Clear Sky Science · pt
EchoNet++: Um conjunto de dados multilíngue de comentários de áudio de partidas de futebol
Por que os sons do futebol importam
Qualquer pessoa que já assistiu a uma grande partida sabe que o rugido da torcida e a variação na voz do comentarista fazem parte do drama tanto quanto os gols. Ainda assim, quase toda a tecnologia esportiva moderna continua focada no que as câmeras veem, não no que os microfones captam. Este artigo apresenta o EchoNet e o EchoNet++, um sistema combinado e um conjunto de dados que transformam o som caótico de transmissões profissionais de futebol de vários países em texto limpo e pesquisável que computadores podem analisar. Isso torna possível estudar tática, emoção e narrativa entre ligas e idiomas em uma escala que nenhuma equipe humana de tradutores poderia alcançar.
Do estádio barulhento ao sinal limpo
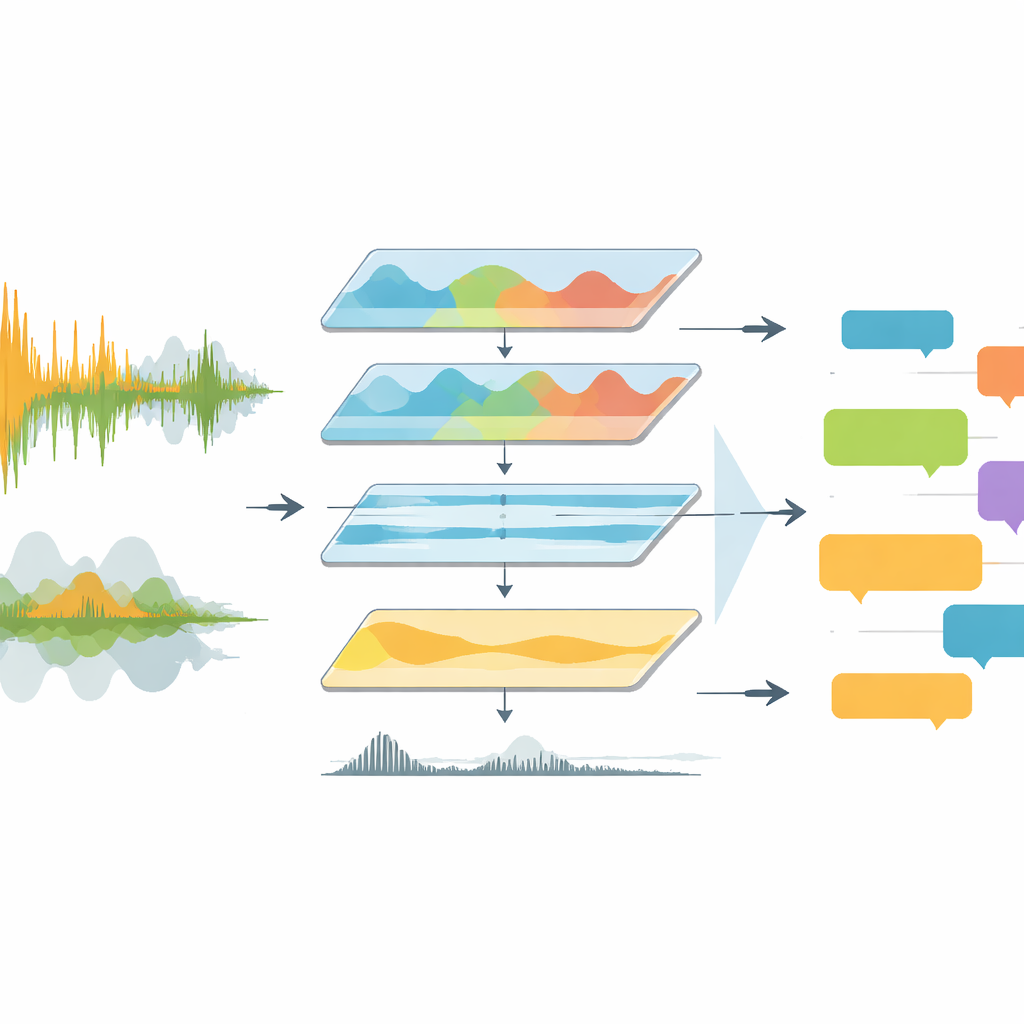
Partidas televisionadas são acusticamente confusas. Comentaristas falam sobre torcidas cantando, música no estádio e explosões súbitas de aplausos. Ferramentas anteriores geralmente alimentavam esse ruído bruto diretamente a softwares de reconhecimento de fala, que tinham dificuldade com vozes sobrepostas, mudanças de idioma e baixa qualidade de áudio. O EchoNet aborda o problema como uma linha de produção de engenharia em vez de um único modelo engenhoso. Começa extraindo a faixa de áudio dos vídeos completos das partidas e convertendo-a para um formato padrão de alta qualidade. O sistema então passa para o domínio da frequência, concentrando-se na faixa onde a fala humana vive enquanto suprime graves retumbantes e artefatos estridentes. Uma ferramenta de aprendizado profundo chamada Demucs separa ainda mais sons semelhantes à fala do resto, deixando uma faixa muito mais clara para as etapas seguintes interpretarem.

Ensinando máquinas a distinguir vozes do ruído
Uma vez que o som é limpo, o EchoNet precisa decidir quando alguém está realmente falando e se essa voz pertence a um comentarista ou à torcida. Para isso, os autores usam um detector neural de atividade de voz que escaneia o áudio em janelas curtas e rotula cada momento como fala ou não-fala. Trechos detectados como fala são então examinados mais de perto. Segmentos que mostram o ritmo e a estrutura constantes da linguagem oral são marcados como comentário, enquanto aqueles que se parecem com explosões de energia caótica são marcados como torcedores. Essa separação importa: frases de comentaristas carregam significado tático e narrativo, enquanto reações da torcida sinalizam principalmente picos emocionais, como gols ou quase gols. Ao separar essas fontes, o sistema pode tratá-las de forma diferente nas análises subsequentes.
Transformando muitos idiomas em uma única narrativa
O EchoNet encaminha cada segmento de comentário para várias versões do modelo de reconhecimento automático de fala Whisper, incluindo variantes padrão e otimizadas para velocidade. Esses modelos são treinados em centenas de milhares de horas de áudio multilíngue, tornando-os bem adaptados às principais ligas da Europa, onde as transmissões alternam entre inglês, alemão, espanhol, italiano, francês e outros idiomas. O sistema registra o tempo, o idioma e a transcrição de cada segmento em arquivos JSON estruturados vinculados aos tempos das partidas. Para clipes não em inglês, o EchoNet primeiro transcreve no idioma original e depois envia o texto para um mecanismo de tradução para obter versões em inglês. Esse design em duas etapas mantém os erros de transcrição e de tradução separados, o que ajuda pesquisadores a depurarem falhas e compararem comportamentos específicos de cada idioma.
Medindo o quão bem tudo funciona
Como uma linha de produção é tão forte quanto sua etapa mais fraca, os autores avaliam o EchoNet por vários ângulos. Eles introduzem uma nova pontuação “Report Accuracy” que converte taxas tradicionais de erro por palavra em uma porcentagem mais intuitiva de conteúdo praticamente correto. Em três conjuntos de dados — incluindo sua coleção recém-lançada EchoNet++ de 20 partidas completas — o pré-processamento com EchoNet reduz consistentemente erros de transcrição e aumenta a Report Accuracy em vários pontos para todo modelo Whisper testado. Medidas de qualidade do sinal, que estimam quão compreensível a fala pareceria a um ouvinte humano, também melhoram de forma significativa após filtragem, redução de ruído e normalização. Estudos de ablação, nos quais componentes individuais como o filtro passa-banda ou o detector de voz são removidos, mostram que cada etapa contribui de maneira relevante tanto para a clareza quanto para a correção.
O que isso significa para torcedores e analistas
Em termos práticos, o EchoNet e o EchoNet++ oferecem uma maneira confiável de transformar horas de comentários multilíngues e ruidosos em texto limpo, alinhado no tempo, e indicadores da torcida. Com essa base, desenvolvedores podem detectar automaticamente eventos-chave pelo tom e pelas palavras do comentarista, correlacionar esses momentos com picos de reação da torcida e construir resumos detalhados ou compilações de melhores momentos sem registro manual. Crucialmente, o conjunto de dados e o código estão sendo disponibilizados para uso em pesquisa, oferecendo à comunidade uma plataforma compartilhada e reprodutível para estudar o futebol por meio do som. Para torcedores e analistas, este trabalho empurra a cobertura esportiva rumo a um futuro em que a trilha sonora do jogo se torna tão pesquisável e analisável quanto o vídeo em si.
Citação: Majeed, F., Nazir, M., Agus, M. et al. EchoNet++: A multilingual soccer match audio commentary dataset. Sci Rep 16, 8884 (2026). https://doi.org/10.1038/s41598-026-39884-8
Palavras-chave: análise de futebol, áudio esportivo, reconhecimento de fala, comentários multilíngues, análise de transmissão