Clear Sky Science · pt
CGDFNet: uma rede de segmentação semântica em tempo real de dois ramos com fusão de detalhes guiada por contexto
Ensinando carros a verem a rua por completo
Carros modernos e robôs dependem cada vez mais de câmeras para entender o mundo ao seu redor — identificando vias, calçadas, pessoas, veículos e sinais em tempo real. Este artigo apresenta o CGDFNet, um novo sistema de visão computacional projetado para realizar esse tipo de “compreensão de cena” de forma mais rápida e precisa, especialmente em ruas urbanas movimentadas. Ao aprender a manter em foco ao mesmo tempo tanto detalhes finos (como postes de semáforo ou rodas de bicicleta) quanto a configuração geral (como vias e edifícios), o CGDFNet visa tornar a condução automatizada e outras tarefas de visão em tempo real mais seguras e confiáveis.
Por que a visão em nível de pixel é tão exigente
Na segmentação semântica, um computador atribui uma categoria a cada pixel de uma imagem: via, carro, pedestre, céu, e assim por diante. Isso é muito mais exigente do que simplesmente desenhar uma caixa em torno de um carro, porque o sistema precisa traçar limites de objetos e formas pequenas com alta precisão. Existem muitos métodos de alta acurácia, mas eles tendem a ser lentos e consumidores de energia, o que é inadequado para sistemas em tempo real em carros, drones ou dispositivos vestíveis. Por outro lado, métodos leves que executam rapidamente frequentemente sacrificam detalhes ou perdem a noção da cena mais ampla, tendo dificuldade com objetos pequenos, estruturas finas ou ambientes urbanos densos.
Dois caminhos: um para detalhe, outro para contexto
O CGDFNet enfrenta essa tensão com um projeto de dois ramos: um ramo foca em detalhes nítidos, enquanto o outro captura o contexto amplo. Com base numa arquitetura backbone eficiente, camadas mais rasas alimentam um “ramo de detalhes” que mantém resolução mais alta para preservar bordas e texturas. Camadas mais profundas alimentam um “ramo de contexto” que vê a cena de forma mais comprimida, adequado para entender a estrutura geral e as relações entre objetos. Ao contrário de projetos anteriores de dois ramos que mantêm essas vias amplamente separadas e depois as somam de forma grosseira, o CGDFNet incentiva a comunicação entre elas ao longo do processamento, de modo que os detalhes finos sejam constantemente verificados com o que a rede sabe sobre a cena global.
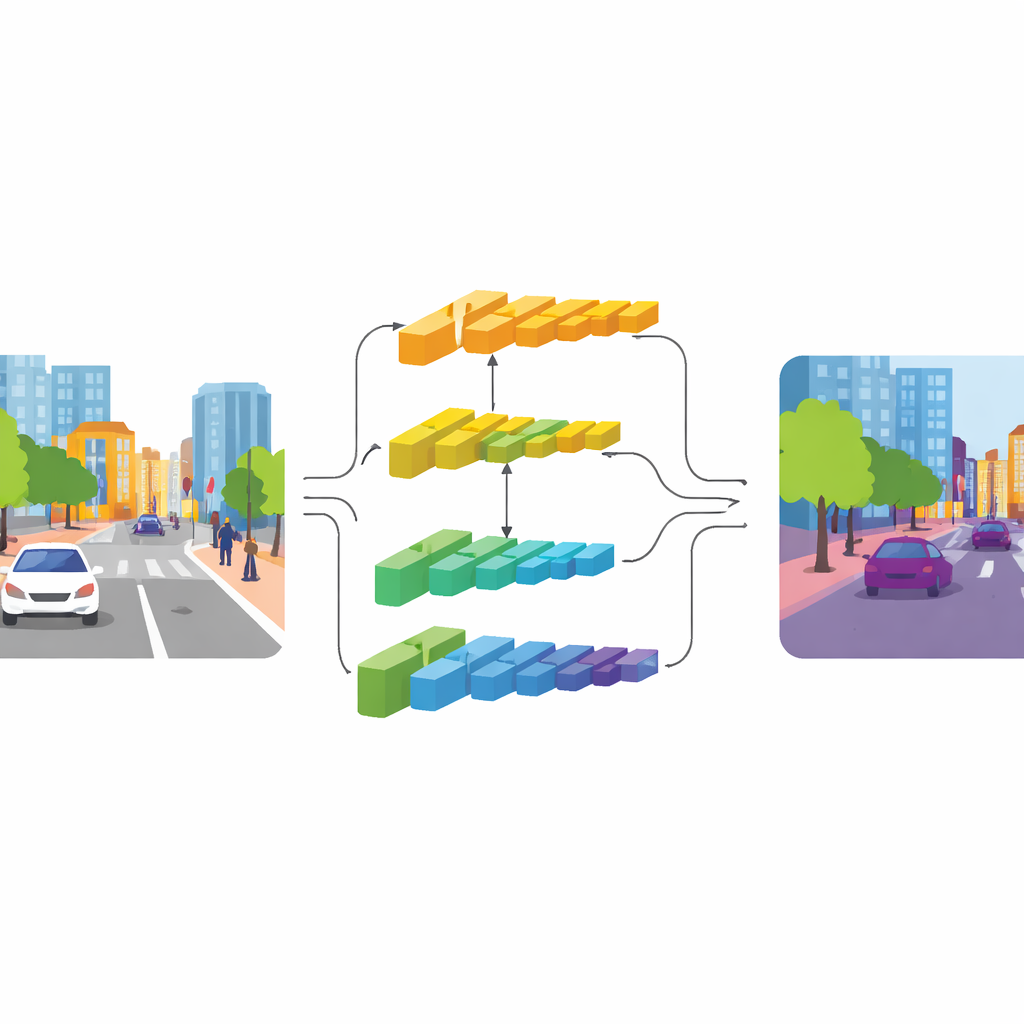
Guiando detalhes com significado
Dois componentes-chave reforçam essa interação. No ramo de contexto, um Módulo de Refinamento Semântico aprende a realçar as regiões e canais mais informativos em seus mapas de características. Ele faz isso combinando pistas locais (quais partes da cena estão ativas próximas umas das outras) com pistas globais (o que a rede vê em toda a imagem), de modo que a representação carregue tanto detalhe de vizinhança quanto significado em nível de cena. No ramo de detalhes, um Módulo de Detalhe Guiado por Contexto usa essa informação semântica para direcionar a atenção a bordas e estruturas finas que importam, como o contorno de um ônibus ou a estrutura de uma bicicleta. Ele se baseia em um tipo especial de convolução mais sensível a variações entre pixels vizinhos, o que enfatiza naturalmente contornos e pequenos objetos sem adicionar muitos parâmetros extras.
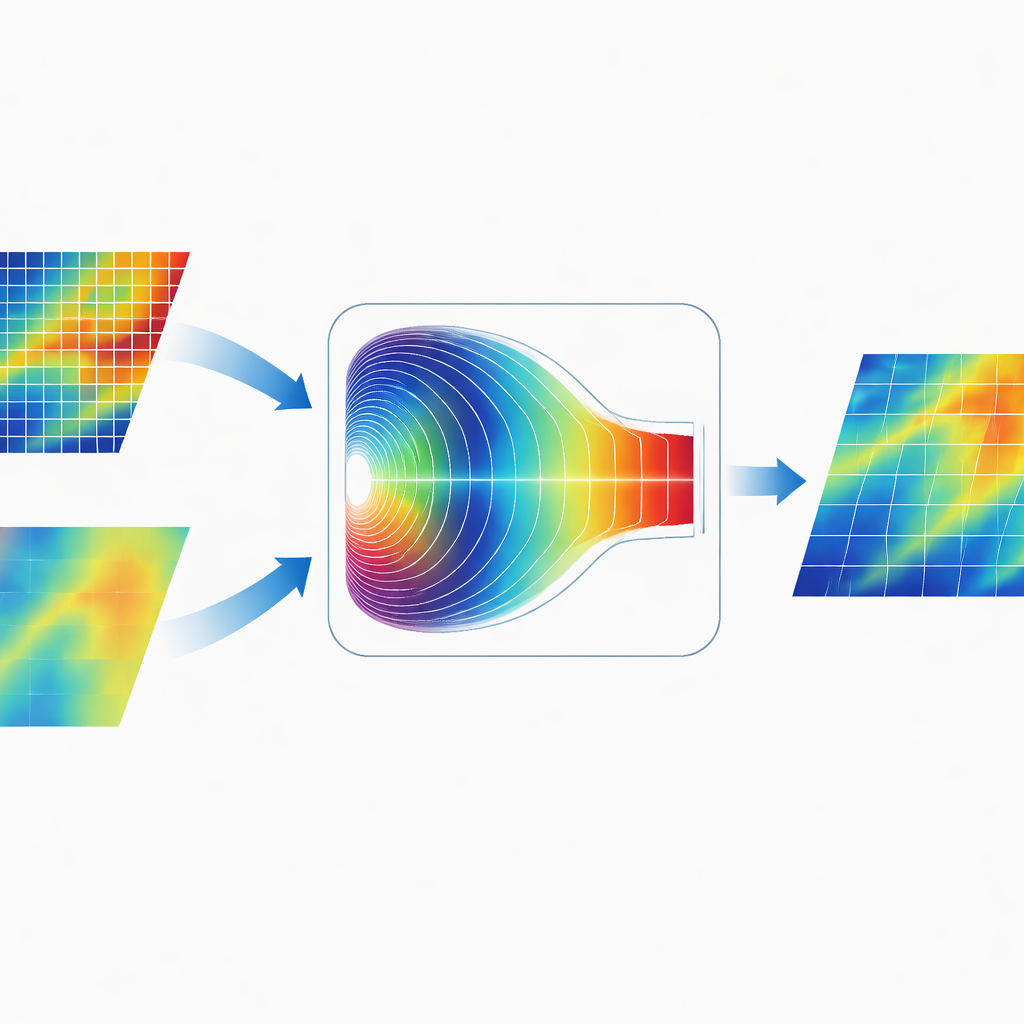
Mesclando informações no domínio da frequência
Uma característica distintiva do CGDFNet é como ele funde os dois ramos. Em vez de simplesmente somar seus mapas no espaço da imagem, os autores projetaram um Módulo de Fusão Adaptativa no Domínio de Fourier. Esse módulo transforma temporariamente as características combinadas para o domínio da frequência, onde padrões são representados em termos de variações lentas e amplas e mudanças rápidas e nítidas. Um mecanismo de gating adaptativo então aprende quais componentes de frequência enfatizar a partir do ramo de detalhes e quais enfatizar a partir do ramo de contexto. Após esse ponderamento, as características são transformadas de volta, produzindo uma representação que une bordas nítidas com uma estrutura global coerente de forma mais eficaz do que a fusão tradicional apenas no domínio espacial.
Resultados em ruas reais
A equipe testou o CGDFNet em dois conjuntos de referência amplamente usados para cenas de direção urbana: Cityscapes, coletado em cidades europeias, e CamVid, capturado a partir da perspectiva de um motorista no Reino Unido. O CGDFNet processou imagens grandes em velocidades de tempo real — cerca de 88 quadros por segundo no Cityscapes e aproximadamente 129 quadros por segundo no CamVid — enquanto alcançava acurácia de segmentação que rivaliza ou supera muitos sistemas de ponta. Desempenhou-se especialmente bem em categorias que costumam ser difíceis de segmentar, como cercas, sinais de trânsito, ônibus e bicicletas, onde preservar limites precisos e estruturas pequenas é crucial.
O que isso significa para a tecnologia do dia a dia
Em termos práticos, o CGDFNet demonstra que é possível construir sistemas de visão que sejam rápidos o suficiente para uso em tempo real e suficientemente cuidadosos para respeitar detalhes pequenos e críticos para a segurança em cenas urbanas complexas. Ao combinar um ramo focado em detalhes, um ramo focado em contexto e uma etapa de fusão inteligente no domínio da frequência, a rede mantém uma visão equilibrada da rua: sabe onde tudo está e onde cada objeto começa e termina. Embora desafios permaneçam — como multidões densas ou mau tempo —, a abordagem oferece um roteiro promissor para visão embarcada futura, desde carros autônomos a câmeras de tráfego inteligentes e robôs assistivos.
Citação: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Palavras-chave: segmentação semântica em tempo real, visão para direção autônoma, rede neural de dois ramos, fusão de características baseada em Fourier, entendimento de cenas urbanas