Clear Sky Science · pt
Uma rede neural convolucional de ponta a ponta para transmissão segura de imagens via criptografia conjunta e esteganografia
Por que esconder imagens dentro de outras imagens importa
Todos os dias, hospitais, bancos e pessoas comuns enviam um grande número de fotos pela internet — de exames médicos a documentos de identidade e fotos de família. Manter essas imagens privadas geralmente significa embaralhá‑las com criptografia, o que as faz parecer ruído aleatório, ou escondê‑las dentro de outras imagens, um truque chamado esteganografia. Cada abordagem tem uma fraqueza: imagens criptografadas chamam atenção, e imagens ocultas podem ser expostas por análises inteligentes. Este artigo apresenta um novo sistema de aprendizado profundo que combina ambas as ideias, visando enviar imagens secretas de maneira que pareçam naturais ao olho humano e, ao mesmo tempo, sejam difíceis de serem quebradas por atacantes.
O problema com os truques de proteção atuais
Ferramentas tradicionais de criptografia, como AES e DES, são matematicamente fortes, mas transformam uma foto em um bloco de ruído visual que claramente sinaliza “algo importante está escondido aqui.” A esteganografia clássica faz o oposto: ela aloja informação nos detalhes finos de uma imagem com aparência normal, porém frequentemente sem uma proteção criptográfica robusta. Se um atacante detectar o artifício, a mensagem oculta pode ser facilmente extraída. Métodos recentes baseados em aprendizado profundo melhoraram tanto a criptografia quanto a ocultação, mas a maioria os trata como dois passos separados. Essa separação desperdiça esforço computacional e pode permitir que erros de uma etapa prejudiquem a outra. Os autores argumentam que o que falta é um único sistema que aprenda, de ponta a ponta, a disfarçar e proteger imagens ao mesmo tempo.
Um único cérebro que embaralha e oculta
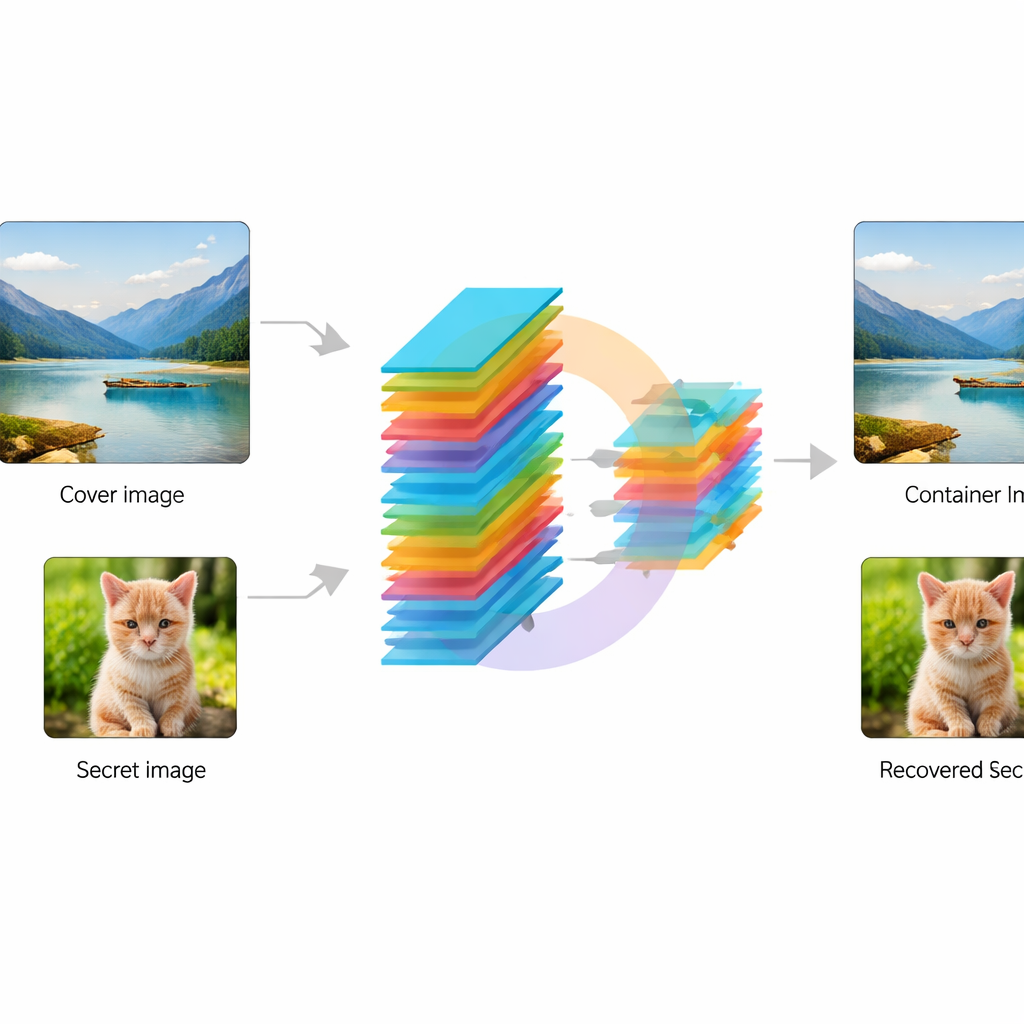
Os pesquisadores projetam uma rede neural convolucional de ponta a ponta — essencialmente um pipeline de processamento de imagem treinável — que recebe duas imagens: uma foto “cobertura” normal e uma foto “secreta” a ser protegida. Primeiro, um módulo especial chamado KeyMixer transforma a imagem secreta usando chaves numéricas treináveis. Ao contrário de cifras fixas projetadas manualmente, esse mixer aprende alterações sensíveis ao conteúdo que dependem de texturas e formas na imagem, introduzindo distorções sutis e não óbvias. Em seguida, uma rede Encoder mistura suavemente esse segredo transformado na imagem de cobertura, criando uma imagem “contêiner” que deve continuar com aparência natural. No lado do receptor, uma rede Decoder correspondente recebe apenas a imagem contêiner e reconstrói o segredo oculto, sem precisar de chaves extras ou informações adicionais durante a recuperação.
Treinar a rede para equilibrar segredo e aparência
Treinar esse sistema significa exigir que ele atinja dois objetivos ao mesmo tempo: manter a imagem contêiner visualmente próxima da cobertura original e recuperar a imagem secreta com a maior fidelidade possível. Os autores fazem isso com uma estratégia de perda dupla que penaliza tanto mudanças visíveis na cobertura quanto erros na reconstrução do segredo. Eles usam um conjunto de referência popular de fotos naturais, o conjunto de dados STL‑10, e aplicam truques padrão de aumento de dados, como flips e pequenas rotações, para que a rede veja cenas variadas. Durante o treinamento, o modelo melhora gradualmente até que ambos os objetivos se estabilizem, mostrando que ele consegue encontrar um ponto de equilíbrio viável entre invisibilidade e recuperação fiel.
Quão bem as imagens ocultas sobrevivem
Para avaliar a qualidade, a equipe mede quão semelhantes são as imagens contêiner às coberturas e quão próximas as secretas reconstruídas estão dos originais, usando métricas padrão de qualidade de imagem. Nas imagens de teste, o método alcança alta similaridade estrutural tanto para a cobertura quanto para o segredo, com valores acima de 0,90, o que significa que formas e detalhes são em grande parte preservados. As imagens secretas, em particular, atingem similaridades muito altas, indicando recuperação perceptual quase perfeita. Quando comparado com vários sistemas modernos de esteganografia por aprendizado profundo e pipelines híbridos, o novo modelo de ponta a ponta entrega a melhor reconstrução da imagem secreta, mesmo que alguns concorrentes preservem ligeiramente melhor a cobertura. Testes estatísticos de distribuições de pixels, aleatoriedade e sensibilidade a alterações sugerem que os contêineres não revelam pistas óbvias de que algo está escondido.
O que isso pode significar para a privacidade do dia a dia
Em termos simples, este trabalho mostra que um único modelo de aprendizado profundo pode aprender a disfarçar e proteger imagens de modo que uma imagem oculta possa ser recuperada com alta clareza, enquanto a imagem compartilhada continua parecendo comum. Em vez de juntar criptografia e esteganografia em uma cadeia desajeitada, o sistema aprende um compromisso suave entre sutileza visual e segurança. Embora atualmente exija hardware potente e mais testes contra ataques avançados, a abordagem aponta para ferramentas futuras que poderiam proteger discretamente exames médicos, fotos pessoais ou outras imagens sensíveis em comunicações online rotineiras, sem anunciar que existe algo secreto ali.
Citação: Iqbal, A., Sattar, H., Shafi, U.F. et al. An end-to-end convolutional neural network for secure image transmission via joint encryption and steganography. Sci Rep 16, 8228 (2026). https://doi.org/10.1038/s41598-026-39351-4
Palavras-chave: segurança de imagem, esteganografia, aprendizado profundo, criptografia neural, proteção de privacidade