Clear Sky Science · pt
AsynDBT: afinação bilevel distribuída assíncrona para aprendizado em contexto eficiente com grandes modelos de linguagem
Por que prompts melhores importam para a IA do dia a dia
Grandes modelos de linguagem agora alimentam chatbots, mecanismos de busca e assistentes de escrita que muitas pessoas usam diariamente. Ainda assim, obter respostas úteis depende muito de como formulamos nossas perguntas e de quais exemplos mostramos ao modelo. Este artigo apresenta uma nova maneira de refinar automaticamente esses prompts e exemplos entre muitos dispositivos, mantendo os dados de cada usuário privados. O resultado é um sistema de IA que aprende a responder com mais precisão e eficiência, especialmente em tarefas especializadas, como manutenção de redes de telecomunicações.
Ensinar a IA mostrando, sem retreinar
Em vez de retreinar constantemente modelos gigantescos, uma tendência crescente é ensiná-los “no momento” fornecendo alguns exemplos cuidadosamente escolhidos no prompt — um processo conhecido como aprendizado em contexto. Por exemplo, para classificar críticas de filmes como positivas ou negativas, você pode mostrar ao modelo um pequeno conjunto de exemplos rotulados e então pedir que rotule uma nova crítica. O problema é que a escolha dos exemplos e a redação exata das instruções podem mudar dramaticamente o desempenho do modelo. Encontrar boas combinações manualmente é lento e caro, e compartilhar dados brutos entre organizações frequentemente é impossível devido a regras de privacidade.
Cooperar sem compartilhar dados privados
Para contornar barreiras de compartilhamento de dados, os autores se baseiam em aprendizado federado, um esquema em que muitos dispositivos ou organizações mantêm seus dados localmente, mas colaboram por meio de um servidor central. Cada trabalhador — por exemplo, uma estação base de telefonia ou um servidor de empresa — interage com o mesmo modelo de linguagem na nuvem, mas nunca envia seu texto bruto. Em vez disso, devolve apenas sinais de feedback sobre quão bem diferentes prompts e escolhas de exemplos parecem funcionar. Um novo algoritmo chamado AsynDBT (afinação bilevel distribuída assíncrona) coordena esses trabalhadores para que melhorem conjuntamente uma estratégia de prompting compartilhada, respeitando a privacidade e lidando com conexões de rede lentas ou instáveis.
Otimizar tanto a pergunta quanto os exemplos
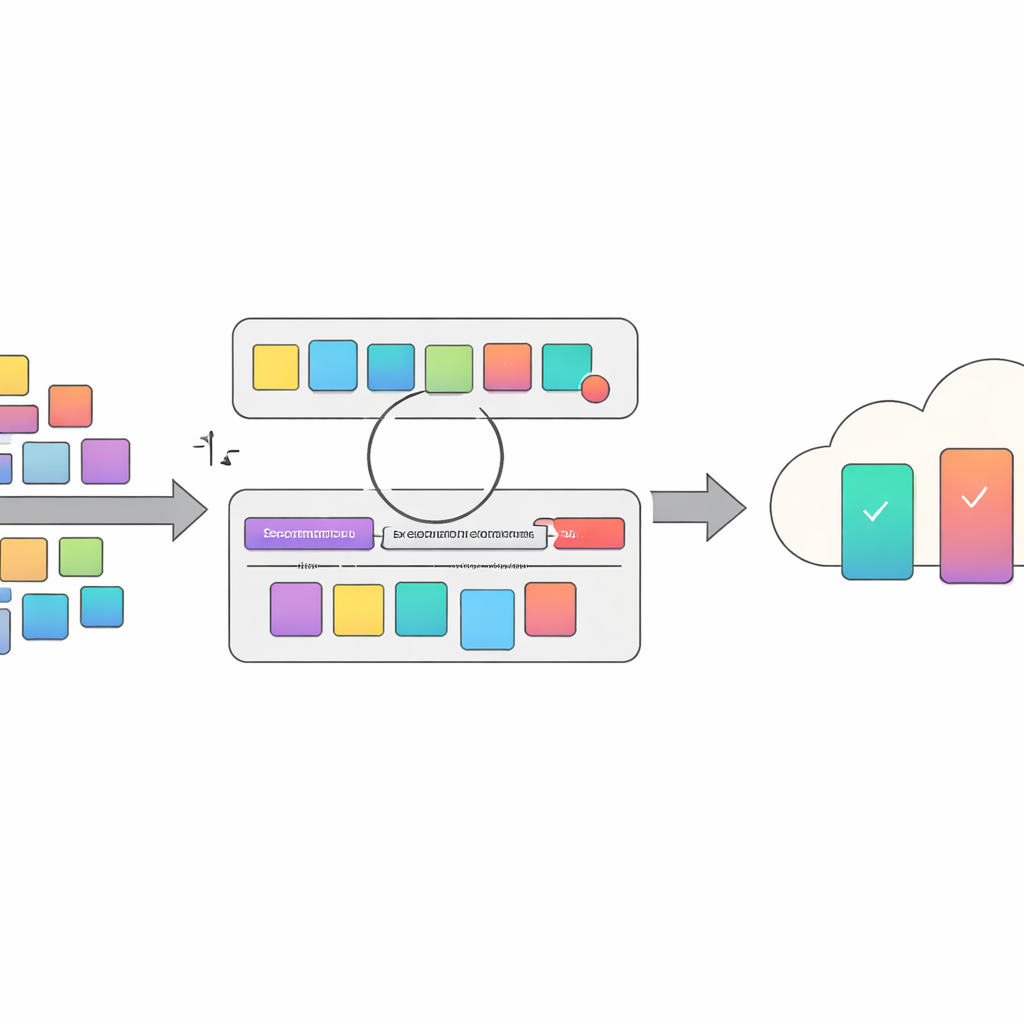
Uma ideia central do artigo é tratar o design de prompts como um problema de otimização em duas camadas. Na camada inferior, o sistema ajusta fragmentos curtos que são anexados à instrução da tarefa — pequenas alterações de redação que podem direcionar o modelo a um raciocínio melhor. Na camada superior, decide quais exemplos rotulados incluir como demonstrações. Essas duas camadas interagem: conjuntos diferentes de exemplos exigem ajustes de prompt distintos, e vice-versa. AsynDBT formaliza essa relação matematicamente e usa um método de aproximação eficiente para que cada trabalhador possa atualizar gradualmente suas escolhas locais enquanto um servidor central mantém uma visão global consistente das decisões da camada inferior.
Lidando com dispositivos lentos e participantes maliciosos
Em redes reais, alguns dispositivos respondem tarde ou caem, criando “atrasados” que podem travar treinamentos sincronizados padrão. AsynDBT opera de forma assíncrona: o servidor atualiza suas variáveis sempre que um subconjunto de trabalhadores reporta, sem esperar por todos. O método também protege contra trabalhadores que possam enviar atualizações enganosas, intencionalmente ou por erro. Ao combinar técnicas de regularização com regras robustas de agregação, o algoritmo reduz o impacto de seleções de exemplos envenenadas ou de baixa qualidade na estratégia global, ajudando o sistema a permanecer estável e confiável mesmo sob ataque.
Ganho comprovado em tarefas de linguagem e telecom
Os pesquisadores testaram o AsynDBT em seis problemas de classificação de texto, incluindo um exigente conjunto de dados de rede 5G em que o modelo precisava avaliar se termos técnicos especializados estavam relacionados, usando apenas fragmentos de padrões de telecom para contexto. Em comparação com uma gama de métodos existentes de prompting e seleção de exemplos, a nova abordagem obteve a melhor ou a segunda melhor acurácia em quase todas as tarefas. No caso da tarefa 5G em particular, melhorou a acurácia em cerca de dez pontos percentuais sobre o melhor baseline. Ao mesmo tempo, o design assíncrono reduziu o tempo de treinamento em aproximadamente 40% em relação a um método centralizado similar que não distribui o trabalho.
O que isso significa para ferramentas de IA futuras
Para não especialistas, a conclusão é que prompts melhores e escolhas de exemplos mais inteligentes podem melhorar de forma notável o comportamento de sistemas de IA — sem alterar o modelo subjacente. AsynDBT oferece uma maneira automatizada e preservadora de privacidade para fazer isso entre muitos dispositivos colaboradores, resultando em ferramentas de linguagem mais precisas e eficientes para domínios como operações de telecom, suporte ao cliente e outras áreas especializadas. Olhando adiante, os autores planejam combinar seu framework com recuperação de conhecimento baseada em grafos para que os prompts também possam recorrer a informações factuais atualizadas, reduzindo ainda mais alucinações e tornando assistentes de IA mais confiáveis em cenários de alto risco.
Citação: Ma, H., Dou, S., Liu, Y. et al. AsynDBT: asynchronous distributed bilevel tuning for efficient in-context learning with large language models. Sci Rep 16, 9381 (2026). https://doi.org/10.1038/s41598-026-39582-5
Palavras-chave: aprendizado em contexto, otimização de prompts, aprendizado federado, grandes modelos de linguagem, IA preservadora de privacidade