Clear Sky Science · pt
Uma estrutura adaptativa de reequilíbrio de dados para predição de risco de tráfego em tempo real
Por que equilibrar os dados de tráfego importa para a segurança
Acidentes em rodovias são eventos raros quando comparados à vasta quantidade de condução comum e sem incidentes. Isso é uma boa notícia para a segurança, mas cria um problema oculto para os computadores que tentam prever quando e onde acidentes podem ocorrer em tempo real. Quando os dados são dominados por situações seguras, os algoritmos podem ficar muito bons em prever “não acontecerá nada” e ainda assim parecerem precisos no papel — enquanto silenciosamente deixam de detectar os momentos realmente perigosos. Este estudo enfrenta esse desbalanceamento de frente, propondo uma maneira adaptativa de “reequilibrar” os dados de tráfego para que sistemas de alerta possam reconhecer melhor condições de risco raras, porém importantes, sem se tornarem lentos demais para uso prático.
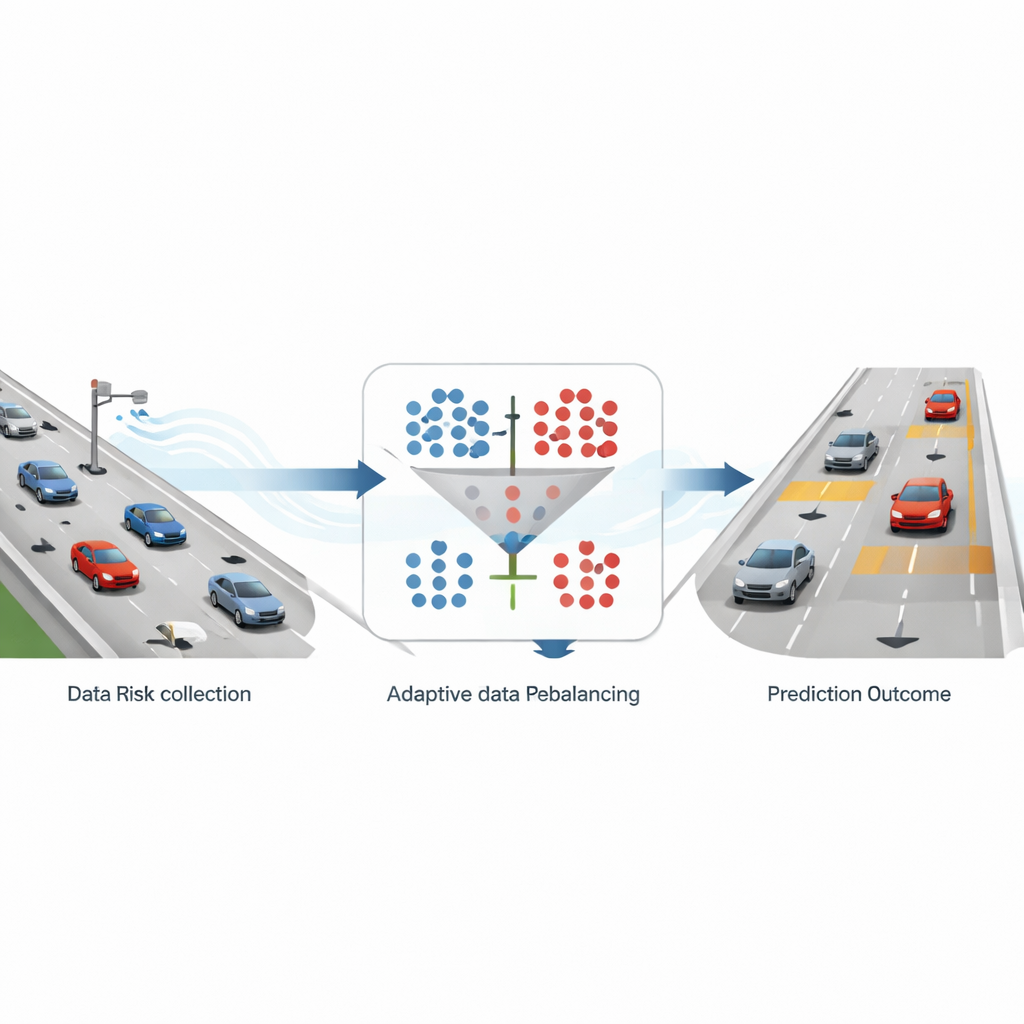
Como o tráfego real é transformado em sinais de alerta
Os pesquisadores constroem sua estrutura sobre dados detalhados de trajetórias em rodovias a partir de um grande conjunto registrado por drones em autoestradas alemãs. A posição e a velocidade de cada veículo são rastreadas muitas vezes por segundo ao longo de trechos de estrada com seis faixas. A partir desse rico registro de movimento, a equipe calcula um indicador de segurança amplamente usado chamado tempo até colisão, que estima quanto tempo levaria para um veículo que segue colidir no carro à frente se ambos mantivessem suas velocidades. Quando esse tempo cai abaixo de três segundos, a situação é rotulada como “alto risco”; caso contrário, é tratada como “sem risco”. Após agregar essas medidas em fatias de 10 segundos e focar em rodovias de seis faixas, eles terminam com cerca de nove amostras seguras para cada uma de risco — um conjunto fortemente enviesado que espelha as condições reais das autoestradas.
Corrigindo o viés sem perder o que importa
Para abordar esse viés, o estudo compara duas estratégias comuns. Uma, chamada oversampling, adiciona mais exemplos das raras situações de risco criando amostras sintéticas semelhantes aos casos reais de alto risco. A outra, undersampling, reduz o grande número de casos seguros descartando aleatoriamente parte deles. Os autores usam um método popular de oversampling (SMOTE) e um método simples de undersampling aleatório, aplicando-os em várias proporções fixas de amostras seguras para arriscadas — 1:1, 2:1, 3:1 e 4:1. Em seguida, eles alimentam tanto os conjuntos de dados originais quanto os alterados em quatro modelos de predição: dois métodos tradicionais de aprendizado de máquina e dois modelos de deep learning especializados em séries temporais. Ao testar todas essas combinações, pode-se ver como diferentes formas de balancear os dados alteram a capacidade do sistema de identificar risco mantendo o reconhecimento de situações seguras.
Deixando um algoritmo buscar o ponto ideal
Em vez de supor que números perfeitamente iguais de amostras seguras e de risco são o ideal, os pesquisadores deixam um algoritmo genético — um método de busca inspirado na evolução — caçar o equilíbrio mais eficaz. Esse otimizador ajusta a razão seguro-para-risco dentro de um intervalo realista de 1:1 a 4:1, gerando repetidamente razões candidatas, avaliando-as e refinando-as ao longo de centenas de iterações. De forma crucial, ele não considera apenas a acurácia de predição: também leva em conta quanto tempo o modelo leva para treinar e fazer previsões, refletindo as demandas em tempo real dos centros de controle de tráfego. Para assegurar que acurácia e tempo de computação possam ser combinados de forma justa, todas as medidas são normalizadas antes de serem mescladas em uma única pontuação de “fitness” que o algoritmo tenta minimizar.
O que os modelos aprendem sobre risco na estrada
Ao longo dos muitos experimentos, um padrão se destaca. Balancear os dados melhora a predição de risco em comparação com deixar o enviesamento original, e o oversampling com casos sintéticos de risco tende a funcionar melhor do que descartar casos seguros. Uma razão de 2:1 entre amostras seguras e arriscadas oferece o melhor desempenho entre as configurações fixas, superando a escolha amplamente usada de 1:1. Quando o algoritmo genético tem permissão para ajustar essa razão, ele converge para valores ligeiramente desiguais, porém ótimos — cerca de 2,3:1 para oversampling e 2,7:1 para undersampling. Entre os modelos de predição, um tipo particular de rede neural recorrente conhecida como gated recurrent unit entrega consistentemente os melhores resultados, especialmente quando combinada com oversampling e otimização. Os modelos também revelam que velocidades médias dos veículos a montante e a jusante de um ponto na rodovia são mais informativas para risco do que contagens simples de veículos.
Verificando estabilidade e preparando para o mundo real
Como métodos de otimização às vezes podem ficar presos em soluções enganadoras, os autores examinam como sua busca se comporta ao longo do tempo. Eles mostram que as pontuações de fitness declinam de forma constante e eventualmente se estabilizam, sugerindo que o algoritmo está convergindo para razões estáveis e de alta qualidade em vez de oscilar. Em seguida, eles ajustam as razões escolhidas para cima e para baixo por alguns por cento para ver se o desempenho desaba. Na prática, a acurácia cai apenas ligeiramente diante de pequenas mudanças, indicando que o sistema é robusto e não excessivamente ajustado a uma configuração única e frágil. No entanto, quando a parcela de dados reservada para teste se torna muito grande, os modelos ficam mais sensíveis, evidenciando a necessidade de dados de treinamento suficientemente ricos.
O que isso significa para rodovias mais seguras e inteligentes
Em termos práticos, o estudo mostra que ensinar computadores a reconhecer perigo na estrada não é apenas sobre modelos engenhosos; trata-se também de alimentar esses modelos com uma visão justa de eventos raros, porém críticos. Ao ajustar cuidadosamente quantos exemplos seguros e arriscados são usados no treinamento — e ao permitir que um algoritmo adaptativo encontre o melhor compromisso entre acurácia e rapidez — a estrutura proposta torna a predição de risco em tempo real nas rodovias mais confiável e mais prática. Agências de tráfego poderiam incorporar essa abordagem a sistemas que monitoram dados de detectores de tráfego e emitem alertas antecipados sobre prováveis colisões traseiras, auxiliando na orientação de alertas a motoristas, distribuição de patrulhas ou estratégias de frenagem automatizada. Embora o trabalho seja demonstrado em rodovias alemãs sob condições climáticas favoráveis, a ideia subjacente do reequilíbrio adaptativo de dados oferece uma receita geral para melhorar predições de segurança em qualquer lugar onde eventos perigosos sejam raros, mas importantes demais para serem perdidos.
Citação: Chen, S., Cui, B. & Chang, A. An adaptive data rebalancing framework for real-time traffic risk prediction. Sci Rep 16, 8882 (2026). https://doi.org/10.1038/s41598-026-39539-8
Palavras-chave: segurança no trânsito, predição de risco de acidentes, dados desbalanceados, aprendizado de máquina, trajetórias em rodovias