Clear Sky Science · pt
Levando a validação cruzada para o mundo real para avaliar a transferibilidade de modelos de vegetação baseados em satélite
Por que observar a vegetação a partir do espaço importa
Os campos alimentam o gado, sustentam a vida selvagem e armazenam carbono; muitos pecuaristas e conservacionistas hoje dependem de satélites para acompanhar quanto material vegetal está no solo. Novos mapas prometem visões quase em tempo real das condições das pastagens, mas sua precisão em anos incomuns — como secas severas ou temporadas muito úmidas — muitas vezes é aceita sem questionamento. Este estudo faz uma pergunta simples, porém crucial: quão bem os modelos computacionais por trás desses mapas por satélite se mantêm quando o mundo real se recusa a se parecer com os dados em que foram treinados?
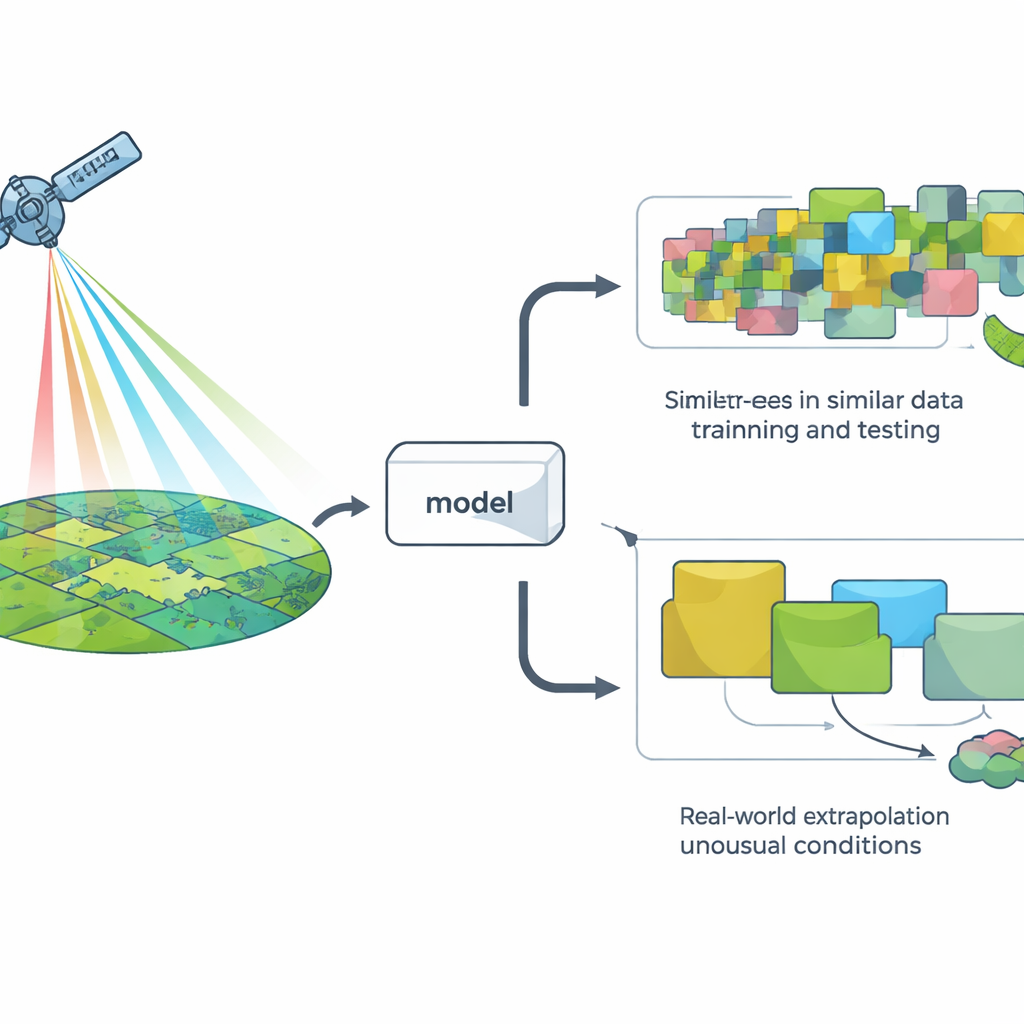
Testar modelos do jeito fácil versus do jeito difícil
Para avaliar um modelo, os pesquisadores costumam usar um método chamado validação cruzada: eles ocultam alguns dados, treinam o modelo com o restante e verificam quão bem ele prediz os pontos ocultos. A versão mais comum divide os dados aleatoriamente, o que funciona bem para muitos problemas, mas pressupõe silenciosamente que todas as observações são independentes. Em paisagens, essa suposição frequentemente falha: lugares próximos e anos vizinhos tendem a parecer semelhantes vistos do espaço. Como resultado, divisões aleatórias podem criar a impressão de que um modelo está enfrentando situações “novas” quando, na verdade, está majoritariamente vendo mais do mesmo.
Submetendo modelos de satélite a testes do mundo real
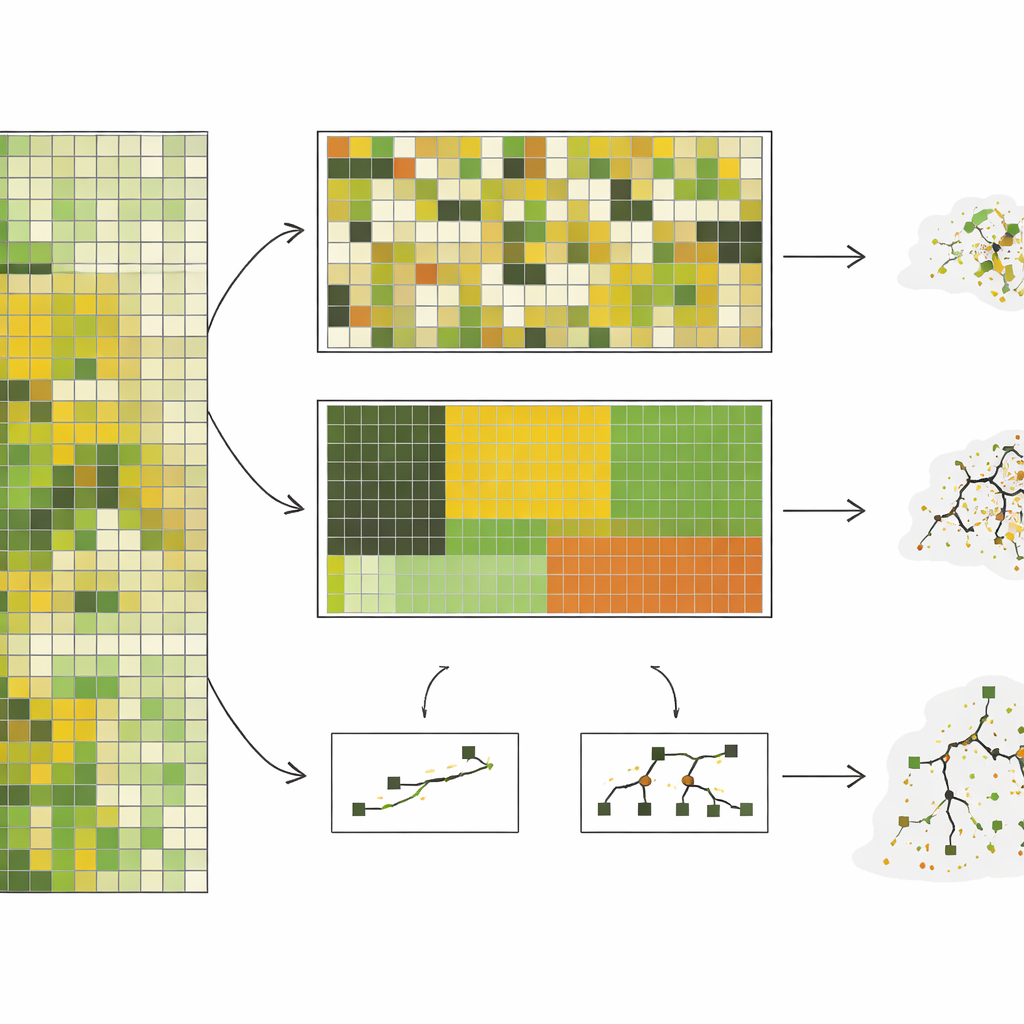
Os autores reuniram quase 10.000 medições no solo de biomassa herbácea em pé — essencialmente quanto material vegetal pastável está presente — de uma estepa de gramíneas curtas no Colorado, coletadas ao longo de 10 anos. Eles emparelharam essas medições com imagens de satélite detalhadas e então treinaram sete tipos diferentes de modelos computacionais, desde abordagens lineares simples até sistemas complexos de árvores de decisão. Em vez de usar apenas divisões aleatórias, testaram cinco formas de separar os dados: por parcelas escolhidas aleatoriamente, por blocos de pastagem, por tipo de sítio ecológico, por ano e por agrupamentos de pixels que pareciam distintos espectralmente. Essas duas últimas abordagens, especialmente agrupar por ano e por clusters espectrais, forçaram os modelos a prever condições realmente diferentes daquelas que haviam visto antes.
Quando o futuro não se parece com o passado
De modo geral, o desempenho dos modelos caiu acentuadamente à medida que os testes se tornaram mais exigentes. Com a divisão aleatória, modelos complexos como florestas aleatórias pareciam impressionantes, explicando cerca de três quartos da variação na biomassa. Mas quando solicitados a prever para um ano totalmente não observado — uma tarefa realista para monitoramento quase em tempo real — sua precisão caiu, e modelos relativamente simples baseados em um punhado de variáveis combinadas de satélite se saíram tão bem quanto ou melhor. No teste mais extremo, em que os dados foram agrupados para serem o mais diferentes possível entre si, a precisão dos modelos complexos desabou, enquanto os melhores modelos simples mantiveram um desempenho moderado e mais previsível. O estudo também mostrou que modelos complexos são altamente sensíveis a se condições raras, como secas severas, estão representadas nos dados de treinamento, às vezes apresentando desempenho muito ruim nesses cenários de alto risco.
Robustos e estáveis superam rápidos e instáveis
Além da precisão bruta, a equipe examinou quão consistente cada modelo era quando re-treinado com subconjuntos levemente diferentes de anos. Métodos mais simples, em especial a regressão por mínimos quadrados parciais, tendiam a identificar repetidamente os mesmos sinais-chave de satélite, exigiam apenas algumas escolhas de ajuste e produziram resultados mais estáveis ao longo dos anos. Abordagens mais complexas frequentemente mudavam quais entradas eram usadas, precisavam de muitos parâmetros de ajuste diferentes e exibiam grandes variações de desempenho de uma execução de treinamento para outra. Para gestores de terras que devem atualizar mapas todo ano conforme novos dados chegam, esse tipo de estabilidade pode ser tão importante quanto a máxima precisão em um ano favorável.
O que isso significa para usar mapas por satélite no campo
Para quem depende de mapas de vegetação baseados em satélite para decidir quando e onde pastorear, reagir a secas ou monitorar a saúde dos ecossistemas, este estudo traz uma mensagem clara. Práticas comuns de teste que embaralham dados aleatoriamente podem pintar um quadro excessivamente otimista de quão bem um modelo irá performar quando o clima oscilar para extremos ou quando aplicado em novos locais. Quando modelos são avaliados de maneiras que imitam seu uso no mundo real — prevendo para novos anos, novos cenários ecológicos ou condições raramente vistas — métodos mais simples e bem comportados podem superar os sofisticados e oferecer orientações mais confiáveis. Na prática, isso significa que os desenvolvedores devem reportar como seus modelos se saem sob vários testes mais rigorosos e realistas, e os usuários devem buscar produtos cuja performance tenha sido verificada nos tipos de situações desafiadoras que provavelmente enfrentarão.
Citação: Kearney, S.P., Augustine, D.J., Porensky, L.M. et al. Bringing cross-validation into the real world to evaluate transferability of satellite-based vegetation models. Sci Rep 16, 9383 (2026). https://doi.org/10.1038/s41598-026-39866-w
Palavras-chave: mapeamento de vegetação por satélite, validação cruzada, biomassa de pastagens, modelos de aprendizado de máquina, monitoramento de secas