Clear Sky Science · pt
Uma estrutura robusta de geração de texto para SQL com estratégias dinâmicas baseadas em LLMs
Transformando Perguntas Cotidianas em Respostas de Banco de Dados
Organizações modernas estão inundadas de dados, mas a maioria das pessoas não fala a linguagem técnica necessária para consultá-los. Este artigo apresenta o TriSQL, um sistema que permite aos usuários fazer perguntas em linguagem natural e automaticamente traduzi-las em comandos de banco de dados precisos. Ao gerenciar cuidadosamente como modelos de linguagem de grande porte lidam com a complexidade, a estrutura busca tornar o acesso aos dados mais preciso e confiável, mesmo para as questões mais difíceis.
Por Que Falar com Bancos de Dados é Tão Difícil
Quando alguém digita uma pergunta como “Quais clientes compraram mais de cinco produtos no mês passado?”, um computador precisa traduzir isso em SQL, a linguagem especializada usada pela maioria dos bancos de dados. Essa tarefa, chamada text-to-SQL, parece simples, mas é surpreendentemente difícil. O sistema precisa entender o que o usuário quer, localizar as tabelas e colunas corretas dentro de um esquema que pode ser enorme e desorganizado, e então construir uma consulta que seja estruturalmente válida e fiel à intenção original. Sistemas anteriores, inclusive os alimentados por grandes modelos de linguagem, frequentemente falham quando as perguntas envolvem muitas tabelas, lógica aninhada ou condições sutis. Eles podem gerar consultas que parecem corretas, mas que não executam ou retornam resultados errados quando executadas.
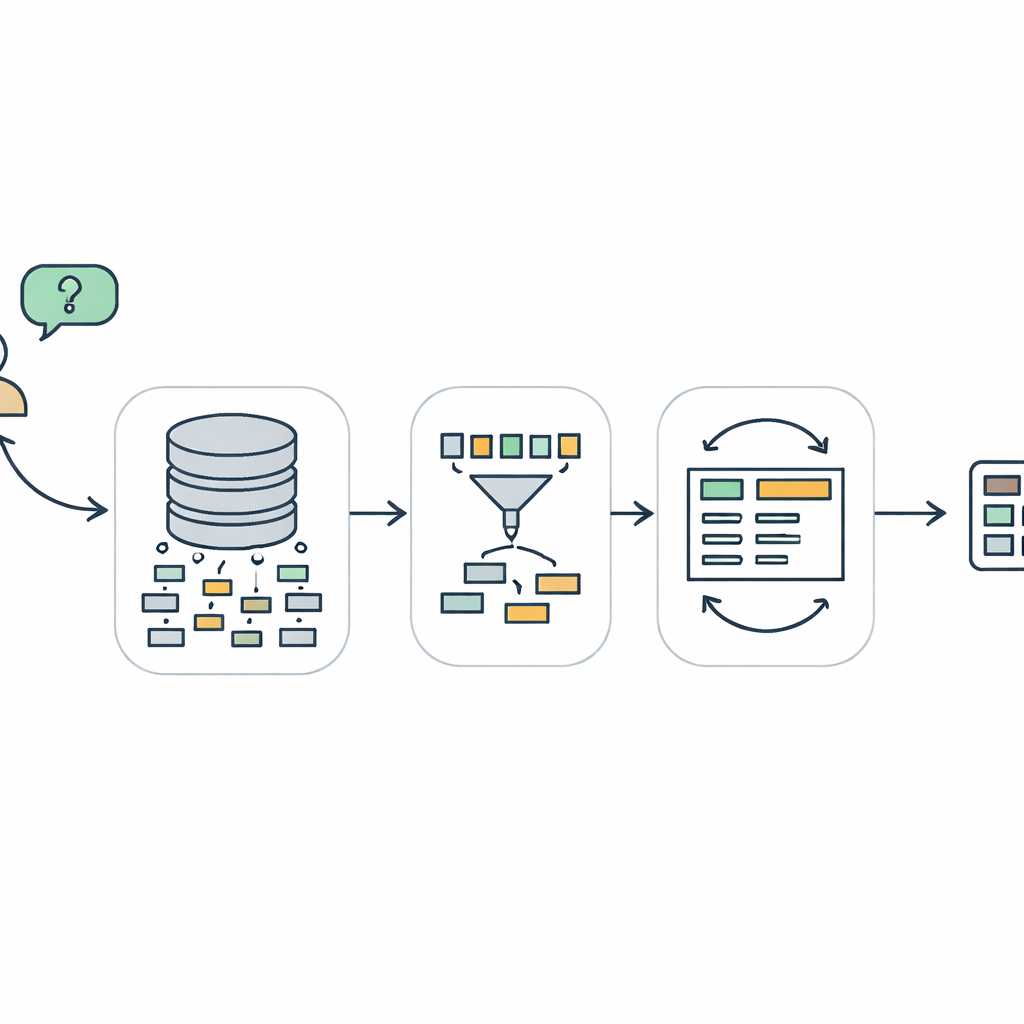
Um Caminho em Três Etapas da Pergunta à Consulta
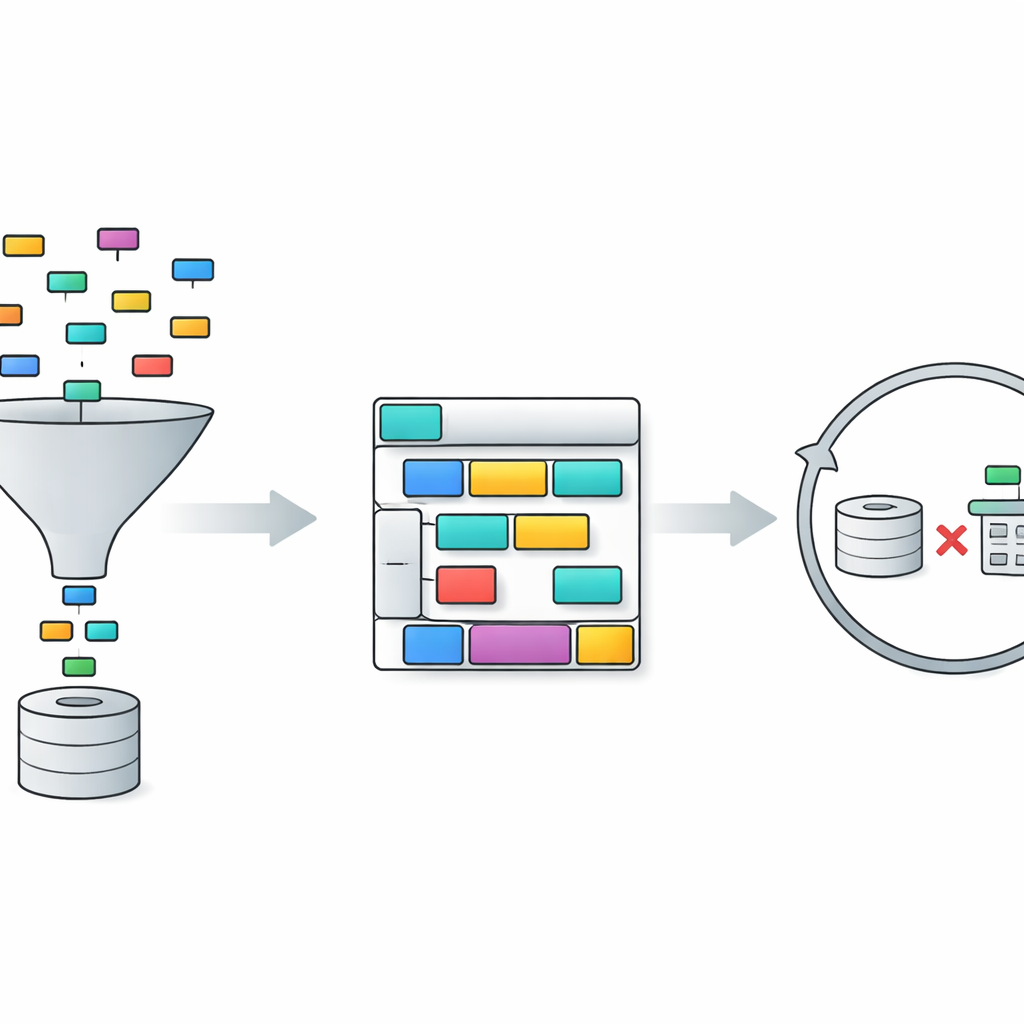
O TriSQL enfrenta esses problemas com um pipeline em três estágios. Primeiro, um seletor guiado pela pergunta analisa as palavras do usuário e toda a estrutura do banco de dados e decide quais tabelas e colunas são realmente relevantes. Em vez de expor cegamente o modelo de linguagem ao esquema completo, ele reduz a visão apenas às partes importantes. Em seguida, um gerador consciente da estrutura planeja a forma da consulta SQL antes de preencher os detalhes. Primeiro ele esboça um esqueleto de alto nível — quais cláusulas são necessárias e como elas se encaixam — e então insere tabelas específicas, junções e condições. Essa abordagem de “estrutura primeiro, conteúdo depois” ajuda a preservar a gramática rígida do SQL, especialmente para consultas longas e complexas. Por fim, um refinador ciente da complexidade verifica e aprimora a consulta inicial, usando estratégias diferentes dependendo de quão difícil a pergunta parece ser.
Adaptando o Esforço à Dificuldade da Pergunta
A etapa de refinamento é onde o TriSQL faz uso particularmente inovador dos grandes modelos de linguagem. O sistema pontua quão complexas são cada pergunta e o rascunho de consulta, considerando fatores como quantas tabelas são unidas, quão profundo é qualquer aninhamento e que tipos de restrições são usadas. Para casos simples, aplica apenas correções leves, como ajustar pequenos deslizes de sintaxe. Para casos médios, reorganiza cláusulas e garante que a consulta esteja alinhada com o esquema selecionado. Para as perguntas mais exigentes, invoca o modelo de linguagem para raciocínio mais profundo, às vezes decompondo o problema em subtarefas e executando consultas alternativas. De forma crucial, o TriSQL então executa tanto a consulta original quanto a refinada contra o banco de dados e usa seu comportamento — se elas rodam, quanto tempo levam e o que retornam — para decidir qual versão manter ou se deve tentar outra rodada de refinamento.
Colocando o Sistema à Prova
Para avaliar o desempenho do TriSQL, os autores o testam em um benchmark amplamente usado chamado Spider, junto com várias variantes mais difíceis que introduzem conhecimento de domínio, padrões de frase incomuns e estruturas de consulta mais realistas. Eles medem duas coisas: correspondência exata, que verifica se a string SQL gerada é idêntica a uma referência escrita por humanos, e acurácia de execução, que verifica se ela produz realmente a resposta correta quando executada. Nesses conjuntos de dados, o TriSQL atinge a maior acurácia de execução relatada até agora, mantendo a correspondência exata competitiva com os melhores sistemas anteriores. Também é mais robusto: à medida que as perguntas vão de fáceis a extremamente difíceis, o desempenho do TriSQL cai muito mais suavemente do que o dos métodos concorrentes. Experimentos adicionais em um conjunto de dados real de gerenciamento de redes elétricas mostram que a mesma estrutura pode lidar não apenas com recuperação de dados, mas também com comandos de inserção, atualização, exclusão e criação de tabelas. Adaptações iniciais para bancos de dados em grafo (Cypher) e pipelines do MongoDB sugerem que o design em três estágios pode se estender além do SQL clássico.
O Que Isso Significa para o Uso Cotidiano de Dados
Em termos simples, este trabalho nos aproxima de um mundo onde as pessoas podem conversar com bancos de dados complexos tão facilmente quanto hoje conversam com mecanismos de busca. Ao escolher cuidadosamente quais partes do banco considerar, ao planejar a estrutura de uma consulta antes de preencher os detalhes e ao ajustar o uso de grandes modelos de linguagem conforme a dificuldade de cada pergunta, o TriSQL produz consultas que têm mais probabilidade de executar corretamente e retornar os resultados pretendidos. Embora desafios permaneçam — como lidar com perguntas ambíguas e bancos de dados inéditos — o estudo mostra que um desenho em estágios e bem pensado pode tornar interfaces em linguagem natural para dados mais poderosas e previsíveis para usuários cotidianos.
Citação: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Palavras-chave: text-to-SQL, interfaces em linguagem natural, consulta de bancos de dados, modelos de linguagem de grande porte, robustez de consultas