Clear Sky Science · pt
Uma abordagem para lidar com conjuntos de dados desbalanceados usando deslocamento de fronteira
Por que casos raros importam nos dados do dia a dia
De fraudes bancárias e diagnósticos médicos à previsão de churn de clientes, muitas das decisões que pedimos aos computadores para tomar dependem de identificar eventos raros, porém cruciais. Na maioria dos conjuntos de dados reais, esses casos importantes são amplamente superados por casos comuns. Um modelo que vê majoritariamente o “negócio como de costume” pode ficar cego para as situações que mais nos interessam. Este artigo apresenta uma nova forma de reequilibrar esses dados enviesados para que os algoritmos de aprendizado deem a devida atenção aos casos raros e de grande impacto.
A armadilha oculta dos dados desequilibrados
Quando um tipo de exemplo supera largamente outro, métodos padrão de aprendizado de máquina tendem a focar na maioria e negligenciar silenciosamente a minoria. Um sistema de previsão de churn, por exemplo, pode rotular quase todos como clientes fiéis e ainda ostentar alta acurácia, simplesmente porque os churners reais são poucos. Problemas semelhantes surgem em detecção de acidentes, monitoramento de fraudes e triagem médica, onde casos positivos são raros, mas caros de perder. Formas tradicionais de corrigir isso se dividem em duas correntes: ajustar o algoritmo de aprendizado para “se importar” mais com a minoria, ou remodelar os dados removendo alguns casos da maioria (undersampling) ou criando casos extras da minoria (oversampling). Ferramentas populares de oversampling como o SMOTE geram exemplos sintéticos da minoria, mas podem, inadvertidamente, poluir a região delicada da fronteira onde as duas classes se encontram.
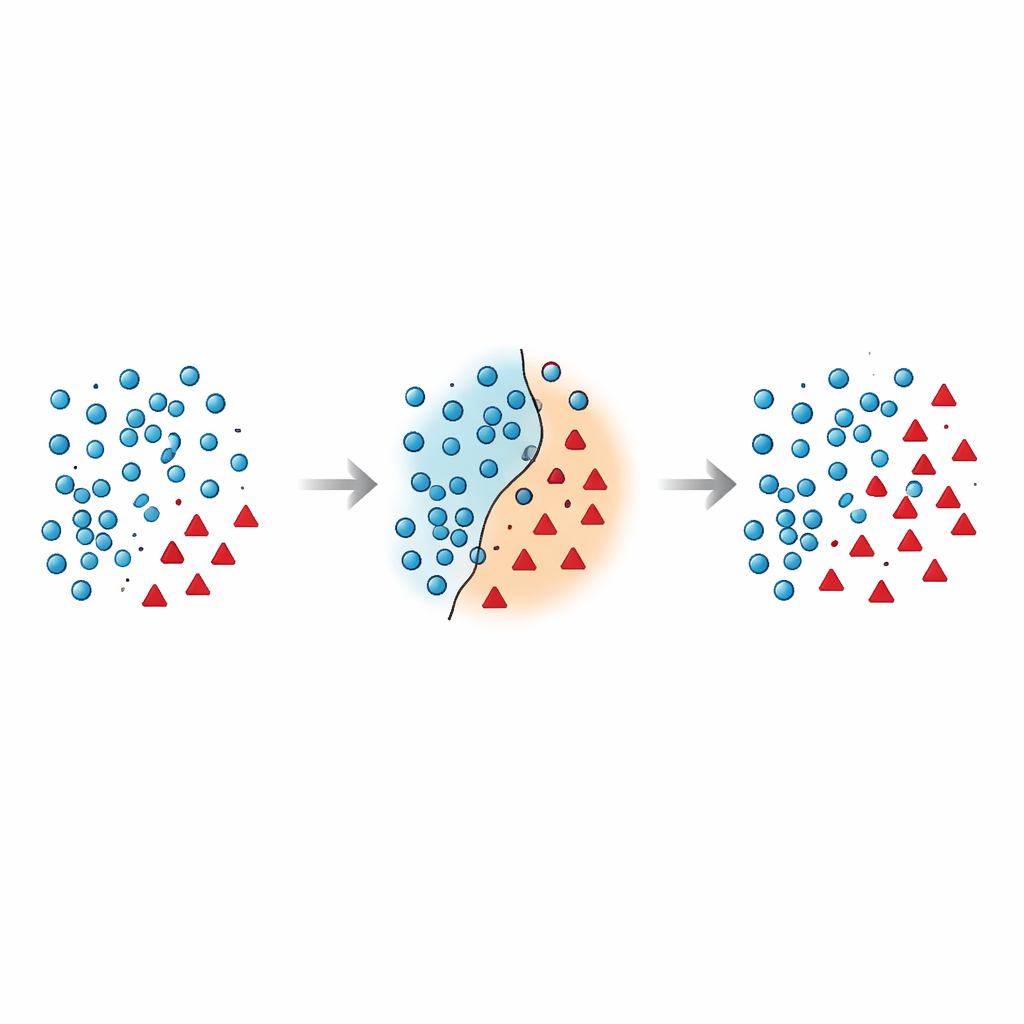
Por que a fronteira entre grupos é tão frágil
Os autores argumentam que os erros mais perigosos ocorrem perto da fronteira de decisão — a zona onde casos da maioria e da minoria se sobrepõem no espaço de atributos. Muitas técnicas existentes adicionam pontos sintéticos nessa região arriscada sem limpá‑la, ou eliminam dados de forma agressiva e acabam removendo exemplos informativos. Pesquisas recentes tentaram domar isso usando restrições geométricas, estimativas de densidade local ou filtros de ruído, porém a maioria dos métodos ainda trata os pontos da minoria in situ e raramente repensa como os pontos da maioria próximos àquela fronteira deveriam ser manejados. Isso deixa um problema persistente: amostras sobrepostas e ruidosas que confundem o classificador e levam a previsões instáveis, especialmente em dados novos.
Uma maneira em duas etapas de organizar a fronteira
O artigo apresenta o Borderline Shifting Oversampling (BSO), um método de remodelagem de dados em duas fases que mira explicitamente essa região problemática da fronteira. Primeiro, ele examina a vizinhança de cada exemplo da maioria para decidir se ele está em uma zona segura, na fronteira ou em um local claramente errado (ruído). Pontos da maioria cercados por vizinhos da minoria são ou reclassificados para o lado da minoria ou marcados como ruído e removidos, limpando e deslocando efetivamente a fronteira para que reflita melhor o padrão subjacente. Na segunda fase, o método gera novos pontos sintéticos da minoria usando uma interpolação semelhante ao SMOTE, mas apenas ao redor de amostras minoritárias próximas à fronteira refinada. Ao concentrar novos dados onde são mais informativos e evitar pontos claramente ruidosos, o BSO constrói um conjunto de treinamento que é tanto mais equilibrado em tamanho quanto mais limpo em estrutura.
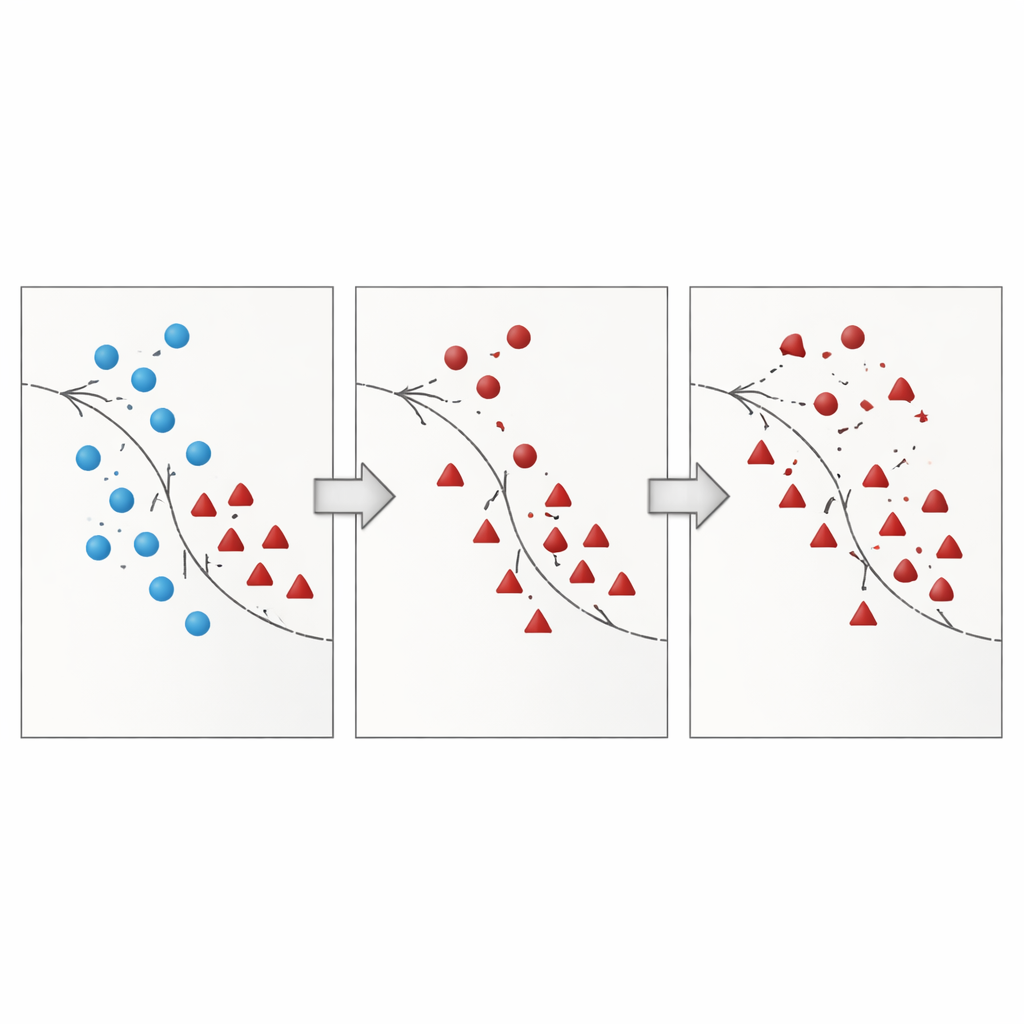
Colocando o método à prova
Para avaliar a eficácia na prática, os pesquisadores testaram o BSO em 30 conjuntos de dados de referência com diferentes graus de desbalanceamento e sobreposição. Compararam‑no com sete alternativas amplamente usadas, incluindo oversampling e undersampling aleatórios, SMOTE, Borderline‑SMOTE, NearMiss e dois métodos híbridos que misturam oversampling com limpeza de ruído (SMOTE‑Tomek e SMOTE‑ENN). Três classificadores comuns — máquinas de vetores de suporte (SVM), Naïve Bayes e Random Forests — foram treinados em cada conjunto de dados reamostrado. Em vez de confiar na acurácia bruta, o estudo utilizou métricas mais informativas em cenários de desbalanceamento, como F1‑score, G‑mean, recall, precisão e a Área sob a Curva ROC (AUC). Em quase todos os conjuntos de dados e classificadores, o BSO entregou pontuações maiores ou comparáveis, mostrando menor variação — ou seja, seus benefícios foram consistentes e não atrelados a um modelo ou configuração específica.
O que isso significa para decisões do mundo real
Em termos práticos, a abordagem Borderline Shifting atua como um editor cuidadoso para dados confusos: limpa exemplos ambíguos perto da linha divisória entre classes e então adiciona apenas casos minoritários realistas e no local certo. O resultado é que algoritmos de aprendizado ficam melhores em reconhecer eventos raros, porém importantes, sem serem enganados por sobreposições ruidosas. Para aplicações como detecção de fraude, previsão de acidentes ou triagem médica — onde perder um caso minoritário pode ser custoso — este método oferece uma maneira prática de tornar modelos mais justos, sensíveis e confiáveis, com sobrecarga computacional apenas moderada.
Citação: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Palavras-chave: desbalanceamento de classes, sobreamostragem, limite de decisão, detecção de anomalias, robustez em aprendizado de máquina