Clear Sky Science · pt
Previsão mascarada por topologia de movimento em esqueletos e aprendizado contrastivo para reconhecimento auto-supervisionado de ações humanas
Ensinando Computadores a Ler a Linguagem Corporal
De campainhas por vídeo a ferramentas inteligentes de reabilitação, muitos sistemas modernos precisam entender o que as pessoas estão fazendo apenas observando como se movem. Mas treinar computadores para reconhecer ações humanas geralmente exige conjuntos de dados enormes e cuidadosamente rotulados, em que cada aceno, chute ou aperto de mão é anotado manualmente. Este estudo apresenta uma forma de as máquinas aprenderem a partir de dados brutos de movimento, usando apenas o esqueleto em movimento do corpo — sem rótulos, rostos nem vídeo em cores — tornando o reconhecimento de ações mais preciso, mais privado e muito menos dependente de anotações humanas dispendiosas.
Por que Esqueletos são Suficientes
Em vez de analisar quadros de vídeo completos, o método trabalha com dados de esqueleto 3D: as coordenadas de articulações-chave como ombros, cotovelos, quadris e joelhos ao longo do tempo. Essa visão enxuta do corpo traz várias vantagens. Em grande parte evita problemas de privacidade porque rostos e roupas são eliminados, e é suficientemente compacta para ser processada com eficiência, mesmo em gravações longas. Esqueletos também são robustos a cenários com fundo poluído e variações de iluminação que confundem sistemas baseados em vídeo. No entanto, a maioria das abordagens baseadas em esqueletos ainda depende fortemente de exemplos rotulados e tem dificuldade em capturar plenamente como as articulações se movimentam de forma coordenada em ações complexas.
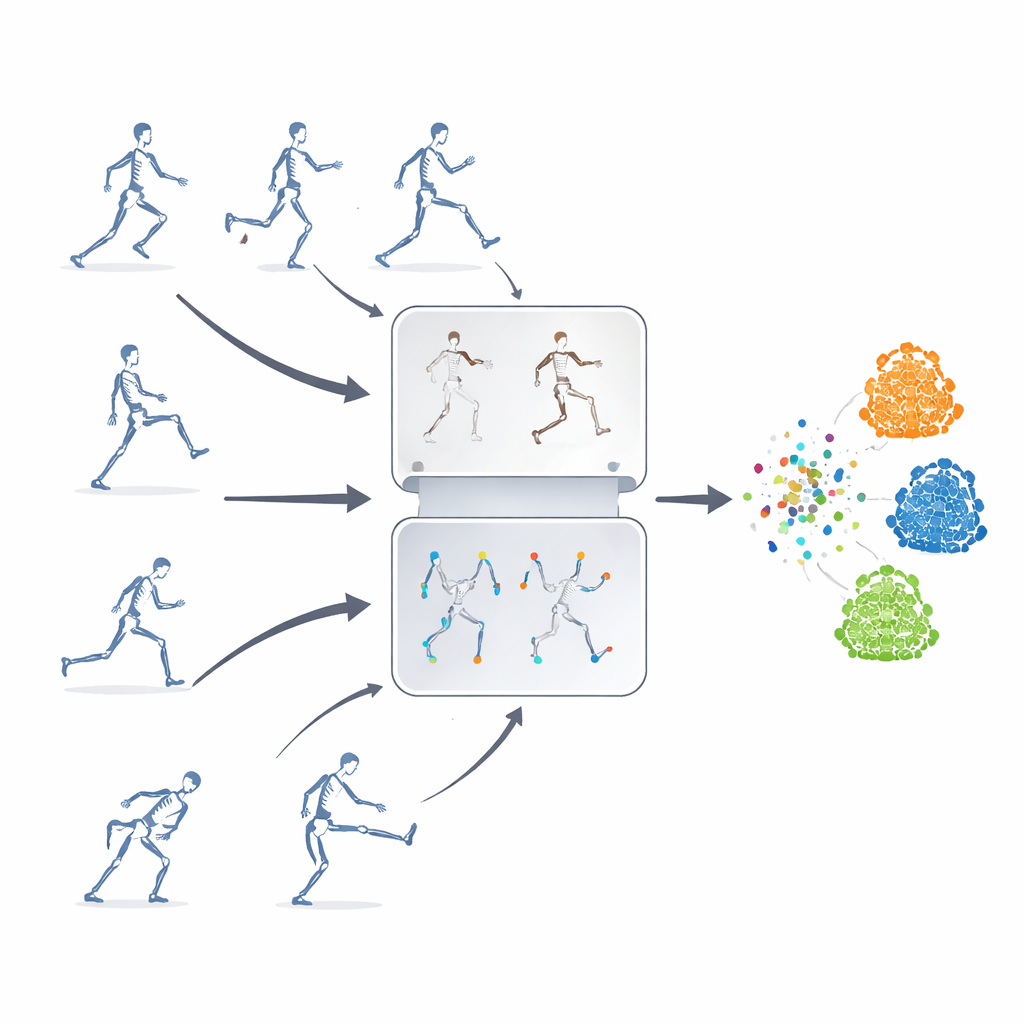
Aprendendo Sem Rótulos
Os autores propõem uma estrutura de aprendizado auto-supervisionado, isto é, o sistema se ensina a partir de sequências de esqueleto não rotuladas. A ideia-chave é combinar duas estratégias poderosas que normalmente são usadas separadamente. Uma é a “previsão mascarada”, em que partes dos dados do esqueleto são deliberadamente ocultadas para que o modelo precise adivinhar o movimento faltante a partir do contexto restante. A outra é o “aprendizado contrastivo”, que mostra ao modelo várias versões alteradas da mesma ação e o treina a reconhecer que essas variações ainda representam um mesmo movimento subjacente. Ao mesclar essas abordagens, o sistema aprende tanto os detalhes finos do movimento das articulações quanto o significado em larga escala de uma ação.
Ocultando as Articulações Certas
Mascarar articulações aleatoriamente não é suficiente — o modelo pode ignorar relações importantes entre partes do corpo ou fixar-se no movimento mais óbvio. Para evitar isso, os pesquisadores introduzem uma estratégia de mascaramento baseada em topologia e movimento. Eles agrupam articulações em regiões corporais significativas, como braços, pernas e tronco, e então medem o quanto cada região se movimenta ao longo do tempo. As decisões de mascaramento são guiadas tanto pela estrutura do corpo quanto pela intensidade do movimento de cada região, de modo que às vezes partes altamente ativas são ocultadas e o modelo é forçado a inferi-las a partir do restante do corpo. Esse ocultamento direcionado ajuda o sistema a aprender como as articulações cooperam durante as ações, em vez de apenas memorizar alguns movimentos chamativos.
Esticando Ações de Muitas Maneiras
Para treinar a parte contrastiva do sistema, a mesma sequência original de esqueleto é transformada em muitas “visões” diferentes. Algumas mudanças são suaves, como recortar a janela temporal ou deformar levemente a trajetória, enquanto outras são mais extremas, incluindo espelhamentos, rotações e ruído mais intenso. Esses múltiplos níveis de aumento expõem o modelo a uma rica variedade de padrões de movimento, incentivando-o a concentrar-se na estrutura central de uma ação em vez de detalhes superficiais. Ao mesmo tempo, um módulo de supressão de características guiado por trajetória acompanha quais recursos de movimento o modelo mais utiliza e os reprime intencionalmente durante o treinamento. Ao remover temporariamente suas pistas favoritas, o sistema é pressionado a descobrir pistas alternativas e a aprender representações mais gerais e transferíveis.
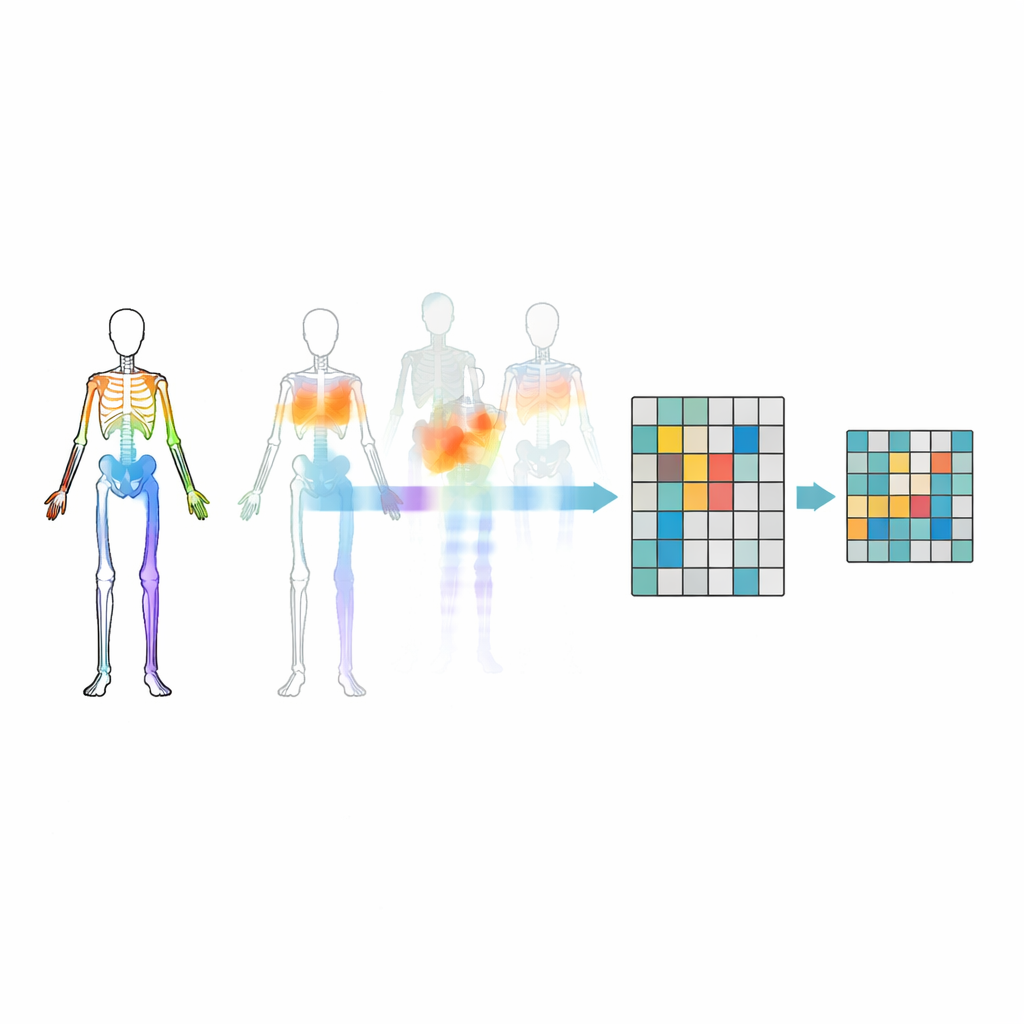
Quão Bem Isso Funciona?
A estrutura é testada em três grandes benchmarks públicos de ações humanas 3D, cobrindo comportamentos do cotidiano, movimentos relacionados à medicina e interações entre pessoas. Mesmo usando apenas dados de articulações esqueléticas e uma rede neural recorrente relativamente leve, o método iguala ou supera muitos sistemas de ponta que dependem de entradas ou arquiteturas mais complexas. É particularmente forte quando as anotações são escassas ou quando algumas partes do corpo estão ocluídas, condições que costumam surgir em ambientes do mundo real. Embora sua capacidade de transferir conhecimento entre conjuntos de dados muito diferentes ainda possa ser aprimorada, a abordagem reduz significativamente a lacuna entre treinamento rotulado e não rotulado para reconhecimento de ações.
O Que Isso Significa para Sistemas do Mundo Real
Para um público não especialista, a conclusão é que este trabalho mostra como os computadores podem ficar muito melhores em ler a linguagem corporal humana sem que cada movimento precise ser explicitamente rotulado. Ao ocultar e distorcer inteligentemente os dados do esqueleto durante o treinamento, o modelo aprende padrões robustos de movimento que resistem a iluminação ruim, poluição visual ou articulações faltantes, e faz isso com muito menos rótulos fornecidos por humanos. Isso abre a porta para sistemas de reconhecimento de ações mais privados, escaláveis e adaptáveis, com aplicações que vão desde monitoramento doméstico e treinamento esportivo até reabilitação médica e interação humano–robô.
Citação: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Palavras-chave: reconhecimento de ações humanas, dados de esqueleto 3D, aprendizado auto-supervisionado, aprendizado contrastivo, análise de movimento