção precoce até medicamentos promissores. A maior parte desse trabalho surge primeiro como resumos curtos chamados abstracts. Médicos, pesquisadores e formuladores de políticas não conseguem ler tudo, e perder um artigo importante pode atrasar o avanço. Este estudo aborda uma questão simples, porém poderosa: é possível construir um sistema computacional rápido e leve que ordene automaticamente abstracts relacionados ao câncer por tipo de câncer, mesmo quando há apenas uma quantidade modesta de dados rotulados e poder computacional disponível?
Uma maneira mais inteligente de ler pesquisas sobre câncer
Os autores concentram-se em quatro tipos de abstracts encontrados na base PubMed: aqueles sobre câncer de tireoide, câncer colorretal, câncer de pulmão e tópicos biomédicos mais gerais. Eles criaram uma coleção cuidadosamente verificada de 1.875 abstracts recentes, aproximadamente igual em tamanho entre esses quatro grupos. Esse equilíbrio ajuda a evitar viés em favor de qualquer tipo específico de câncer. Antes de qualquer modelagem, os textos foram limpos: palavras foram divididas em tokens, ortografia verificada, formas relacionadas mescladas e termos pouco informativos removidos. Os abstracts limpos foram então convertidos em forma numérica usando vários métodos padrão para que diferentes tipos de modelos pudessem ser comparados de forma justa.
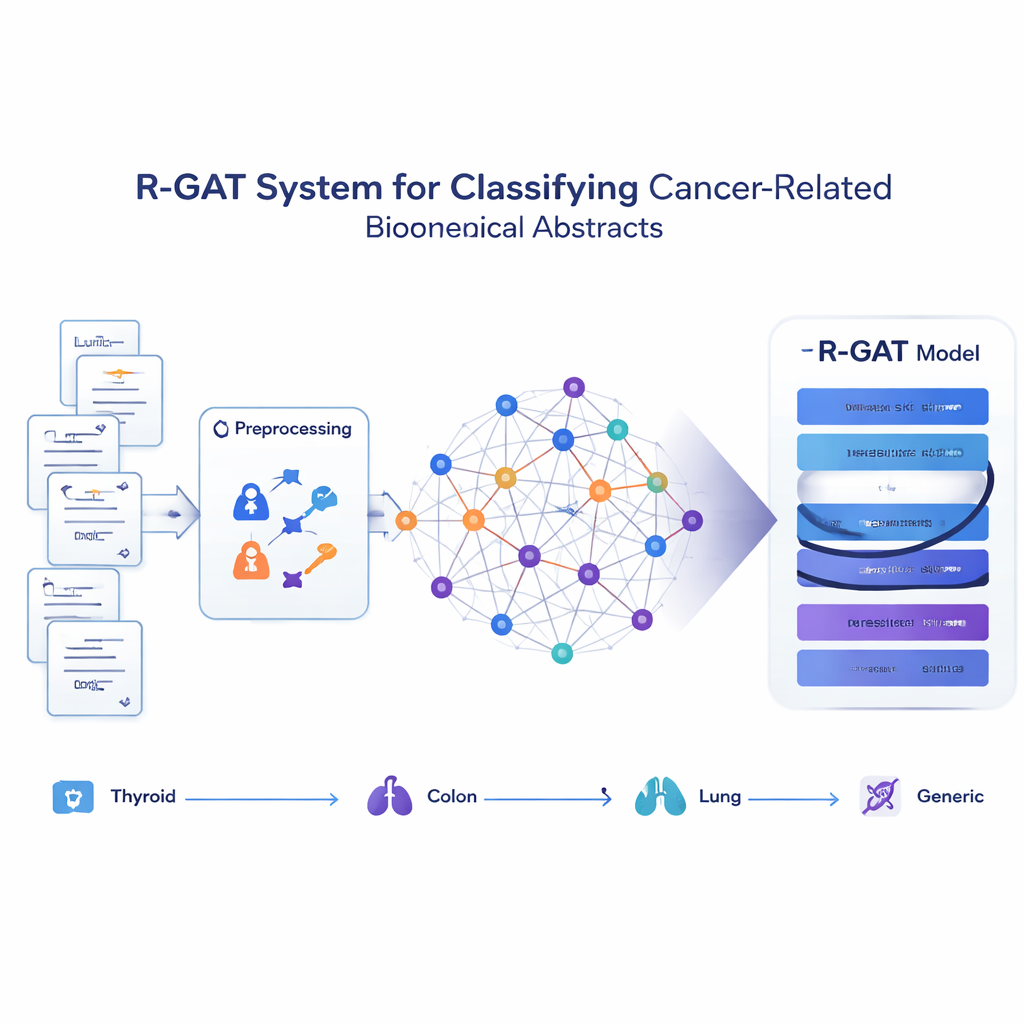
Transformando artigos em uma rede de ideias
Em vez de tratar cada abstract como uma sequência isolada de palavras, o método proposto, chamado R-GAT (Residual Graph Attention Network), enxerga a coleção inteira como uma rede. Nessa rede, cada abstract é um nó, e conexões representam quão semelhantes dois abstracts são em conteúdo. Se dois artigos tratam de tópicos estreitamente relacionados, o vínculo entre eles é forte; caso contrário, é fraco ou ausente. Isso permite que o modelo analise um abstract no contexto de seus vizinhos, imitando como um leitor humano pode entender melhor um estudo ao saber o que trabalhos relacionados dizem.
Como o novo modelo aprende com os vizinhos
O R-GAT baseia-se em duas ideias-chave da inteligência artificial moderna: atenção e conexões residuais. Atenção permite que o modelo foque mais nos abstracts vizinhos mais relevantes na rede, em vez de tratar todos os vizinhos igualmente. Múltiplas "cabeças" de atenção procuram diferentes tipos de padrão ao mesmo tempo. Conexões residuais atuam como atalhos que passam informação através das camadas mais profundas da rede, ajudando o modelo a evitar a perda de sinais importantes durante o aprendizado. Após processar o grafo por várias camadas de atenção e por esses caminhos-atalho, o sistema condensa informação de toda a rede em um resumo compacto que é alimentado a um classificador final, que prevê a qual das quatro categorias cada abstract pertence.
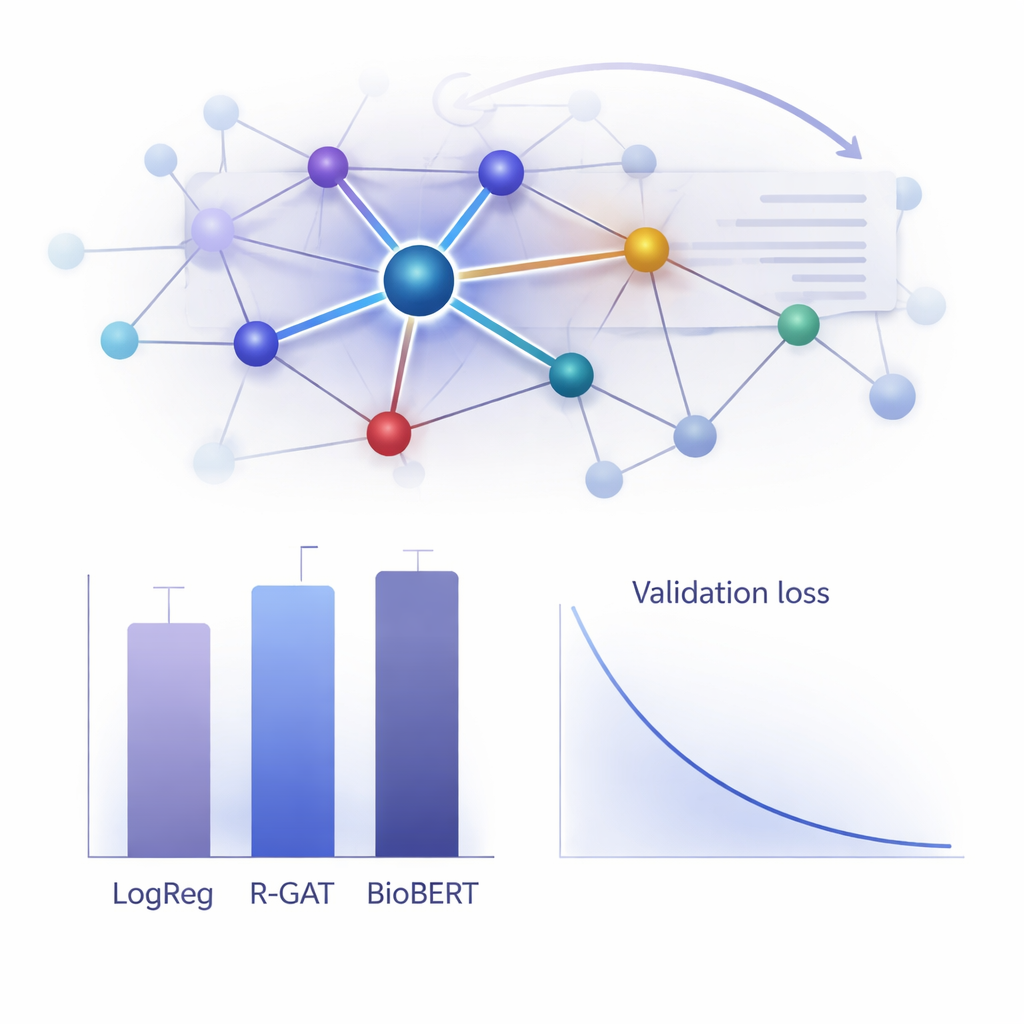
Quão bem isso funciona na prática?
Para avaliar o valor do R-GAT, os autores o compararam a uma ampla gama de alternativas, desde modelos lineares clássicos até sistemas transformadores de ponta como o BioBERT, que são populares porém pesados em termos computacionais. Surpreendentemente, um modelo simples de regressão logística usando características de contagem de palavras alcançou a maior pontuação bruta neste conjunto de dados específico, e o BioBERT também teve desempenho muito bom — mas ambos apresentaram limitações, incluindo dependência de escolhas específicas de características ou necessidade de recursos computacionais substanciais. O R-GAT atingiu uma pontuação macro F1 de cerca de 0,96, próxima aos melhores modelos, mostrando resultados muito estáveis em diferentes divisões treino–teste. Testes cuidadosos nos quais a atenção ou as conexões residuais foram removidas mostraram quedas claras de desempenho, confirmando que ambos os componentes são cruciais para a robustez do modelo quando os dados são limitados.
O que isso significa para a pesquisa futura sobre câncer
Para um leigo, a conclusão é direta: o R-GAT é uma ferramenta prática que ajuda a classificar artigos sobre câncer por tipo com alta e consistente acurácia, sem exigir conjuntos de dados enormes ou hardware caro. Não substitui os modelos de linguagem mais poderosos do mercado, mas oferece um meio-termo confiável — especialmente útil para hospitais, grupos de pesquisa ou equipes de saúde pública que precisam de resultados dependáveis e reproduzíveis sob restrições de dados e orçamento. Ao liberar tanto o modelo quanto o conjunto de dados curado abertamente, os autores também fornecem um benchmark compartilhado que outros podem usar para construir e testar sistemas aprimorados. A longo prazo, tais ferramentas podem facilitar muito que especialistas se mantenham atualizados na literatura sobre câncer e convertam novas descobertas em cuidados melhores.
Citação: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Palavras-chave: informática do câncer, mineração de texto biomédico, classificação de documentos, redes neurais em grafos, aprendizado com dados limitados