Clear Sky Science · pt
Reconhecimento de lugar robusto sob variações de iluminação usando pseudo-LiDAR a partir de imagens omnidirecionais
Robôs que nunca se perdem no escuro
Imagine um robô capaz de reconhecer onde está dentro de um edifício, quer seja ao meio-dia com o sol entrando pelas janelas, quer seja tarde da noite com apenas algumas lâmpadas acesas. Este artigo apresenta uma nova forma de dar aos robôs esse senso confiável de lugar usando apenas uma câmera relativamente barata. Ao transformar imagens planas em informação 3D, os pesquisadores tornam a navegação robótica muito menos sensível a sombras, reflexos e outras mudanças de iluminação que normalmente confundem sistemas baseados em visão.
Por que reconhecer o mesmo lugar duas vezes é difícil
Para um robô, “reconhecimento de lugar” significa perceber: “Já estive aqui antes”, para então se localizar em um mapa e navegar com segurança. Sistemas tradicionais dependem de câmeras comuns ou de sensores de distância baseados em laser conhecidos como LiDAR. Câmeras são baratas e capturam cor e textura ricas, mas a aparência muda drasticamente entre cenas nubladas, ensolaradas e noturnas. O LiDAR é muito mais estável porque mede distância diretamente, mas é volumoso e caro. Alguns robôs combinam vários sensores, elevando custo e complexidade. Os autores deste trabalho seguem outro caminho: mantêm o hardware simples, usando apenas uma câmera omnidirecional que vê ao redor do robô, e aprimoram o software para que o robô raciocine sobre a estrutura 3D em vez da aparência bruta.
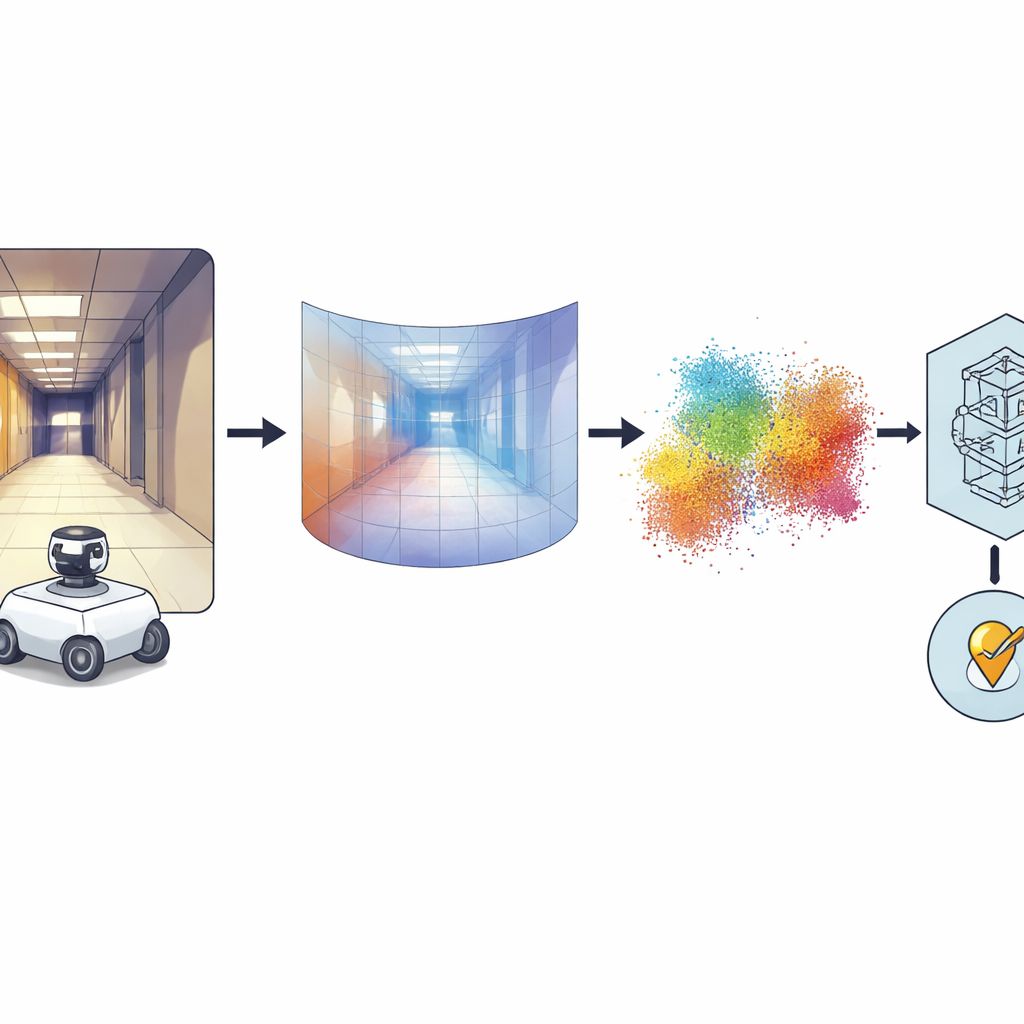
De fotos panorâmicas a formas 3D
A ideia principal é converter cada imagem panorâmica em um mapa denso de profundidade, onde cada pixel codifica quão distante aquela parte da cena está da câmera. Para isso, os autores fazem uso de um poderoso modelo “fundacional” chamado Distill Any Depth, que aprendeu a inferir profundidade a partir de enormes coleções de imagens. O mapa de profundidade resultante é então transformado em uma nuvem de pontos 3D — uma espécie de LiDAR virtual, ou pseudo-LiDAR — sem necessidade de um scanner a laser real. Processamento adicional corrige artefatos introduzidos pelo espelho especial usado na câmera 360 graus, preenchendo regiões ausentes ou ocluídas. Finalmente, uma rede neural chamada MinkUNeXt, projetada para operar diretamente em nuvens de pontos 3D, comprime cada nuvem em uma assinatura compacta que captura a configuração geral do lugar.
Ensinando o sistema a ignorar truques de iluminação
As estimativas de profundidade não são perfeitas, especialmente quando a iluminação muda drasticamente de um momento para outro. Para tornar o sistema robusto, os pesquisadores introduzem um novo truque de treinamento que chamam de Distilled Depth Variations. Em vez de confiar em um único modelo de profundidade, eles deliberadamente misturam previsões de profundidade de várias versões menores e menos precisas do estimador. Esse “ruído” controlado imita os tipos de distorções que aparecem sob diferentes condições de iluminação, forçando a rede 3D a aprender o que realmente importa na geometria de um lugar e o que pode ser ignorado com segurança. Eles também enriquecem cada ponto 3D com informações sobre bordas da imagem e intensidade de textura — características que tendem a ser mais estáveis diante de mudanças de iluminação do que a cor pura.
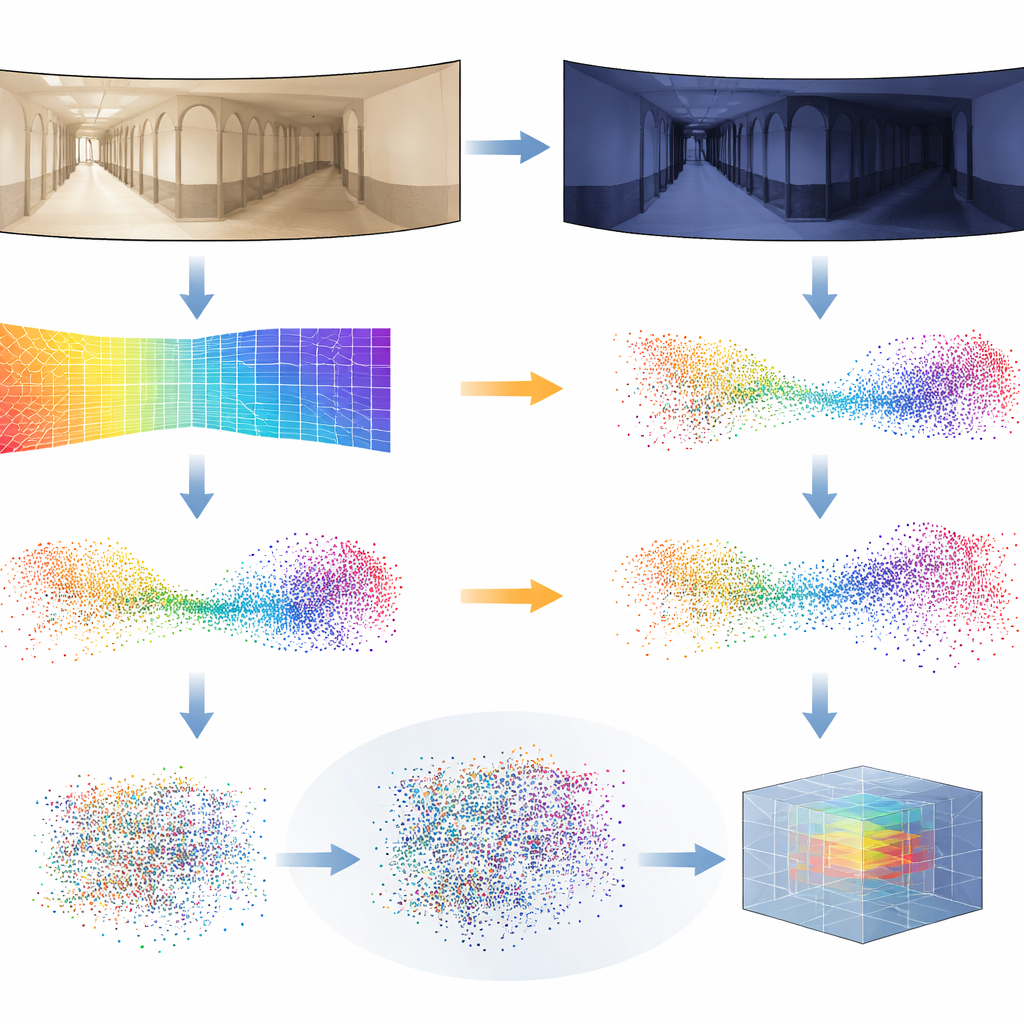
Provando que funciona no mundo real
Para testar a abordagem, a equipe recorreu a conjuntos de dados públicos exigentes de trajetórias internas de robôs. Nestas coleções, um robô percorre corredores e salas várias vezes sob céu nublado, sol forte e à noite, enquanto móveis e pessoas se movem. Os autores treinaram o sistema usando apenas imagens de dia nublado de um prédio e então o avaliaram em todos os prédios e condições de iluminação, incluindo cenas nunca vistas antes. O método de pseudo-LiDAR superou ou igualou de forma consistente técnicas líderes baseadas em imagens 2D e outros sistemas 3D, especialmente nos casos mais difíceis, como execuções noturnas ou transferências para ambientes inteiramente novos. Eles também mostraram que o mesmo pipeline funciona com câmeras frontais comuns, não apenas panorâmicas, ao trocar pela projeção apropriada de profundidade para 3D.
O que isso significa para robôs do futuro
Em termos práticos, este trabalho mostra que um robô pode obter consciência do entorno semelhante à do LiDAR usando apenas uma câmera e software inteligente. Ao focar na estrutura 3D em vez dos detalhes voláteis de iluminação e cor, o sistema pode reconhecer lugares de forma confiável ao longo do dia, da noite e com variações climáticas, mantendo o hardware simples e acessível. Isso pode tornar a navegação interna robusta mais acessível para robôs de serviço, veículos de armazém e dispositivos assistivos, além de abrir caminho para sistemas futuros que combinem profundidade com entendimento de cena em níveis mais altos para autonomia ainda mais confiável.
Citação: Cabrera, J.J., Alfaro, M., Gil, A. et al. Robust place recognition under illumination changes using pseudo-LiDAR from omnidirectional images. Sci Rep 16, 8817 (2026). https://doi.org/10.1038/s41598-026-39848-y
Palavras-chave: localização de robôs, visão 3D, reconhecimento de lugar, estimativa de profundidade, câmeras omnidirecionais