Clear Sky Science · pt
Um método para compilar objetos geográficos em mapas de imagens de satélite com base em dados de mapas vetoriais via aprendizado profundo
Por que alterar o que os mapas mostram é importante
Mapas online frequentemente parecem janelas para o mundo real, mas o que se vê do alto é cuidadosamente projetado. Mapas de imagens de satélite são valorizados porque parecem lugares reais; ainda assim, às vezes precisamos ocultar instalações sensíveis, limpar cenas muito poluídas ou garantir que diferentes tipos de mapas concordem entre si. Este artigo apresenta uma nova forma de "editar" automaticamente imagens de satélite usando inteligência artificial, de modo que edifícios e vias possam ser removidos, adicionados, deslocados ou remodelados enquanto a imagem continua natural e convincente. 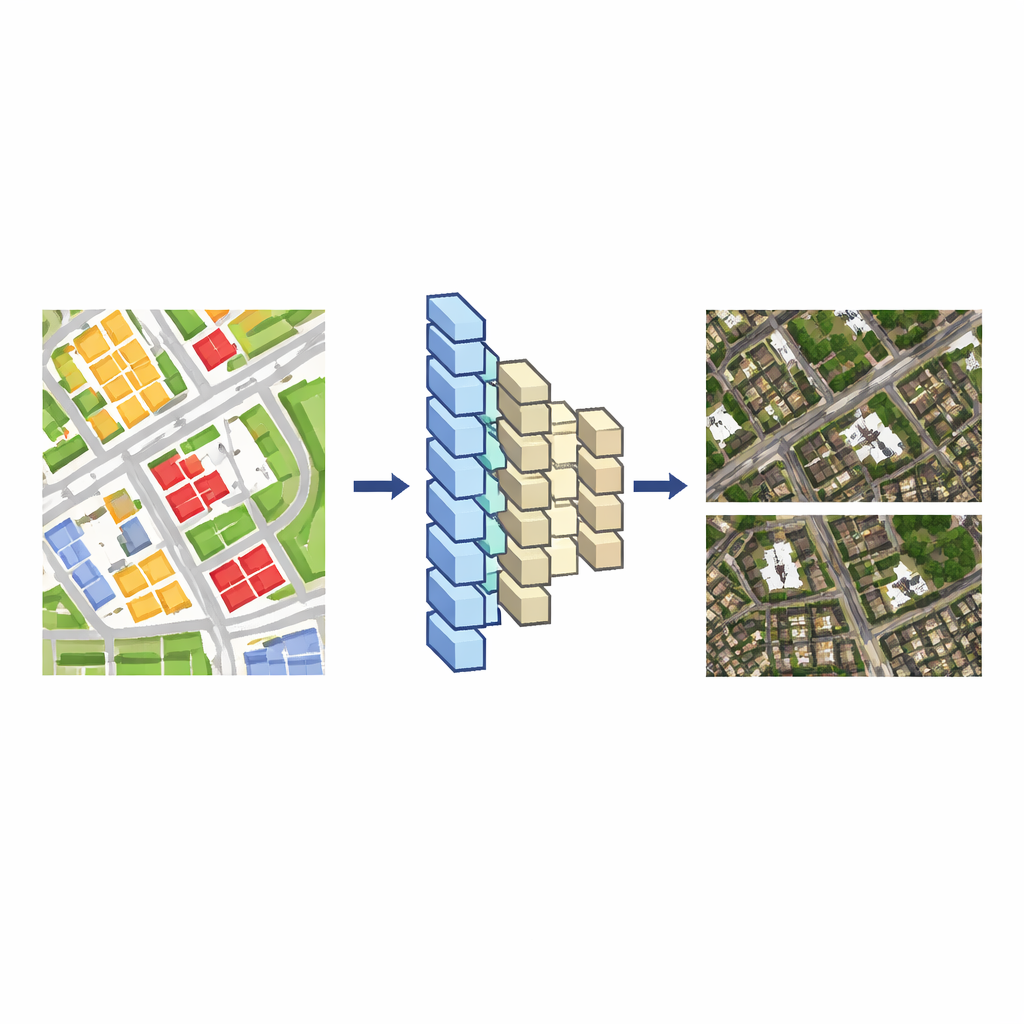
De desenhos simples a vistas realistas
Sistemas de mapas modernos costumam conter dois tipos de dados geográficos. Um é a própria imagem de satélite, um mosaico denso de pixels. O outro é um mapa vetorial, um desenho mais limpo feito de linhas e formas que marcam ruas, edifícios, rios e mais. Editar o mapa vetorial é relativamente simples, mas alterar manualmente a imagem de satélite correspondente é lento e trabalhoso, porque os pixels de cada edifício se misturam com sombras, árvores e estruturas próximas. A ideia central dos autores é ensinar um modelo de aprendizado profundo a traduzir esses desenhos vetoriais em imagens de satélite realistas. Uma vez que o modelo aprende essa ligação, qualquer alteração feita no mapa vetorial pode ser automaticamente convertida em uma mudança consistente na vista de satélite.
Ensinando uma IA a imaginar cidades
Para construir esse tradutor, os pesquisadores começam com áreas onde o mapa vetorial e a imagem de satélite cobrem a mesma região em escala similar. Eles recortam ambos em muitos pequenos blocos (tiles), emparelhando cada tile vetorial com seu tile de imagem correspondente, e usam esses pares como dados de treinamento. Uma rede neural encoder–decoder — semelhante a ferramentas usadas para tradução de imagem para imagem — aprende como o arranjo de blocos coloridos e linhas no tile vetorial se relaciona com telhados, ruas e vegetação no tile de satélite. Eles comparam dois desenhos de redes populares, UNet++ e Pix2Pix, e constataram que o Pix2Pix produz imagens com aparência de satélite que combinam mais de perto com a realidade e treina de forma confiável, então ele se torna o modelo base.
Focalizando o modelo nos locais a modificar
Aprender apenas com a cidade inteira não é suficiente quando se quer ajustar objetos específicos com limpeza. Para aguçar a habilidade do modelo em torno de áreas-alvo, os autores usam aprendizado por transferência. Eles extraem tiles de treinamento adicionais que cercam os edifícios ou vias que planejam editar e realizam uma curta fase adicional de treinamento usando apenas esses exemplos locais. Essa etapa de ajuste fino melhora muito a capacidade do modelo de reproduzir esses bairros, fazendo com que edições posteriores pareçam mais nítidas e precisas. 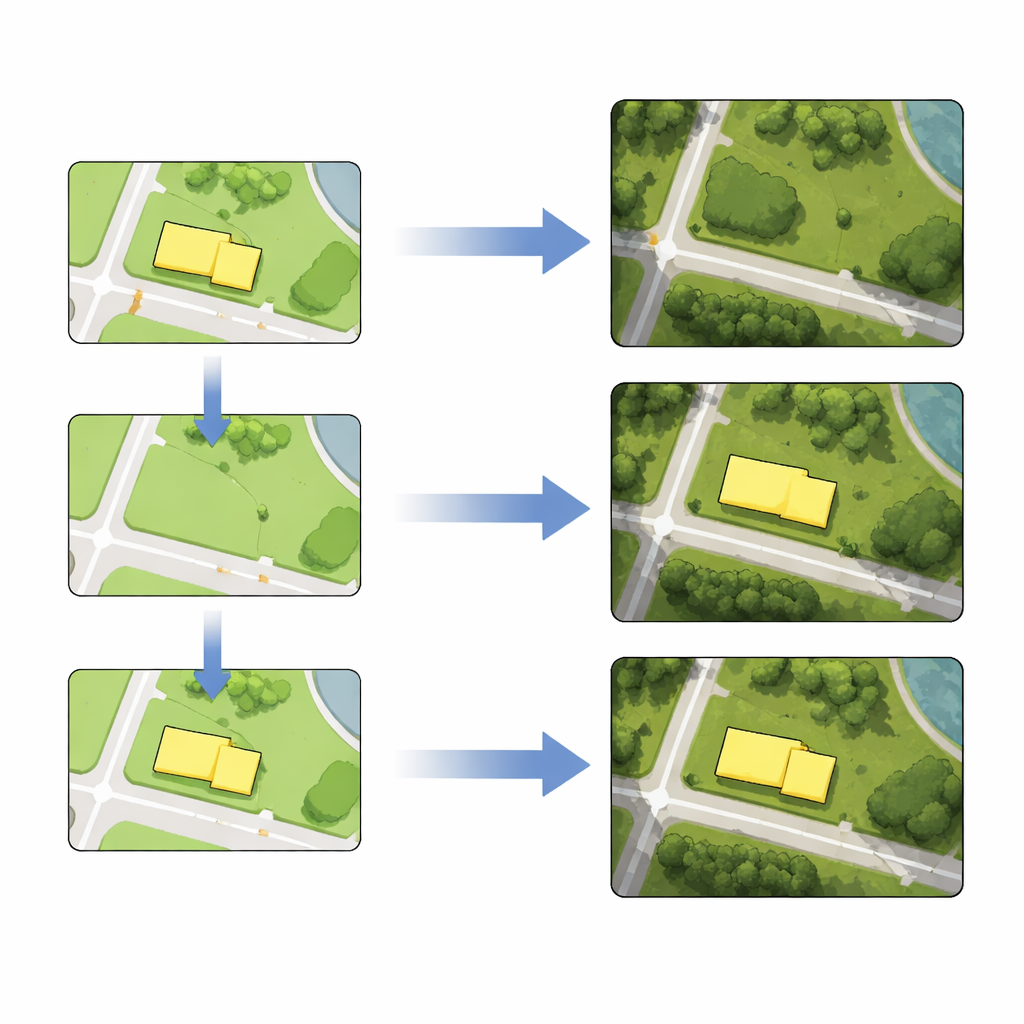
Editando edifícios e vias como camadas de mapa
Com o modelo ajustado em funcionamento, compilar mapas de imagens de satélite torna-se uma receita em três etapas. Primeiro, um cartógrafo edita o mapa vetorial: exclui um edifício, desenha uma nova rua, remodela um quarteirão ou move um objeto para outra posição. Segundo, os tiles editados do mapa vetorial são alimentados na rede treinada, que gera novos tiles de satélite que refletem a mudança pretendida mantendo os detalhes e texturas ao redor. Terceiro, esses tiles gerados substituem os tiles de imagem originais. Usando dados reais de Berlim, os autores demonstram as quatro operações — exclusão, inserção, distorção e deslocamento — tanto para contornos de edifícios quanto para linhas de vias, individualmente ou em lotes. As medições mostram que as posições dos objetos editados nas imagens geradas diferem de suas contrapartes vetoriais por apenas alguns pixels, uma precisão aceitável para muitas tarefas cartográficas.
O que isso significa para mapas futuros
Em termos diretos, o estudo mostra que, uma vez que uma IA aprendeu como mapas vetoriais e imagens de satélite correspondem, você pode editar o desenho simples e deixar o modelo repintar uma vista aérea crível para corresponder. Isso abre a porta para mapas de imagens de satélite que podem ser adaptados: ocultar locais sensíveis, esclarecer cenas complexas ou misturar espaços reais e imaginados, como mundos de jogos e ambientes virtuais. Ao mesmo tempo, ressalta o poder — e o risco — da geografia "deepfake", onde imagens aéreas com aparência realista podem deixar de ser fotografias diretas do mundo como ele é.
Citação: Du, J., Zeng, D., Cai, K. et al. A method for compiling satellite image map geographic objects based on vector map data via deep learning. Sci Rep 16, 9295 (2026). https://doi.org/10.1038/s41598-026-39096-0
Palavras-chave: imagens de satélite, aprendizado profundo, edição de mapas, sensoriamento remoto, cartografia deepfake