Clear Sky Science · pt
Detecção automatizada de fotorreceptores cones usando dados sintéticos e aprendizado profundo em imagens de oftalmoscópio a laser com óptica adaptativa confocal
Visões mais nítidas do olho vivo
Observar as células sensíveis à luz do olho uma a uma pode transformar a forma como médicos detectam e acompanham doenças que causam cegueira. Mas hoje os especialistas precisam marcar essas células manualmente em imagens altamente ampliadas da retina — um processo lento, subjetivo e difícil de escalar para milhares de pacientes. Este estudo mostra como modelos computacionais treinados em imagens “falsas” realistas do olho podem aprender a localizar essas células automaticamente, abrindo caminho para exames oculares mais rápidos, confiáveis e para uma avaliação melhor de novos tratamentos.
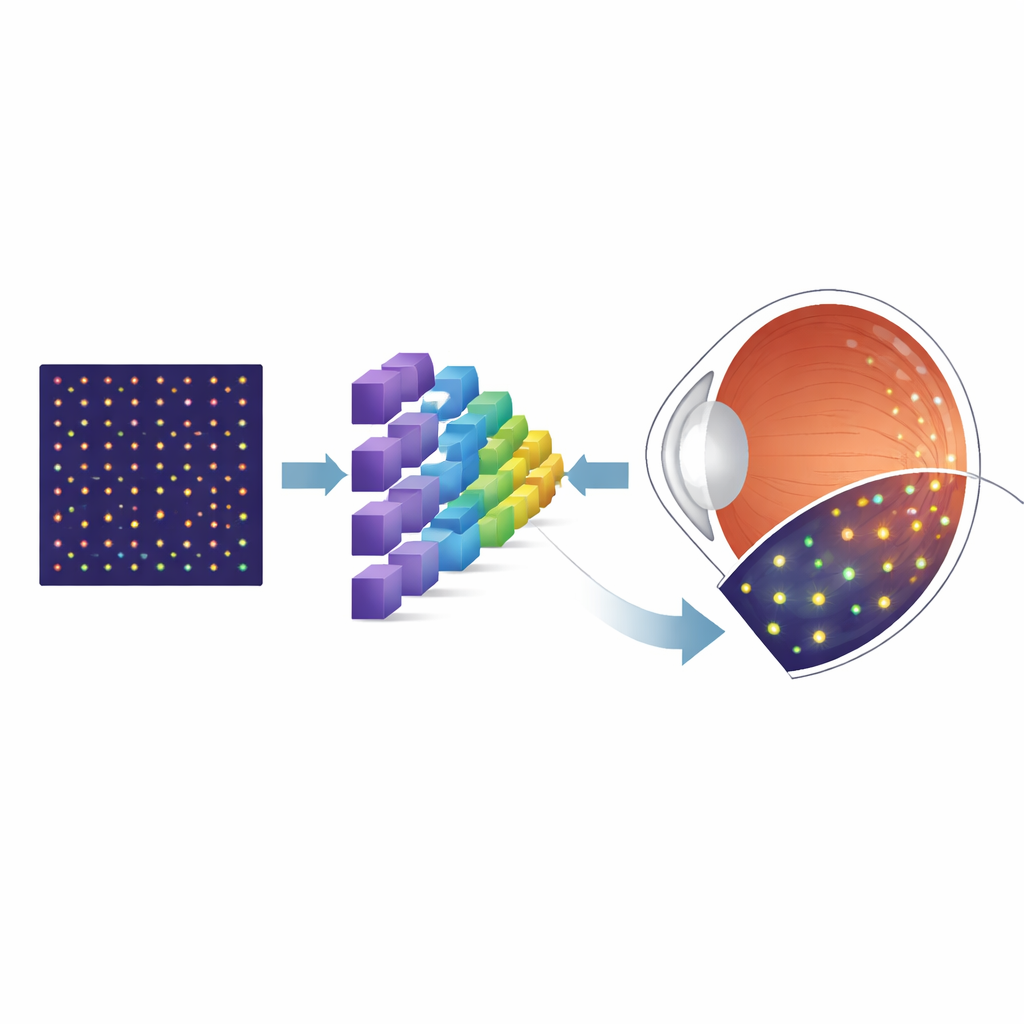
Por que células minúsculas importam
A parte de trás do olho é revestida por fotorreceptores — células especializadas que transformam luz em sinais que nosso cérebro interpreta como visão. Os cones, em particular, são essenciais para a visão central nítida e a percepção de cores, e sua perda é uma característica de muitas doenças retinianas. Uma tecnologia de imagem poderosa chamada oftalmoscopia a laser com varredura e óptica adaptativa (AOSLO) pode capturar fotos detalhadas dessas células em pessoas vivas. No entanto, antes que médicos e pesquisadores possam medir a densidade de cones ou acompanhar mudanças ao longo do tempo, é preciso identificar cada cone individual na imagem. A marcação manual não só consome muito tempo como também pode variar entre avaliadores, limitando sua utilidade em clínicas de rotina e grandes ensaios clínicos.
De regras feitas à mão ao aprendizado a partir de dados
Programas de computador anteriores tentaram automatizar a detecção de cones seguindo regras fixas: por exemplo, procurar pontos brilhantes de certo tamanho ou espaçamento. Esses métodos baseados em regras podiam funcionar bem em imagens limpas de olhos saudáveis, mas frequentemente falhavam quando as imagens estavam ruidosas, levemente desfocadas ou vinham de pacientes com doença. O aprendizado profundo oferece uma estratégia diferente. Em vez de projetar regras manualmente, uma rede neural aprende padrões diretamente a partir de exemplos. O problema é que esses modelos geralmente precisam de grande número de imagens já rotuladas cuidadosamente por especialistas — exatamente o tipo de dado raro e caro em imagens AOSLO.
Construindo um campo de treinamento virtual
Para contornar a escassez de imagens reais rotuladas, os pesquisadores recorreram a uma ferramenta de simulação chamada ERICA, que pode gerar imagens realistas semelhantes às de AOSLO de mosaicos de cones, junto com um “verdadeiro terreno” perfeito indicando onde cada cone está localizado. Eles criaram grandes conjuntos dessas imagens sintéticas cobrindo muitas posições na retina, variando sistematicamente imperfeições chave que afetam imagens reais, como ruído aleatório e desfoque óptico sutil. Em seguida, treinaram uma arquitetura neural especializada, conhecida como U-Net, para transformar cada imagem de entrada em um mapa de probabilidade que mostra onde os cones têm maior probabilidade de estar. Após esse treinamento inicial com dados sintéticos, a equipe ajustou finamente o modelo usando uma coleção muito menor de imagens AOSLO reais de um conjunto de dados público conhecido e, por fim, testou-o em imagens independentes de outro laboratório para avaliar sua capacidade de generalização.

Quão bem o computador se compara a especialistas humanos
A equipe comparou seu método automatizado com a marcação manual meticulosa e com dois algoritmos líderes de detecção de cones. Usando uma medida padrão de sobreposição entre as marcações previstas e as manuais, a nova U-Net igualou ou quase igualou o desempenho dos avaliadores especialistas e dos métodos automatizados concorrentes no conjunto de dados público. Crucialmente, quando testado em um conjunto separado de imagens obtidas a diferentes distâncias do centro da visão e coletadas com um instrumento diferente, o modelo continuou a obter desempenho muito bom. Isso sugere que treinar amplamente com dados sintéticos cobrindo uma ampla gama de condições visuais ajudou a rede a aprender características que transferem para imagens do mundo real, em vez de ajustar-se demais a uma câmera ou grupo de pacientes específicos.
O que isso pode significar para o cuidado ocular futuro
Para não especialistas, a mensagem principal é que um programa de computador treinado em grande parte com imagens “virtuais” do olho agora pode localizar cones reais em imagens retinianas de alta resolução aproximadamente com a mesma confiabilidade que especialistas humanos. Tornando a detecção de cones mais rápida, objetiva e mais fácil de aplicar em diferentes scanners e clínicas, essa abordagem pode ajudar a transformar imagens retinianas detalhadas em uma ferramenta de rotina para acompanhar doenças no nível de células individuais. Em longo prazo, métodos semelhantes orientados por dados sintéticos poderiam ser estendidos para detectar outros tipos de células e modelar a perda celular relacionada a doenças, apoiando diagnóstico mais precoce, monitoramento mais eficaz da progressão e avaliação mais precisa de novos tratamentos destinados a preservar a visão.
Citação: Shah, M., Young, L.K., Downes, S.M. et al. Automated cone photoreceptor detection using synthetic data and deep learning in confocal adaptive optics scanning laser ophthalmoscope images. Sci Rep 16, 8313 (2026). https://doi.org/10.1038/s41598-026-39570-9
Palavras-chave: imagens da retina, fotorreceptores cones, aprendizado profundo, dados sintéticos, óptica adaptativa