Clear Sky Science · pt
Um modelo visão-linguagem médico 3D eficiente em dados usando apenas um codificador 2D
Ajuda mais inteligente a partir de exames 3D
Quando médicos avaliam tomografias ou ressonâncias, eles não observam apenas imagens isoladas — eles montam mentalmente centenas de fatias para compreender o problema em três dimensões. Ensinar computadores a fazer o mesmo poderia acelerar diagnósticos, tornar resultados mais consistentes e produzir relatórios mais claros para pacientes. Mas os sistemas atuais de inteligência artificial que lidam com volumes 3D são extremamente “famintos por dados”, exigindo grandes conjuntos anotados que muitos hospitais simplesmente não possuem. Este artigo apresenta uma maneira de obter compreensão em nível 3D a partir da tecnologia de imagens 2D existente, prometendo ferramentas potentes que são mais fáceis e baratas de construir e implantar.
Por que exames 3D são difíceis para IA
Sistemas modernos visão–linguagem já conseguem analisar uma imagem médica 2D e responder perguntas ou redigir um relatório em linguagem natural. Estender essa capacidade para volumes 3D permitiria ao sistema raciocinar sobre órgãos inteiros e lesões sutis que só ficam claras quando muitas fatias são observadas juntas. O problema é que a maioria dos sistemas 3D atuais depende de codificadores de imagem 3D especiais treinados do zero em enormes coleções de exames anotados. Esses conjuntos são raros, caros de anotar e frequentemente vinculados a centros bem financiados, o que limita quem pode se beneficiar. Ao mesmo tempo, tratar cada fatia como uma imagem 2D separada descarta a continuidade natural entre fatias e afoga o modelo em informação repetitiva.
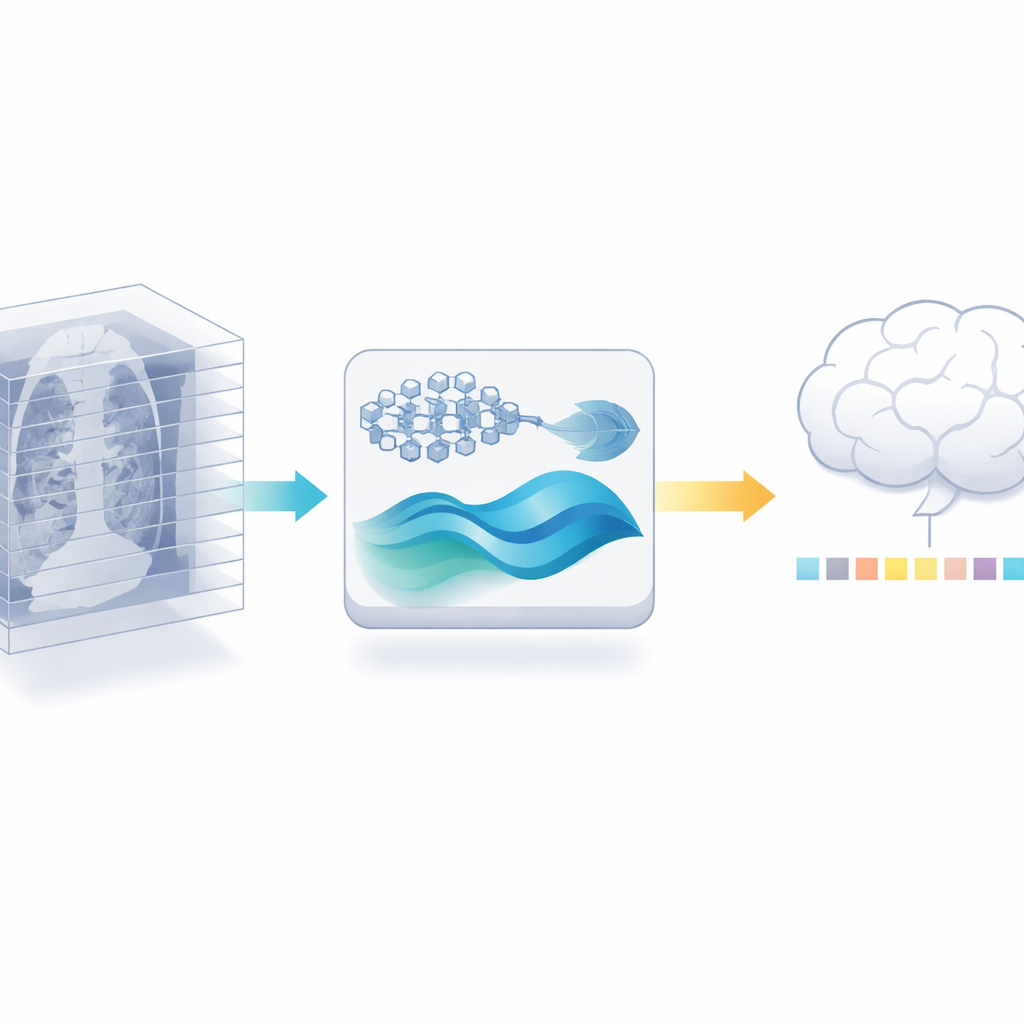
Reaproveitando um especialista 2D para trabalho 3D
Os autores propõem um caminho diferente: em vez de treinar um novo codificador 3D, eles reutilizam um poderoso modelo de imagem médica 2D já treinado em milhões de imagens rotuladas da literatura médica. Primeiro, cortam cada exame 3D em suas fatias individuais e deixam esse modelo 2D extrair características detalhadas de cada fatia. Em seguida, eles reduzem cuidadosamente a redundância: como fatias vizinhas frequentemente parecem quase iguais, uma verificação de similaridade pode descartar muitos quase-duplicados mantendo as vistas mais informativas. Essa etapa sozinha reduz a quantidade de dados que as fases posteriores precisam processar, sem exigir mais exames rotulados.
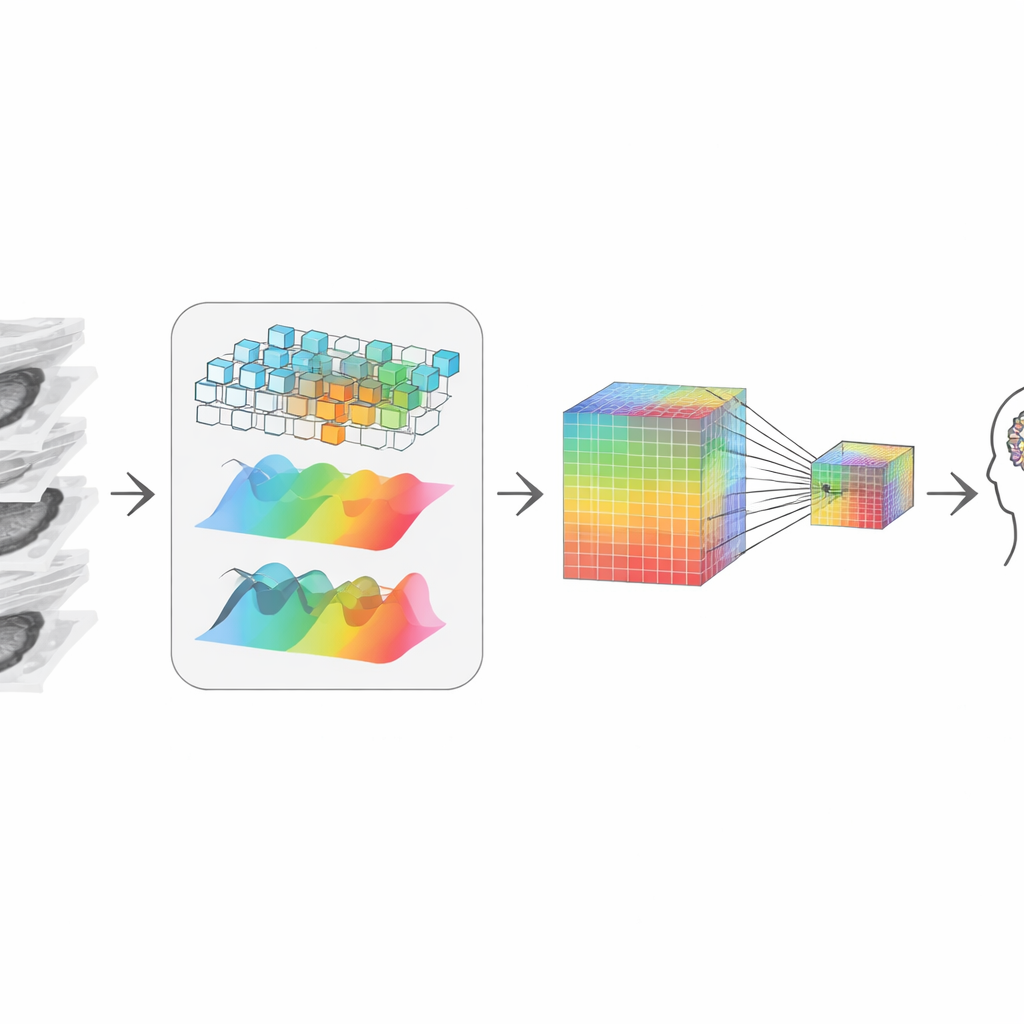
Reconstruindo a história 3D a partir de pedaços
Após a redução, o sistema precisa “reconectar” as fatias restantes em uma imagem 3D coerente. Os autores fazem isso combinando duas visões complementares dos dados. Um caminho observa formas e bordas locais, como uma lupa percorrendo o volume, sensível a limites nítidos e texturas. O outro transforma os dados em uma visão de frequência, que captura melhor padrões amplos e estruturas de longo alcance entre fatias — como um tumor se estende ou como um órgão é moldado em geral. Uma etapa de fusão adaptativa aprende quanto confiar em cada visão em cada ponto, produzindo uma representação que respeita tanto detalhes finos quanto contexto global, apesar de ter começado a partir de fatias 2D.
Preservando pistas minúsculas enquanto comprime
Para se comunicar com um grande modelo de linguagem — a parte que responde perguntas e escreve relatórios — a informação visual deve ser comprimida em um número modesto de tokens, ou “palavras visuais”. Encolher simplesmente borraria sinais pequenos porém críticos, como pequenas calcificações ou mudanças sutis de textura importantes no diagnóstico. Para evitar isso, os autores criam uma representação em duas trilhas: uma mantém uma versão em alta resolução rica em detalhes, e a outra é uma versão menor e mais barata. Um mecanismo de atenção permite que cada ponto na versão menor “olhe para trás” na versão maior e extraia os detalhes mais nítidos disponíveis. O resultado é um resumo visual compacto que ainda carrega as pistas que um radiologista consideraria relevantes, que é então passado ao modelo de linguagem para raciocínio.
Comprovação em tarefas médicas reais
Para testar o desenho, os pesquisadores o avaliaram em benchmarks públicos 3D que pedem duas coisas principais: o sistema consegue redigir descrições no estilo radiológico de exames 3D de forma precisa, e consegue responder perguntas sobre o que é visível neles? A abordagem deles, apesar de nunca treinar um codificador específico 3D, superou vários modelos fortes baseados em 3D em ambas as tarefas. Produziu relatórios mais precisos e clinicamente ricos e respondeu perguntas com maior acurácia, inclusive as difíceis sobre o órgão exato, a anomalia ou a localização envolvida. Também rodou mais rápido, exigiu muito menos dados de treinamento 3D e generalizou bem para diferentes tipos de exame, como RM e PET.
O que isso significa para o cuidado futuro
Em termos práticos, este trabalho mostra que não precisamos começar do zero com modelos 3D famintos por dados para obter assistência de alta qualidade por IA em exames volumétricos. Reaproveitando inteligentemente um especialista 2D robusto, selecionando fatias informativas e reconstruindo a imagem 3D preservando detalhes minúsculos, os autores alcançam desempenho de ponta com muito menos dados e computação. Se amplamente adotada, essa abordagem poderia tornar assistência avançada por IA — como relatórios melhores, explicações mais claras e triagem mais confiável — acessível a hospitais e clínicas que não dispõem de grandes recursos de dados, aproximando a análise sofisticada de imagens da prática clínica rotineira.
Citação: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Palavras-chave: imagens médicas 3D, modelos visão-linguagem, IA em radiologia, aprendizado eficiente em dados, análise de TC e RM