Clear Sky Science · pt
Uma estrutura Siamese CNN-RNN com agregação em múltiplos níveis para re-identificação de pessoas em vídeo
Por que seguir pessoas entre câmeras importa
Cidades modernas estão cobertas por câmeras, mas essas câmeras raramente “conversam” entre si. Quando uma pessoa caminha de uma esquina até uma estação, diferentes câmeras a veem sob novos ângulos, com iluminação distinta e frequentemente através de multidões. Reconhecer automaticamente que se trata da mesma pessoa em clipes de vídeo diferentes — chamado de re-identificação de pessoas baseada em vídeo — pode ajudar investigadores a traçar deslocamentos após um incidente, apoiar buscas por pessoas desaparecidas ou alimentar análises em espaços públicos movimentados. Mas fazer isso de forma precisa e eficiente, especialmente em hardware modesto, é um grande desafio técnico.
Um cérebro mais simples para corresponder pessoas em movimento
Este estudo apresenta um sistema de inteligência artificial compacto projetado para dizer se dois clipes curtos de vídeo mostram a mesma pessoa. Em vez de seguir a tendência atual de redes muito profundas ou baseadas em transformers, os autores constroem sobre um desenho mais enxuto que combina dois ingredientes clássicos: uma rede convolucional que analisa cada quadro do vídeo e uma unidade recorrente com porta (GRU) que acompanha como a aparência muda ao longo do tempo. Esses dois ramos são organizados em uma disposição Siamese — essencialmente, cópias gêmeas da mesma rede que compartilham todos os ajustes internos. Cada gêmea processa uma sequência de vídeo, e o sistema aprende a produzir assinaturas internas semelhantes para clipes da mesma pessoa e assinaturas claramente distintas para pessoas diferentes.
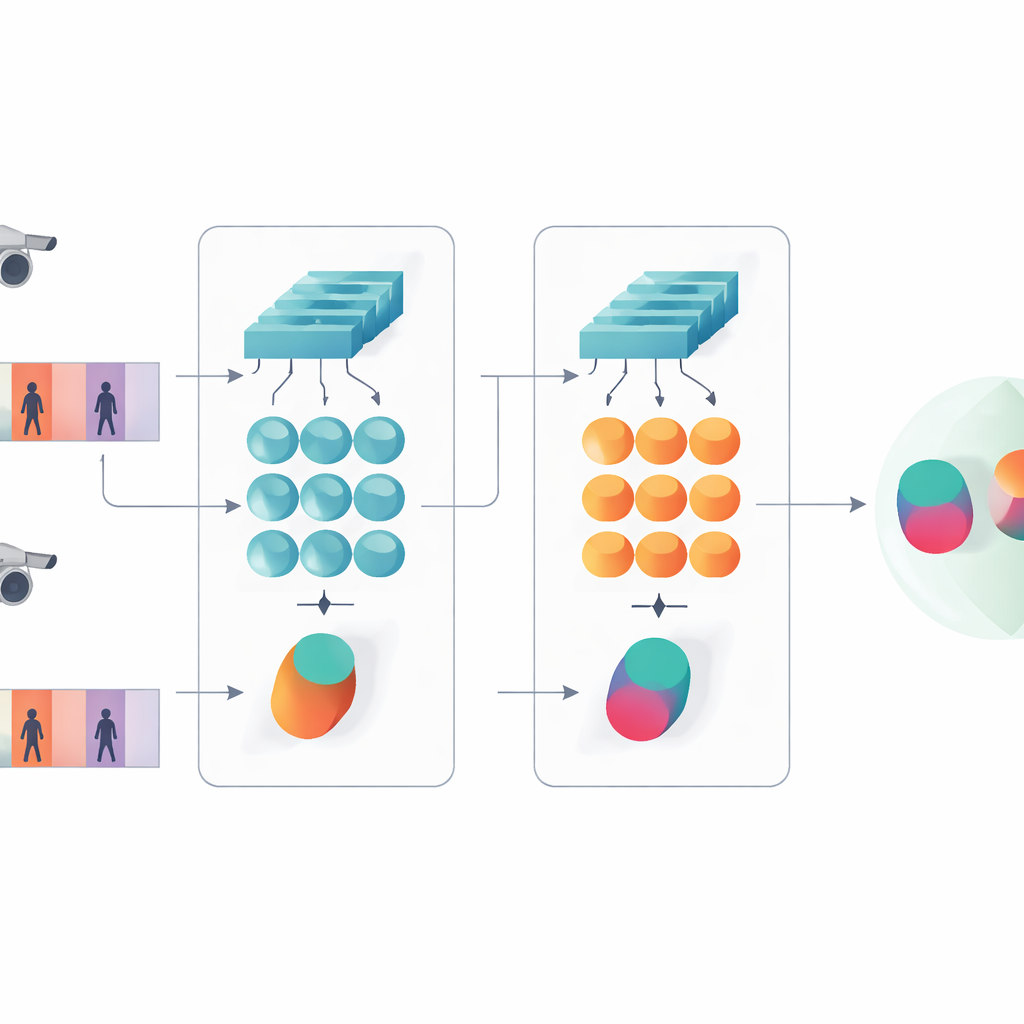
Ver tanto detalhes quanto padrões ao longo do tempo
Uma ideia-chave do trabalho é que o reconhecimento não deve se basear apenas nas características mais profundas e abstratas de uma rede. Camadas anteriores ainda contêm detalhes visuais nítidos, como o tecido de um casaco, listras na calça ou o contorno de uma mochila — indícios que frequentemente sobrevivem a mudanças no ângulo da câmera. O modelo proposto mantém, portanto, dois níveis de descrição. Um ramo faz pooling dos recursos das camadas iniciais sobre todos os quadros para resumir texturas finas e padrões locais. O outro ramo alimenta características mais profundas na GRU, que segue a sequência quadro a quadro e então faz a média de seus estados internos ao longo do tempo. Essa etapa de média evita enfatizar em excesso os últimos quadros e captura, em vez disso, uma visão de consenso de como a pessoa parece e se movimenta durante todo o clipe.
Treinando as redes gêmeas para concordar e classificar
Para ensinar ao sistema o que importa, os autores combinam dois objetivos de treinamento. Primeiro, um objetivo de verificação incentiva os ramos gêmeos a produzir assinaturas próximas para vídeos da mesma pessoa e assinaturas distantes para pessoas diferentes. Segundo, um objetivo de classificação pede que a rede atribua cada clipe de treinamento a uma identidade específica. Ao otimizar ambos simultaneamente, e ao fazê-lo tanto em níveis baixos quanto altos de características, o modelo aprende descrições internas que não só são distintas entre pessoas, mas também robustas a ruído, oclusões e quadros de qualidade ocasionalmente ruim. O projeto permanece raso em termos de camadas e parâmetros, o que ajuda a evitar overfitting em conjuntos de dados de vídeo relativamente pequenos.
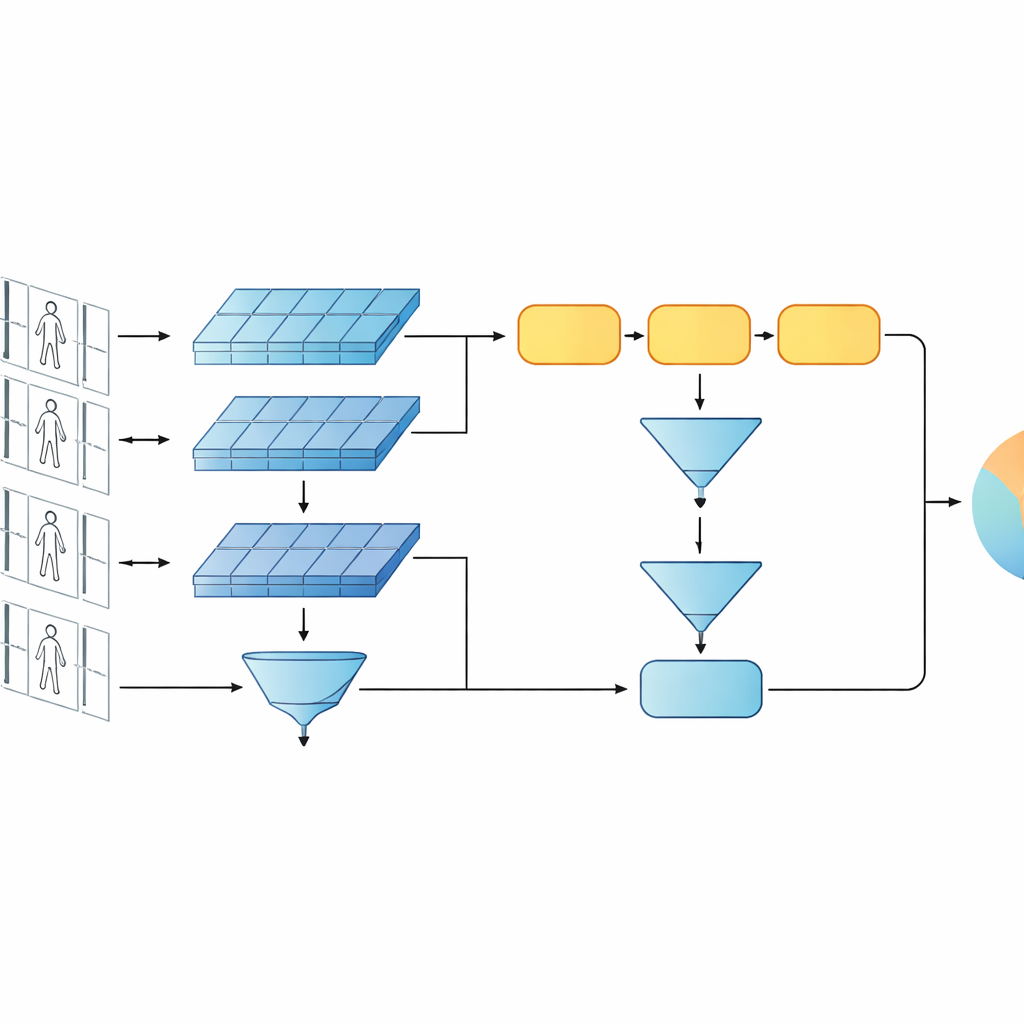
Testando em vídeos no estilo de vigilância real
A estrutura é avaliada em dois benchmarks de vídeo amplamente usados, PRID-2011 e iLIDS-VID, que contêm sequências curtas de caminhada de centenas de indivíduos capturados por pares de câmeras disjuntas. O estudo investiga cuidadosamente diferentes escolhas de projeto: trocar a GRU por outras unidades recorrentes, alterar quantas camadas recorrentes são usadas, modificar como as características são agrupadas ao longo do tempo e ativar ou desativar os ramos de nível baixo ou alto. Nesses testes, uma GRU de camada única com pooling por média e a configuração completa de múltiplos níveis entrega consistentemente a melhor acurácia. O modelo iguala ou supera muitos sistemas recorrentes e Siamese mais complexos, e compete com alguns projetos baseados em atenção, usando muito menos parâmetros e custo computacional.
Eficiência para implantações no mundo real
Além da acurácia, o trabalho enfatiza a praticidade. A rede inteira possui apenas cerca de um a dois milhões de parâmetros treináveis — ordens de grandeza a menos que backbones residuais profundos ou baseados em transformers populares — e requer uma fração do custo computacional por quadro. Isso a torna mais adequada para implantação em dispositivos com memória e poder de processamento limitados, como servidores de borda próximos às câmeras. Experimentos também mostram que sequências de galeria mais longas, onde o sistema vê mais quadros de cada pessoa armazenada, melhoram substancialmente o reconhecimento, embora com um aumento linear no custo de processamento. Os autores argumentam que arquiteturas compactas e cuidadosamente projetadas podem oferecer re-identificação confiável de pessoas sem o alto custo dos maiores modelos atuais.
O que isso significa para sistemas de vigilância do dia a dia
Em termos simples, este artigo demonstra que o projeto inteligente pode superar o tamanho bruto: ao combinar análise de imagem rasa, modelagem de sequência leve e uma visão em dois níveis da similaridade visual, é possível rastrear quem é quem entre câmeras com alta confiabilidade mantendo o modelo pequeno e rápido. Para sistemas futuros que precisam rodar em muitas câmeras, muitas vezes com restrições rígidas de hardware e energia, esse tipo de abordagem eficiente e em múltiplos níveis pode ajudar a levar análises de vídeo mais capazes e responsáveis ao uso no mundo real.
Citação: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Palavras-chave: re-identificação de pessoas, vigilância por vídeo, redes neurais Siamese, modelagem temporal, aprendizado profundo eficiente